零基础入门深度学习(二):用一个案例掌握深度学习方法

授课讲师 | 毕然 百度深度学习技术平台部主任架构师
授课时间 | 每周二、周四晚20:00-21:00
编辑整理 | 刘威威
内容来源 | 百度飞桨深度学习集训营
0
导读
本课程是百度官方开设的零基础入门深度学习课程,主要面向没有深度学习技术基础或者基础薄弱的同学,帮助大家在深度学习领域实现从0到1+的跨越。从本课程中,你将学习到:
深度学习基础知识
numpy实现神经网络构建和梯度下降算法
计算机视觉领域主要方向的原理、实践
自然语言处理领域主要方向的原理、实践
个性化推荐算法的原理、实践
本周为开讲第二周,百度深度学习技术平台部主任架构师毕然老师,继续开始零基础入门深度学习的授课。
毕老师发现,在实际工业实践中,面对新问题套用已有方案通常不会取得好效果,需要从初步建模的baseline出发,在建模的每个步骤寻求优化思路。本次课程即以此做演示,将适用于房价预测任务的线性回归模型,挪用到手写数字识别任务后,如何一步步的进行优化,实现最好的分类效果,让学员可以获得工业实践的真实体验。基于此,毕老师为大家精心准备了由浅入深,由点及面的教学课程。
本次讲课内容主要包括:
数据处理和异步数据读取
网络结构设计及背后思想
损失函数介绍及使用方式
模型优化算法介绍和选择
分布式训练方法及实践
模型训练调试与优化
训练中断后恢复训练
下图概括了本次课程的主要授课知识点,课程内容涵盖深度学习的数据处理、模型设计、模型训练、模型优化等部分,另外扩展了异步数据读取,分布式训练、恢复训练等知识点。
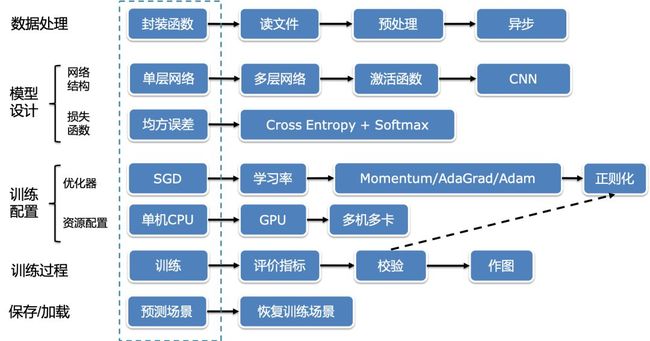
图:本次课程授课知识框架
本文总结了毕然老师的讲课要点,不免疏漏一些生动的讲课案例,感兴趣的同学可从文末链接中直接观看课程。
01
第一节:数据处理与数据读取
深度学习算法工程师多被称为“炼丹师”,训练深度学习模型则等同于“炼丹”。殊不知,在炼丹之前,重要的一步就是“采药”。采药是炼丹的第一步,同训练深度模型需要准备训练数据。
官方给出的数据集比如ImageNet,MSCOCO,VOC等,这些数据都比较干净,没有标注错误或者漏标注的问题。但是如果是自己的业务数据集,数据可能存在各种问题,需要自己去实现数据处理的函数,构建数据读取器。
在本节课程中,毕老师以本地读取的mnist数据集为例,顺序讲解并用代码实现了:
从文件中读取到数据;
划分数据集为训练集,验证集;
构建数据读取器(data_loader)

图:mnist数据处理
不同的数据保存的文件格式和存储形式不尽相同,正确读到数据往往是开始训练的第一步。课程案例中,本地存储的mnist数据是压缩后的json文件,毕老师用简洁的代码,不仅为学员介绍了读取数据、校验数据正确性、数据划分和使用yield构建数据读取器等知识,还介绍了使用飞桨实现数据的异步读取,在读取数据较慢,数据处理复杂时更为适用。
02
第二节:神经网络模型设计
第二节里,毕老师讲解了深度神经网络的设计原理,并分别实现了基于卷积神经网络和全连接神经网络的深度网络模型。
主要内容如下:
深度神经网络的设计原理。深度神经网络相比较浅层深度神经网络的区别是:网络足够深,足够复杂,非线性程度更高。前面的课程介绍到,复杂的模型可以拟合更复杂的函数,对现实世界的表征能力也会增强。非线性程度的增加通过模型的深度和非线性函数来实现,如果没有非线性函数,即使最深的神经网络也只不过是一种线性函数表达。组建网络时,一般考虑到训练数据的数量,决定设计模型的复杂度,如果训练数据不足,很难把一个参数众多的模型训练好。
如何设计深度神经网络。神经网络的基本层不外乎全连接层FC,卷积层CNN,循环神经网络RNN。不同的网络层有不同的适应任务,比如,CNN适合处理2D图像数据,CNN能更好的捕捉到空间位置信息,这是FC和LSTM顾及不到的,但是LSTM和FC也有其应用的场景。在本次的手写字符识别中,分别实现了基于FC和CNN的深度神经网络,通过对比实现,学员可以很轻松的学会如何使用卷积和全连接层构建深度网络。
