flume ng高可用部署
一、flume简介
flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单的处理,并写到各类数据接受方(可定制)的能力。Flume1.x版本的统称为Flume-ng。
数据处理:
Flume提供了从console(控制台)、RPC(Thrift-RPC)、text、tail、syslog(syslog日志系统),支持TCP和UDP等2两种模式,exec(命令执行)等数据源上收集数据的能力。
Flume NG采用的是三层架构: Agent层,Collector层,和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和Sink,三者组建了一个Agent。三者的作用:
Source:用来消费(收集)数据源到Channel组件中。
Channel:中转临时存储,保存所有Source组件信息。
Sink:从Channel中读取,读取成功后会删除Channel中的信息。
二、单点FlumeNG搭建、运行。
这里我用的是Flume-1.6.0版本。
安装解压flume安装包,命令如下所示:
tar -zxvf apache-flume-1.6.0-bin.tar.gz 配置环境变量:

flume单节点配置文件设置如下:
flume-hdfs.conf
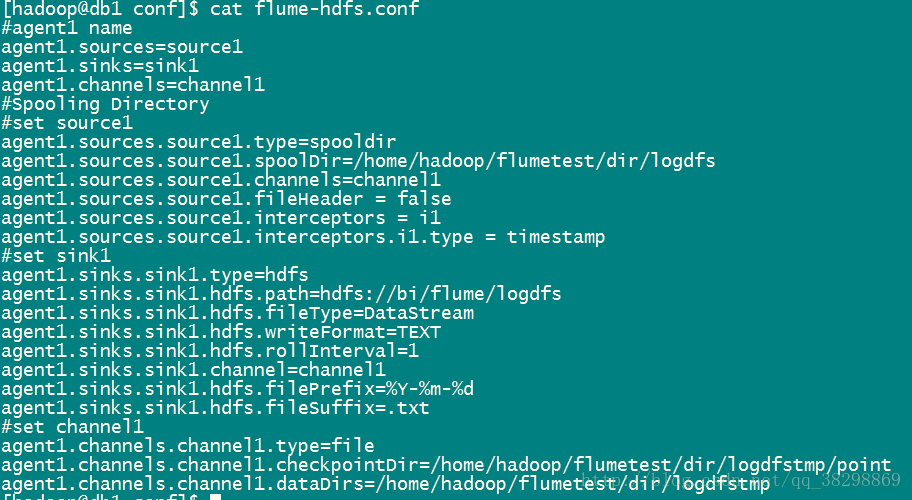
复制flume-env.sh
cp flume-env.sh.template flume-env.sh加入jdk配置:
export JAVA_HOME=/usr/local/jdk1.7.0_79注意: 配置中的目录需提前创建
运行:
启动命令如下:
flume-ng agent --conf conf --conf-file /home/hadoop/flume-1.6.0/conf/flume-hdfs.conf --name agent1 -Dflume.root.logger=INFO,console > /home/hadoop/flume-1.6.0/logs/flume-hdfs.log 2>&1 &注:命令中的agent1表示配置文件中的Agent的Name,flume-hdfs.conf要写准确的文件路径。
