模式识别与机器学习简单知识点
模式识别与机器学习简单知识点
什么是模式
• 广义地说,存在于时间和空间中可观察的物体,如果我们可以区别它们是否相同或是否相似,都可以称之为模式。
模式所指的不是事物本身,而是从事物获得的信息,因此,模式往往表现为具有时间和空间分布的信息。
• 模式的直观特性:
– 可观察性
– 可区分性
– 相似性
• 机器学习的目标:针对某类任务T,用P衡量性能,根据经验来学习和自我完善,提高性能。
• 模式识别系统的目标:在特征空间和解释空间之间找到一种映射关系,这种映射也称之为假说。
主要分类和学习方法
• 数据聚类
目标:用某种相似性度量的方法将原始数据组织成有意义的和有用的各 种数据集。是一种非监督学习的方法,解决方案是数据驱动的。
• 统计分类
基于概率统计模型得到各类别的特征向量的分布,以取得分类的方法。
特征向量分布的获得是基于一个类别已知的训练样本集。是一种监督分类的方法,分类器是概念驱动的。
• 结构模式识别
该方法通过考虑识别对象的各部分之间的联系来达到识别分类的目的。识别采用结构匹配的形式,通过计算一个匹配程度值(matching score)来评估一个未知的对象或未知对象某些部分与某种典型模式的关系如何。
• 神经网络
神经网络是受人脑组织的生理学启发而创立的。由一系列互相联系的、相同的单元(神经元)组成。相互间的联系可以在不同的神经元之间传递增强或抑制信号。
增强或抑制是通过调整神经元相互间联系的权重系数来(weight)实现。神经网络可以实现监督和非监督学习条件下的分类。
• 监督学习
监督学习是从有标记的训练数据来推断或建立一个模型,并依此模型推测新的实例。
• 无监督学习
无监督学习是我们不告诉计算机怎么做,而是让它自己去学习怎样做一些事情。
无监督学习与监督学习的不同之处在于,事先没有任何训练样本,需要直接对数据进行建模,寻找数据的内在结构及规律,如类别和聚类。常用于聚类、概率密度估计。
• 半监督学习
半监督学习(Semi-supervised Learning)是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。
• 增强学习
增强学习要解决的问题:一个能够感知环境的自治机器人,怎样通过学习选择能达到其目标的最优动作。
机器人选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈回来。
• 集成学习
集成学习(Ensemble Learning)是机器学习中一类学习算法,指联合训练多个弱分类器并通过集成策略将弱分类器组合使用的方法。由于整合了多个分类器,这类算法通常在实践中会取得比单个若分类器更好的预测结果。
常见的集成策略有:Boosting、Bagging、 Random subspace 、Stacking等。
常见的算法主要有:决策树、随机森林、Adaboost、GBDT、DART等。
• 深度学习
深度学习的概念源于人工神经网络的研究,除输入层和输出层外,含多个隐藏层的神经网络就是一种深度学习结构。
深度学习通过层次化模型结构可从低层原始特征中逐渐抽象出高层次的语义特征,以发现复杂、灵活、高效的特征表示。
常见的深度学习模型有:卷积神经网络, 递归神经网络,深度信任网络,自编码器,变分自编码器等。
• 元学习
元学习(Meta Learning)或者叫做“学会学习”(Learning to Learn),它是要“学会如何学习”,即利用以往的知识经验来指导新任务的学习,具有学会学习的能力。
当前的机器学习模型往往只局限于从头训练已知任务并使用精调来学习新任务,耗时较长,且性能提升较为有限。
• 多任务学习
多任务学习是指通过共享相关任务之间的表征,联合训练多个学习任务的学习范式。
• 多标记学习
多标记学习问题为一种特殊的有监督分类问题,其所处理的数据集中的每个样本可同时存在多个真实类标。
多标记学习主要用于处理多种标签的语义重叠,如预测歌曲的音乐流派,预测图书、商品的属性标签。
• 对抗学习
对抗学习是针对传统机器学习的一种攻击性方法,是机器学习和计算机安全领域都十分关注的交叉问题。
对抗学习主要通过恶意输入来误导机器学习算法或模型使其得到错误结果,并在该过程中暴露机器学习算法存在的脆弱性,帮助设计适应复杂环境的鲁棒学习方法。
相关数学概念
数学期望、方差
随机变量X的数学期望(或称均值)记作E(X),它描述了随机变量的取值中心。随机变量( X - E(X) )2的数学期望称为X的方差,记作σ2,而σ称为X的均方差(标准差)。它们描述了随机变量的可能取值与均值的偏差的疏密程度。
1、若X是连续型随机变量,其分布密度为p(x),则(当积分绝对收敛时)
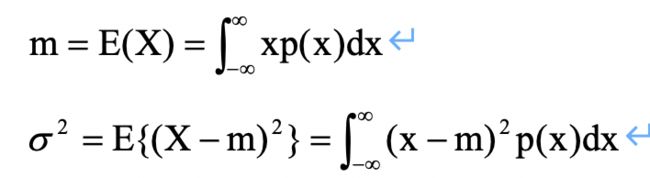
2、若X是离散型随机变量,其可能取值为xk,k=1,2,…,且P(X=xk) = pk,则(当级数是绝对收敛时)
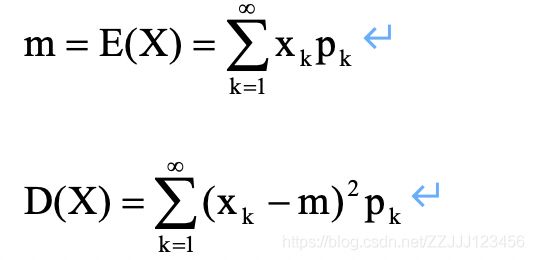
协方差矩阵
正太分布

