飞桨深度学习学院零基础深度学习7日入门-CV疫情特辑学习笔记(四)DAY03 车牌识别
本课分为理论和实战两个部分
理论:卷积神经网络
1.思考全连接神经网络的问题
一般来收机器学习模型实践分为三个步骤,(1)建立模型 (2)选择损失函数 (3)参数调整学习
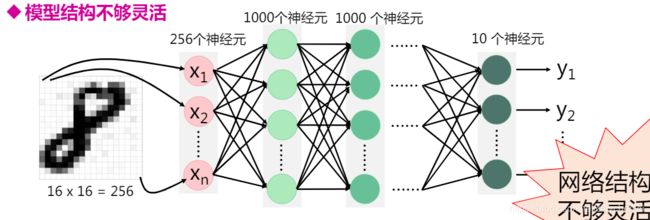
1.1 模型结构不够灵活
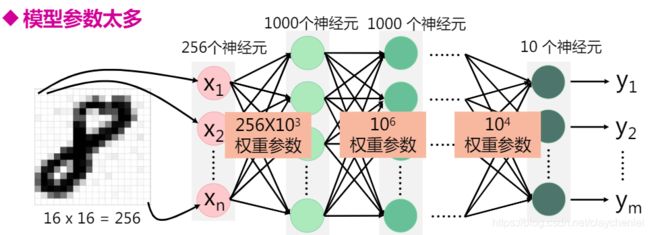
假设对16 x 16 的图片进行分类手写字体分类任务,设计了如上所示的网络。第输入层转换为一维向量是256个,那对100*100的图片做相同的任务,只有通过增加每层的神经元个数或者增加网络的层数来完成。1.2模型参数太多
例如:输入为16 x 16 的图片,输入层为256个神经元,隐藏层每层1000个神经元,输出层10个。假设共5层,则共需要学习(256*10^3+10^6+10^6+10^4 )个,w再加(1000+1000+1000+10)个b。这是十分大运算量。如果输入为100*100的图片或者更大的图片呢?如果网络的层数为十层呢?
2.如何改进?卷积神经网络
2.1 在第一步建立模型时候抛弃全连接神经网络,采用卷积神经网络。
建立模型:
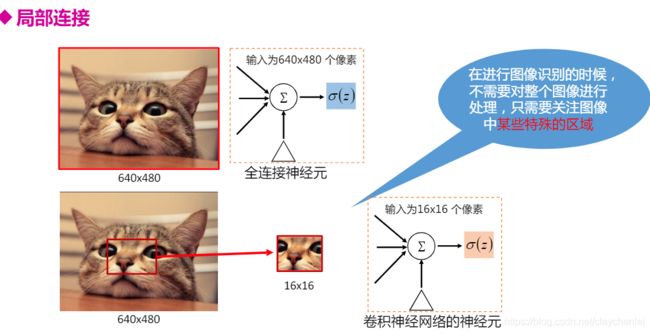
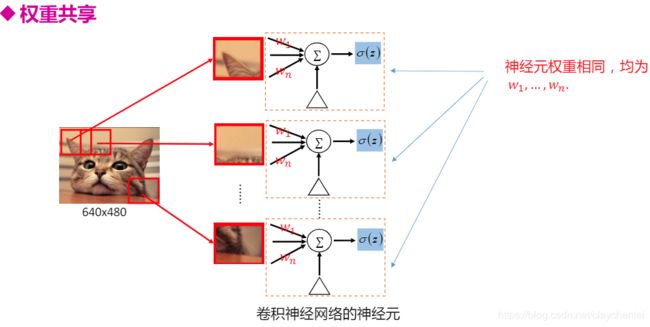
- 卷积神经网络(CNN) 三大特性:局部连接 权重共享 下采样减少网络参数;这些都可以加快训练速度
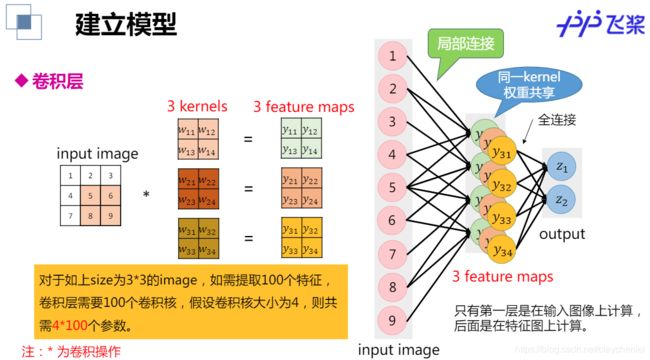
- 卷积层
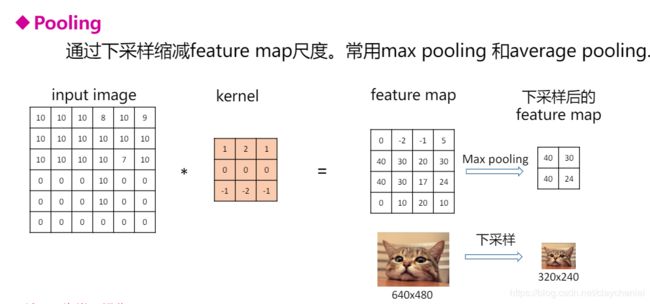
- Pooling层
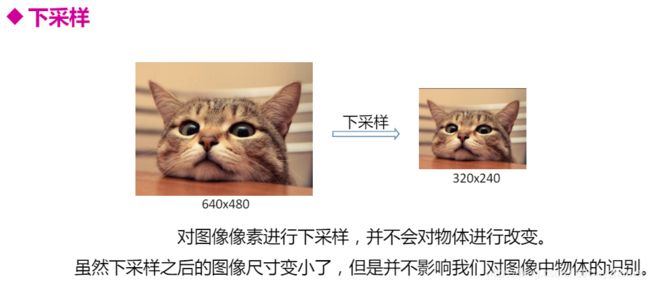
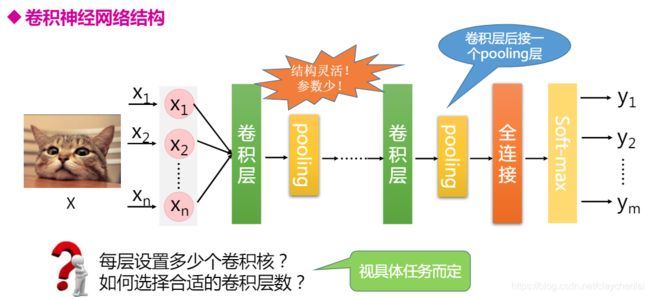
完成的卷积神经网络结构如下图:

卷积层:

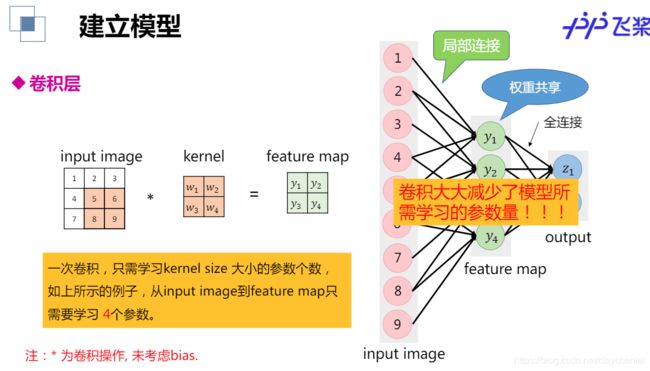
单个卷积核只能提取单一特征,如何利用卷积核提取更复杂的特征?
一个卷积核可以提取图像的一种特征,多个卷积核提取多种特征
POOLing 池化层
损失函数
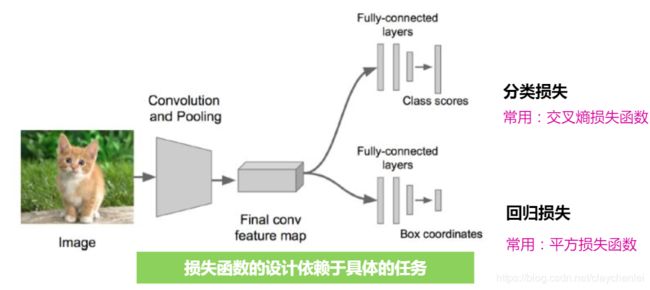
参数学习部分还是梯度下降方法。
实战:车牌识别
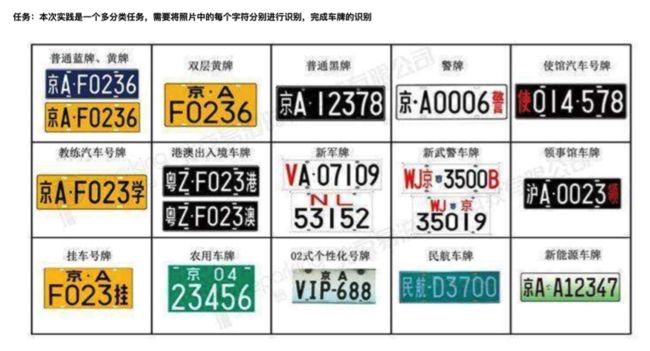
1. 直接在百度AI Studio中阅读案例代码,并运行,查看结果
跟上节课任务类似,区别在于 神经网络模型部分
#定义网络
class MyLeNet(fluid.dygraph.Layer):
def __init__(self):
super(MyLeNet,self).__init__()
self.hidden1_1 = Conv2D(1,28,5,1) #(通道数,卷积核个数,卷积核大小) featuremap (20-5+1) 变成 16* 16
self.hidden1_2 = Pool2D(pool_size=2,pool_type='max',pool_stride=1) #采用是取最大值,池化步长可以改 1
self.hidden2_1 = Conv2D(28,32,3,1) #(28,因为上一个卷积核28)
self.hidden2_2 = Pool2D(pool_size=2,pool_type='max',pool_stride=1)