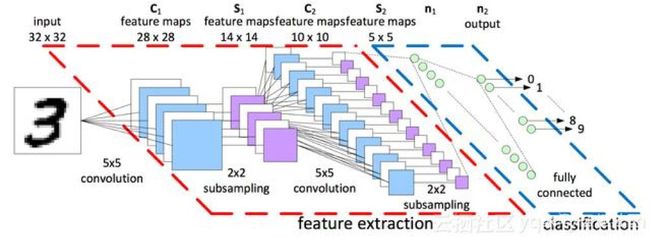
图:卷积网络模型示意图
03
第三节:损失函数介绍
完成神经网络设计后,毕老师首先以房价预测和手写字符识别的损失函数对比,通过比较这两个不同任务损失函数在量纲和优化目标的区别,引出了回归损失函数和分类损失函数的不同,进一步讲解了在不同任务下该如何选择、改进损失函数。
通过演示在mnist分类任务上使用均方误差损失函数,得出了两个结论:
回归任务的损失函数难以在分类任务上取得较好精度。
loss值较大,训练过程中loss波动明显。
所以,这里引出一个疑问?为什么分类任务用均方误差为何不合适?毕老师在课程中给出了两个答案:
物理含义不合理:实数输出和标签相减
分类任务本质规律是“在某种特征组合下的分类概率!“
分类任务背后是概率的思想,所以接着,毕老师利用从黑盒中取黑白球的概率为例,解释了最大似然的思想,
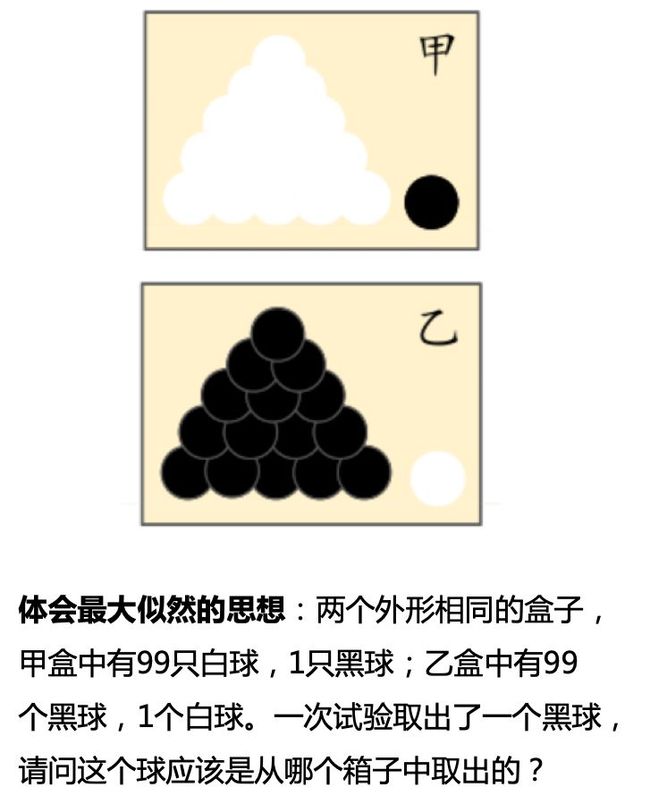
图:抽取黑白球到最大似然概率
最后以贝叶斯公式、交叉熵损失函数的公式介绍、以及代码实现收尾,结束了损失函数部分的课程内容。
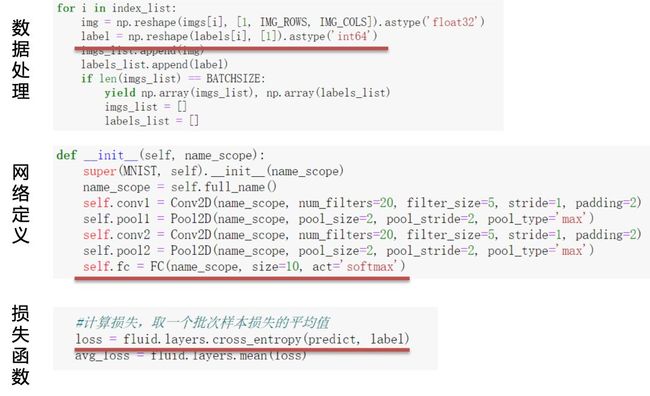
图:损失函数代码实现
04
第四节:优化算法与学习率
神经网络所拟合的函数是高度非凸函数,理想的训练目标是,优化这类函数,达到函数最小值点或接近最小值的极小值点。本部分课程中,毕老师带代价讨论优化器和学习率对训练神经网络的影响,并教大家如何选取最优的学习率和优化器。
学习率的选择
在深度学习神经网络模型中,学习率代表更新参数的更新幅度的大小。当学习率最优时,模型的有效容量最大。学习率设置和当前深度学习任务有关,合适的学习率往往需要调参经验和大量的实验,总结来说,学习率选取需要注意以下两点:
学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛。
学习率不是越大越好。因为只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。同时,在接近最优解时,过大的学习率会导致参数在最优解附近震荡,导致损失难以收敛。
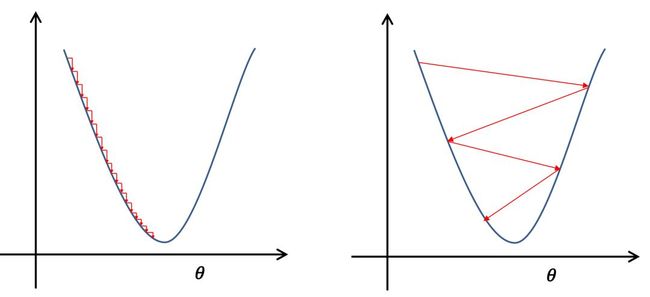
图: 不同大小学习率对到达最小值的影响
优化器的选择
学习率是优化器的一个参数,虽然参数更新都是采用梯度下降算法,但是不同的梯度下降算法影响着神经网络的收敛效果。当随机梯度下降算法SGD无法满足我们的需求时,可以尝试如下三个思路选取优化器。
加入“动量”,参数更新的方向更稳定,比如Momentum优化器。每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡!即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。类似不同品牌和材质的篮球有一定的重量差别,街头篮球队中的投手(擅长中远距离投篮)喜欢稍重篮球的比例较高。一个很重要的原因是,重的篮球惯性大,更不容易受到手势的小幅变形或风吹的影响。
根据不同参数距离最优解的远近,动态调整学习率,比如AdaGrad优化器。通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。
因为上述两个优化思路是正交的,所以可以将两个思路结合起来,这就是当前广泛应用的Adam算法。
05
第五节:模型训练及分布式训练
在前几次课程中,毕老师已经或多或少介绍了如何训练神经网络。但并没有涉及分布式训练的内容,本部分课程中,毕老师给大家介绍了分布式训练的思想,尤其是数据并行的思想,并介绍如何增加三行代码使用飞桨实现多GPU训练。
