模式识别经典算法——FCM图像聚类分割(最简matlab实现)
- 算法的规格
- 算法的记号及参数
- 记号
- 更新公式
- 算法的流程
- 数学语言与程序语言
- 算法的记号及参数
- 算法的实现matlab
- 客户端程序
- FCM函数
- 效果演示
- 敛散性分析
- 聚类分割效果图
- 避免出现局部极小值的方法
从kmeans各个样本所属类别 的非此即彼(要么是0要么是1,如果建立一个归属矩阵 N∗k ,每一行表示样本的归属情况,则会得到,其中一个entry是1,其他是0),到走向模糊(Fuzzy),走向不确定性(此时的归属(fuzzy membership)阵 P(μi|xj)i∈1,…k,j∈1,…N ,每个元素都会是[0-1]之间的概率值,行和要求为1)。无疑,基于模糊理论的 FCM 是站在了 kmeans 的肩膀上,这与其说是一种算法的改进,不如说是一种思想的进化。
算法的规格
算法的记号及参数
记号
- 隶属度函数 P(μi|xj) ,表征样本 xj 隶属类别(cluster) μi 的程度,即允许一个样本隶属于多个类别,只不过程度不同而已。
- 参数 b ,用来控制不同类别的混合程度的自由参数。当 b 取1时, FCM 聚类分割算法退化为普通的 kmeans
- 聚类中心(cluster centroids) μj ,同kmeans
- 距离的度量, dij=∥xj−μi∥2 ,同kmeans
- 目标函数 Jfuz=∑ci=1∑Nj=1P(μi|xj)bdij
更新公式
- 聚类中心更新公式
μi=∑Nj=1P(μi|xj)bxj∑Nj=1P(μi|xj)b
翻译过来就是新的聚类中心,在全部样本的属于该类别(编号)的加权平均。 - 隶属函数值更新公式
P(μi|xj)=(1/dij)1/(b−1)∑cr=1(1/drj)1/(b−1)
隶属度与距离成反比
算法的流程
- 初始化聚类个数 k 、 b ,以及 P(μi|xj),i=1,…,k;j=1,…,N
- 归一化 P(μi|xj)
- 循环(更新聚类中心以及隶属函数)并判断目标函数 Jfuz 是否变化足够小,以 F 范数为变化的度量、
- 退出循环,返回dist(各类别到各样本的距离矩阵)、最新的聚类中心,以及目标函数
数学语言与程序语言
- 初始并归一化隶属函数 P(μi|xj)
P = randn(N, k);
P = P./(sum(P, 2)*ones(1, k));- 聚类中心的更新
t = P.^b;
C = (X'*t)'./(sum(t)'*ones(1, p));- 各样本到各聚类中心的距离
dist = sum(X.*X, 2)*ones(1, k) + (sum(C.*C, 2)*ones(1, N))'-2*X*C';- 隶属函数 P(μi|xj) 的更新
t2 = (1./dist).^(1/(b-1));
P = t2./(sum(t2, 2)*ones(1, k));- 目标函数的计算
J_cur = sum(sum((P.^b).*dist))/N;算法的实现(matlab)
客户端程序
clear all; close all;
I = imread('./lena.bmp');
rng('default');
[m, n, p] = size(I);
X = reshape(double(I), m*n, p);
k = 5; b = 2;
[C, dist, J] = fcm(X, k, b);
[~, label] = min(dist, [], 2);
figure
imshow(uint8(reshape(C(label, :), m, n, p)))
figure
plot(1:length(J), J, 'r-*'), xlabel('#iterations'), ylabel('objective function')FCM函数
function [C, dist, J] = fcm(X, k, b)
iter = 0;
[N, p] = size(X);
P = randn(N, k);
P = P./(sum(P, 2)*ones(1, k));
J_prev = inf; J = [];
while true,
iter = iter + 1;
t = P.^b;
C = (X'*t)'./(sum(t)'*ones(1, p));
dist = sum(X.*X, 2)*ones(1, k) + (sum(C.*C, 2)*ones(1, N))'-2*X*C';
t2 = (1./dist).^(1/(b-1));
P = t2./(sum(t2, 2)*ones(1, k));
J_cur = sum(sum((P.^b).*dist))/N;
J = [J J_cur];
if norm(J_cur-J_prev, 'fro') < 1e-3,
break;
end
display(sprintf('#iteration: %03d, objective function: %f', iter, J_cur));
J_prev = J_cur;
end效果演示
敛散性分析
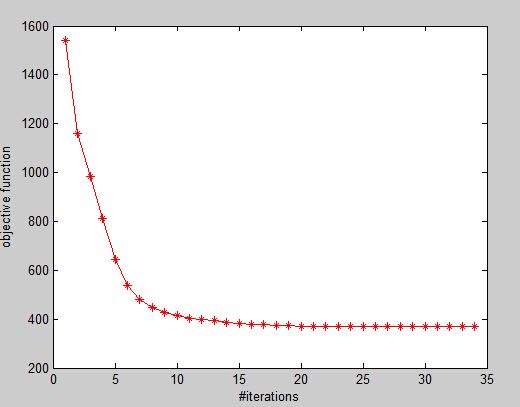
聚类分割效果图

避免出现局部极小值的方法
一个比较简单也易实现的方法(比较low),就是多做几次试验。
times = 15;
k = 5; b = 2;
[C_prev, dist_prev, J_prev] = fcm(X, k, b);
for i = 2:times,
[C_cur, dist_cur, J_cur] = fcm(X, k, b);
if (J_cur(end) < J_prev(end)),
J_prev = J_cur;
C_prev = C_cur;
dist_prev = dist_cur;
end
end
[~, label] = min(dist_prev, [], 2);
imshow(uint8(reshape(C_prev(label, :), m, n, p)), [])