self.hidden3 = Conv2D(32,32,3,1)
self.hidden4 = Linear(32*10*10,65,act='softmax') #转换为全连接层FC,便于分类输出,概率
def forward(self,input): #print x.shape 用于输出参数,辅助理解和观察,便于及时调整参数
x = self.hidden1_1(input)
print(x.shape)
x = self.hidden1_2(x)
x = self.hidden2_1(x)
x = self.hidden2_2(x)
x = self.hidden3(x)
x = fluid.layers.reshape(x,shape=[-1,32*10*10]) #转换为一维数组
y = self.hidden4(x)
return y
#迭代输出损失函数和精度大小
Iter=0
Iters=[]
all_train_loss=[]
all_train_accs=[]
def draw_train_process(iters,train_loss,train_accs):
title = "training loss/training accs"
plt.title(title,fontsize=24)
plt.xlabel("iter",fontsize=14)
plt.ylabel("loss/acc",fontsize=14)
plt.plot(iters,train_loss,color='red',label='training loss')
plt.plot(iters,train_accs,color='green',label='traning_accs')
plt.legend()
plt.grid()
plt.show()在训练部分主要是调整参数,优化模型,因为刚接触,没有太多深入了解,所以没有添加额外的神经网络处理方式如dropout,batch等。
with fluid.dygraph.guard():
model=MyLeNet() #模型实例化
model.train() #切换到训练模式,该模式下自动搭建反向传播网络,评估模式没有
opt=fluid.optimizer.SGDOptimizer(learning_rate=0.008, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
epochs_num=100 #迭代次数为2
#参数组合 0.001 100 0.94358677
# 0.005 100 0.97394913u
# 0.008 100 0.9805597
# 0.008 50 0.9481078
# 0.008 150 0.97946256
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(1,20,20) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)#预测
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度avg_acc: 0.9775549

2.由线上导出ipynb格式文件,导入到本地jupyterLab环境
本地导入文件后,修改对应的文件路径,安装cv2包,opencv
数据包导入本地解压后要正确的配置路径,以免找不到资源