分布式训练有两种实现模式:模型并行和数据并行。
模型并行
模型并行是将一个网络模型拆分为多份,拆分后的模型分到多个设备上(GPU)训练,每个设备的训练数据是相同的。模型并行的方式一般适用于:
模型架构过大,完整的模型无法放入单个GPU。2012年ImageNet大赛的冠军模型AlexNet是模型并行的典型案例。由于当时GPU内存较小,单个GPU不足以承担AlexNet。研究者将AlexNet拆分为两部分放到两个GPU上并行训练。
网络模型的设计结构可以并行化时,采用模型并行的方式。例如在计算机视觉目标检测任务中,一些模型(YOLO9000)的边界框回归和类别预测是独立的,可以将独立的部分分在不同的设备节点上完成分布式训练。
说明:当前GPU硬件技术快速发展,深度学习使用的主流GPU的内存已经足以满足大多数的网络模型需求,所以大多数情况下使用数据并行的方式。
数据并行
数据并行与模型并行不同,数据并行每次读取多份数据,读取到的数据输入给多个设备(GPU)上的模型,每个设备上的模型是完全相同的。数据并行的方式与众人拾柴火焰高的道理类似,如果把训练数据比喻为砖头,把一个设备(GPU)比喻为一个人,那单GPU训练就是一个人在搬砖,多GPU训练就是多个人同时搬砖,每次搬砖的数量倍数增加,效率呈倍数提升。但是注意到,每个设备的模型是完全相同的,但是输入数据不同,每个设备的模型计算出的梯度是不同的,如果每个设备的梯度更新当前设备的模型就会导致下次训练时,每个模型的参数都不同了,所以我们还需要一个梯度同步机制,保证每个设备的梯度是完全相同的。
数据并行中有一个参数管理服务器(parameter server)收集来自每个设备的梯度更新信息,并计算出一个全局的梯度更新。当参数管理服务器收到来自训练设备的梯度更新请求时,统一更新模型的梯度。
用户只需要对程序进行简单修改,即可实现在多GPU上并行训练。飞桨采用数据并行的实现方式,在训练前,需要配置如下参数:
1.从环境变量获取设备的ID,并指定给CUDAPlace
device_id = fluid.dygraph.parallel.Env().dev_id place = fluid.CUDAPlace(device_id)
2.对定义的网络做预处理,设置为并行模式
strategy = fluid.dygraph.parallel.prepare_context() ## 新增 model = MNIST("mnist") model = fluid.dygraph.parallel.DataParallel(model, strategy) ## 新增
3.定义多GPU训练的reader,将每批次的数据平分到每个GPU上
valid_loader = paddle.batch(paddle.dataset.mnist.test(), batch_size=16, drop_last=true) valid_loader = fluid.contrib.reader.distributed_batch_reader(valid_loader)
4.收集每批次训练数据的loss,并聚合参数的梯度
avg_loss = mnist.scale_loss(avg_loss) ## 新增 avg_loss.backward() mnist.apply_collective_grads() ## 新增
如果想了解飞桨数据并行的基本思想,可以参考官网文档-https://www.paddlepaddle.org.cn/documentation/docs/zh/user_guides/howto/training/cluster_howto.html。
06
第六节:训练调试与优化
在模型训练部分,为了保证模型的真实效果,需要对模型进行一些调试和优化,毕老师在课程中把训练调试优化分五个环节来讲:
计算分类准确率,观测模型训练效果。