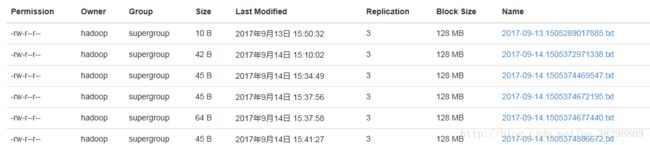
单节点flume效果预览:

hadoopweb页面可以查看已上传并重命名的文件:
三、高可用的Flume NG搭建
架构图:
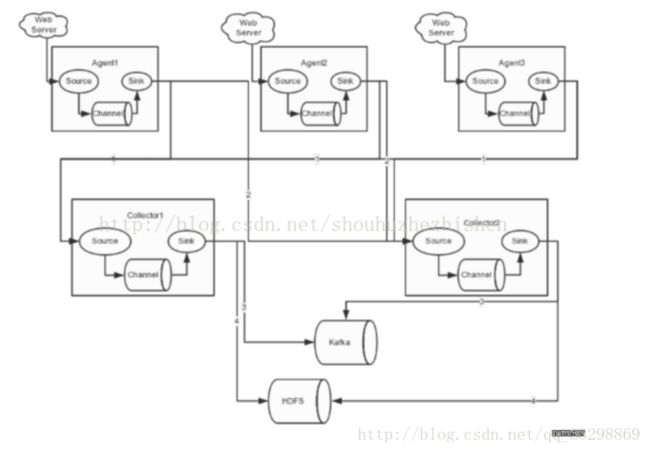
Flume的存储可以支持很多种,这里只列举了HDFS和Kafka。比如:存储一定时间的日志,并给Storm系统提供实时日志流。
3台机器构建集群。Flume的Agent和Collector分布如下:
名称 HOST 角色
Agent1 db1 Web Server
Agent2 db2 Web Server
Agent3 db3 Web Server
Collector1 db1 AgentMstr1
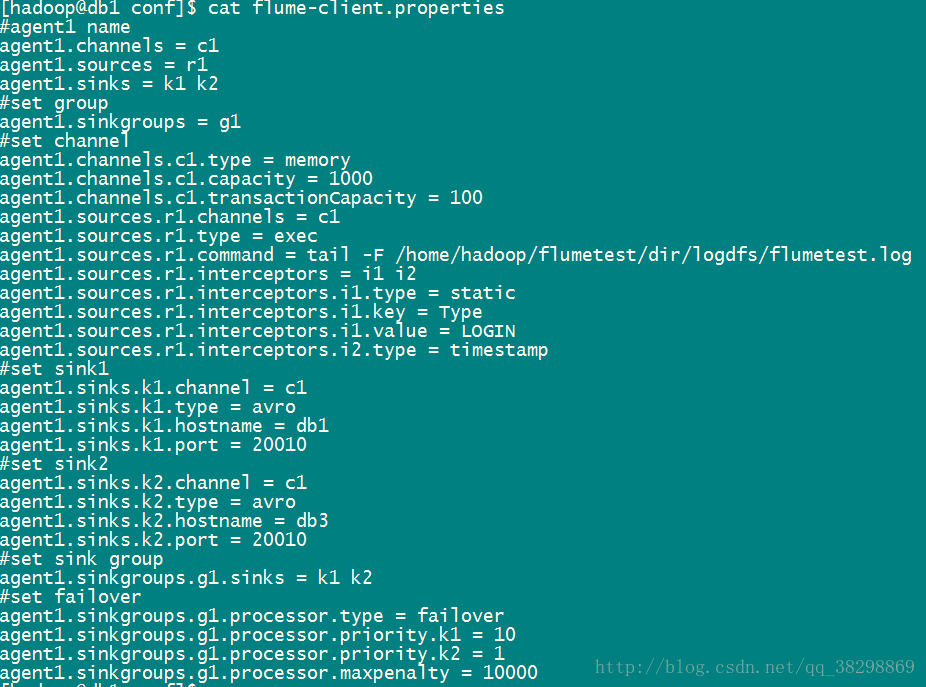
Collector2 db3 AgentMstr1Agent1、Agent2、Agent3,分别位于db1-db3三台机器上,配置相同,如下所示:
flume-client.properties
接下来再配置Collector1和Collector2,分别位于db1和db3两台机器,绑定IP的不同,
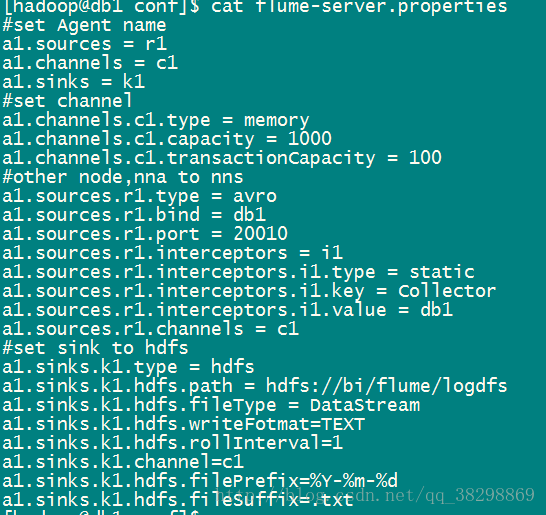
db1(master)flume-server.properties配置如下:
db3(slave)的配置如下:
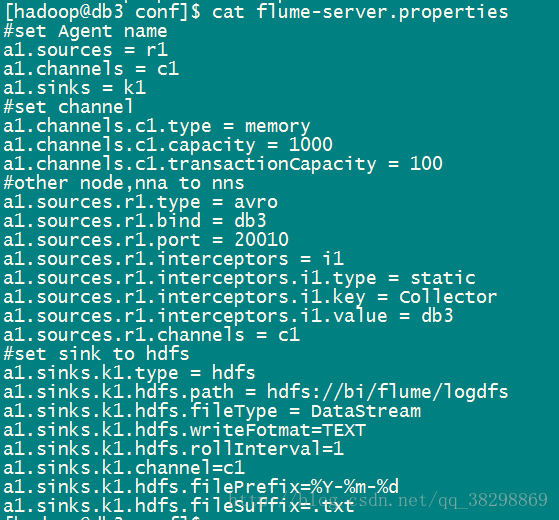
其中的属性描述:
agent.channels.ch1.type :Agent的channel类型
a1.sinks.k1.type = hdfs : Sink类型
a1.sinks.k1.hdfs.path = hdfs://bi/flume/logdfs : Sink类型
a1.sinks.k1.hdfs.fileType = DataStream : 流数据的文件类型
a1.sinks.k1.hdfs.writeFotmat=TEXT : 数据写入格式