data_path = 'data/characterData/data'
character_folders = os.listdir(data_path)
分别为不同项目建立文件夹,以免数据资源覆盖冲突,比如train_data.list,test_data.list
因为本项目使用到 是单通道图像,所以加载图像后不需要转置。
#昨天三通道图像处理函数
def data_mapper(sample):
img, label = sample
img = Image.open(img)
img = img.resize((100, 100), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) #转置
img = img/255.0
return img, label
#今天车牌处理图像
def data_mapper(sample):
img, label = sample
img = paddle.dataset.image.load_image(file=img, is_color=False)
img = img.flatten().astype('float32') / 255.0
return img, label
出现错误: 将中文文件名的图片换成英文即可,原因是OpenCV在Window下支持不好
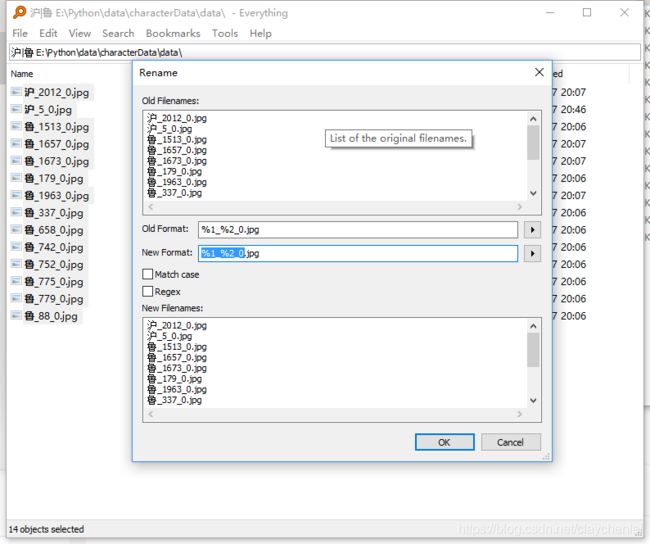
因为几乎每个文件夹都有含中文的图片,一个个实在费时间,所以用everything 高级搜索
批量重命名
Exception in thread Thread-15:
Traceback (most recent call last):
File "D:\Programs\Anaconda3\envs\paddle\lib\threading.py", line 926, in _bootstrap_inner
self.run()
File "D:\Programs\Anaconda3\envs\paddle\lib\threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "D:\Programs\Anaconda3\envs\paddle\lib\site-packages\paddle\reader\decorator.py", line 400, in handle_worker
r = mapper(sample)
File "", line 5, in data_mapper
img = img.flatten().astype('float32') / 255.0
AttributeError: 'NoneType' object has no attribute 'flatten'
3.进行部分参数调整,思考会有何变化,查看结果
卷积层的输出特征图如何当作全连接层的输入使用呢?卷积层的输出数据格式是,在输入全连接层的时候,会自动将数据拉平,也就是对每个样本,自动将其转化为长度为的向量,
TODO: 工作上事情太多,只来得及在线上调试好得出结果,本地错误未解决。以后要花时间好好理解相关的理论,并重做这个案例。
参考资料:
配套参考资料:1.百度深度学院课程课件 2.PaddlePaddle官方文档 3.其他网络资料(CSDN PaddlePaddle)
神经网络理解:https://blog.csdn.net/lzx159951/article/details/105254912/