交叉熵损失函数只能作为优化目标,无法直接准确衡量模型的训练效果。准确率可以直接衡量训练效果,但由于其离散性质,不适合做为损失函数优化神经网络。
检查模型训练过程,识别潜在问题。
如果模型的损失或者评估指标表现异常,我们通常需要打印模型每一层的输入和输出来定位问题,分析每一层的内容来获取错误的原因。
加入校验或测试,更好评价模型效果。
理想的模型训练结果是在训练集和验证集上均有较高的准确率,如果训练集上的准确率高于验证集,说明网络训练程度不够;如果验证集的准确率高于训练集,可能是发生了 过拟合现象。通过在优化目标中加入正则化项的办法,可以解决过拟合的问题。
加入正则化项,避免模型过拟合。
可视化分析。
用户不仅可以通过打印或使用matplotlib库作图,飞桨还集成了更专业的第三方绘图库tb-paddle,提供便捷的可视化分析。
07
第七节:恢复训练
在快速入门中,我们已经介绍了将训练好的模型保存到磁盘文件的方法。应用程序可以随时加载模型,完成预测任务。但是在日常训练工作中我们会遇到一些突发情况,导致训练过程主动或被动的中断。如果训练一个模型需要花费几天的训练时间,中断后从初始状态重新训练是不可接受的。
万幸的是,飞桨支持从上一次保存状态继续训练,只要我们随时保存训练过程中的模型状态,就不用从初始状态重新训练。保存模型的代码如下:
# 保存模型参数和优化器的参数 fluid.save_dygraph(model.state_dict(), './checkpoint/mnist_epoch{}'.format(epoch_id)) fluid.save_dygraph(optimizer.state_dict(), './checkpoint/mnist_epoch{}'.format(epoch_id))
训练不仅保存模型参数,而且保存优化器、学习率有关的参数,比如Adam, Adagrad优化器在训练时会创建一些新的变量辅助训练;动态变化的学习率需要保存训练停止时的训练步数。这些参数对于恢复训练至关重要。
恢复训练只需要恢复保存的模型和优化器相关参数即可。
# 加载模型参数到模型中 params_dict, opt_dict = fluid.load_dygraph(params_path) model = MNIST("mnist") model.load_dict(params_dict)
# 使用Adam优化器,并加载保存的Adam优化器相关参数 optimizer = fluid.optimizer.AdamOptimizer(learning_rate=lr) optimizer.set_dict(opt_dict)
总结
本次课程内容丰富,毕老师通过一个案例讲解了深度学习的一般方法,全方面涵盖了数据处理,模型设计,训练配置,分布式训练,训练优化与调试,恢复训练等。以一个简单的例子帮助学员们掌握了深度学习方法,真正实现了从0到1+的跨越。在后期课程中,将继续为大家带来内容更丰富的课程,帮助学员快速掌握深度学习方法。
【如何学习】
1. 如何观看配套视频?如何代码实践?
视频+代码已经发布在AI Studio实践平台上,视频支持PC端/手机端同步观看,也鼓励大家亲手体验运行代码哦。扫码或者打开以下链接:
https://aistudio.baidu.com/aistudio/course/introduce/888

2. 学习过程中,有疑问怎么办?
加入深度学习集训营QQ群:726887660,班主任与飞桨研发会在群里进行答疑与学习资料发放。
3. 如何学习更多内容?
百度飞桨将通过飞桨深度学习集训营的形式,继续更新《零基础入门深度学习》课程,由百度深度学习高级研发工程师亲自授课,每周二、每周四8:00-9:00不见不散,采用直播+录播+实践+答疑的形式,欢迎关注~
请搜索AI Studio,点击课程-百度架构师手把手教深度学习,或者点击文末「阅读原文」收看。