a1.sinks.k1.hdfs.rollInterval=1 : hdfs sink 间隔多长将临时文件滚动成最终目标文件,单位是秒;如果设置为0,则表示不根据时间来滚动文件
agent.sinks.k1.hdfs.rollCount : 当events数据达到该数量时候,将临时文件滚动成目标文件;如果设置成0,则表示不根据events数据来滚动文件
flume集群启动:
在 Collector各节点上启动命令如下:
flume-ng agent --conf conf --conf-file /home/hadoop/flume-1.6.0/conf/flume-server.properties --name a1 -Dflume.root.logger=INFO,console > /home/hadoop/flume-1.6.0/logs/flume-server.log 2>&1 &注:命令中的a1 表示配置中的Agent的Name,如配置文件中的a1。配置文件填准确的地址
在Agent各节点上启动命令:
flume-ng agent --conf conf --conf-file /home/hadoop/flume-1.6.0/conf/flume-client.properties --name agent1 -Dflume.root.logger=INFO,console > /home/hadoop/flume-1.6.0/logs/flume-client.log 2>&1 &注:命令中的agent1表示配置文件中的Agent的Name。
FlumeNG集群的HA测试:
场景如下:我在Agent1节点上传文件,由于配置Collector1的权重比Collector2大,所以Collector1优先采集并上传到存储系统。然后我们kill掉Collector1,再重新编辑该文件,此时由Collector2负责日志采集上传工作,之后,我们手动启动Collector1节点的Flume服务,再次在Agent1编辑该文件,发现Collector2恢复优先级别的采集工作。
四、总结
在配置高可用的Flume NG时,在Agent中需要绑定对应的Collector1和Collector2的IP和Port,另外,在配置Collector节点时,需要修改当前FLume节点的配置文件中的bind和IP port。