【机器学习系列之三】特征工程
目录
1.特征工程概述与采样
2.数据预处理
2.1 数值型数据
2.2 类别型数据
2.3 文本型
2.4 其他
2.5 时间型
2.6 统计特征
2.7 特征结合feature stacker
3 . 特征选择
3.1 Filter
3.2 Wrapper
3.3 Embedded
4 . 降维技术
4.1 PCA(Principal Component Analysis)
4.2 LDA
4.3 SVD(文本降维)
1.特征工程概述与采样
数据和特征决定了机器学习的上限,而模型和算法则是逼近这个上限。因此,特征工程就变得尤为重要了。特征工程的主要工作就是对特征的处理,包括数据的采集,数据预处理,特征选择,甚至降维技术等跟特征有关的工作。
注:以下样例数据部分采用官方文档提供的样本数据iris
1.1 采样
随机采样
简单易用。抽到每个样本的概率一样。
分层采样
它是保留类别比例的采样方式。先将样本数据集按照某种特征分为若干层次结构,然后在各层次结构中随机采样,组成一个样本。每一层内个体变化越小越好,层级间变化越大越好。
1.2 正负样本不平衡问题
正样本>>>负样本,且量很大
考虑下采样。即在正样本中按照一定比例抽取数据,抛弃部分数据。
正样本>>>负样本,但量不大
修改损失函数:每个样本都会对损失函数贡献一点努力,如果把负样本重复几次,数据就会更加关注负样本。
oversampling:在图像处理中,可以把图像旋转,就会变成另外一张完全不同的图像。
2.数据预处理
garbage in,garbage out.顾名思义就是数据质量越差,得到的结果也就越差,在一开始采集数据的时候就应该认真分析所选择的数据包含哪些维度的数据。
然后就是确定数据的存储格式,以及数据之间的连接。很多情况下,模型对数据正负样本比是敏感的,所以还要保证数据的正负样本数量相差无几。
2.1 数值型数据
通过特征提取,可以得到未经处理过的特征数据,但它的分布可能相差很大,比如月收入和年龄,这时就要把数据处理成同一个分布内,使得参数发挥更大的作用。
标准化
标准化的前提是特征数据服从正态分布,通过标准化把数据统一处理为标准正太分布。在sklearn的preprocessing中有专门的函数处理:
![]()
他的原理如下:
区间缩放法
区间缩放最常见的是利用两个最值缩放:
 计算公式如下:
计算公式如下:
归一化
标准化是依照特征矩阵的列来处理数据,将样本的特征值转换为同一量纲下;而归一化是按照矩阵的行处理数据,目的是在做点乘运算或核函数计算相似性时,拥有统一的标准。
规则为l2的归一化公式如下:
高级
离散化
把数值型数据等距切分,或者等频切分,划分成类别型的数据。
以年龄为例判断人会不会让座,等距切分意味着给定步长,0-30,30-60,60-90,90-120,分成了四个等级。
以淘宝的价格数据切分为例,等频切分意味着从零到最大值,每1000(频数自定)个样本划分一个等级。
2.2 类别型数据
对于类别型数据,比如预测房价时,房子的位置,算法无法接受这样的数据,就需要我们用数字把它的含义表示出来,然后用亚变量编码。
LabelEncoder
意思是把类别型的特征,先用数字表示,以便进行one-hot编码。
from sklearn.preprocessing import LabelEncoder
LE = LabelEncoder()
X_cat =LE.fit_transform(X[categorical_features])One-Hot
假如一个特征是类别型的,特征中只有三个类型,就可以用三维向量编码,出现该类型记为1,不出现则记为0。Sklearn也有对应的函数如下:
也可以使用pandas的get_dummies来处理。
二值化
二值化的核心在于设定一个阀值,大于该阀值设定为1,小于该阀值设定为0。用公式表示如下:

Histogram映射
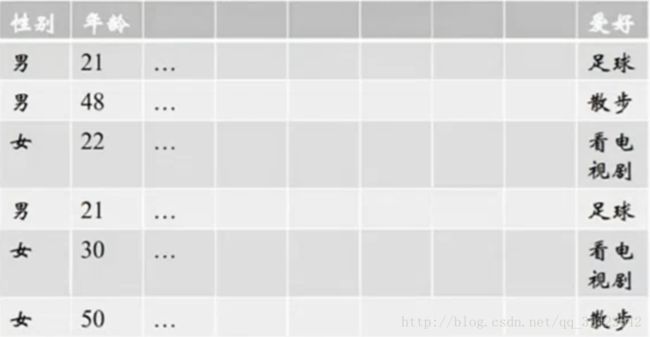
以上图为例:将爱好和性别进行特征组合。得到一个分别表征足球,散步,看电视剧的向量:男[ 23,13,0 ] ;女[ 0,13,23 ]
2.3 文本型
词袋
直接把文本数据丢给模型,模型是无法解释的,因此需要把文本型的数据用数值表示。去掉停用词,标点符号,留下表达实际含义的词组成列表,在词库中映射稀疏向量。

python函数对应
from sklearn.feature_extraction.text import CountVectorizer
CVT = CountVectorizer()
sparse_text_data = CVT.fit_transform(text_data)此外,还可以把词袋扩充为n-gram,它的思想是:在整个语言环境中,句子T的出现概率是由组成T的N个词组成的。
Tf-idf(Term Frequency-inverse document frequency)
Tf-idf是一种统计方法,用来评估一个词语在一个文件集中一份文件的重要程度,字词的重要性会随着它在一份文件中出现的频数增多而增加,但会随着它在语料库中出现的频率成反比下降。
Tf(t) = (词t在当前文档中出现的次数)/(词t在所有文档中出现的次数)
Idf(t) = In(总文档数/含t的文档数)
from sklearn.feature_extraction.text import TfidfVectorizer
tfi = TfidfVectorizer()
text_data = tfi.fit_transform(text_data)Tf-idf的效果一般来说会比Count要好,如果你只是把
还有一种是word2vec,简单来说是把稀疏型数据变成稠密型,同时考虑了上下文。难以用三言两语说清,在此不细说。
2.4 其他
缺失值处理
在sklearn中也有计算缺失值的函数imputer。填补缺失值可以使用平均数,中位数,或者行/列众数。

组合特征
拼接特征,当两个特征同时出现时,标记为1。(一般会把用户聚类,用户类别来组合等)
2.5 时间型
连续值:持续时间,间隔时间(上次活动时间到现在)
离散值:一年中的第几个月,第几个星期,一年中哪个季度,工作日/周末,一周中星期几,一天中哪个时间段。(比如送外卖时是否是饭点)
2.6 统计特征
加减平均:对连续值求一个平均,另开一个特征—比平均值高了多少,低了多少。用户连续登陆天数,超过平均多少。
分位线:用户在哪个分位线处
次序型:排在第几位
比例型:好,中,差型比例。你已超过全国百分几的同学。
以推荐系统挖掘特征:
(1) 前一天的购物车商品很有可能第二天就被购买 =>规则
(2) 剔除掉在30天里从来不买东西的人 => 数据清洗
(3) 加车N件,只买了一件的,剩余的不会买 => 规则
(4) 购物车购买转化率 =>用户维度统计特征
(5) 商品热度 =>商品维度统计特征
(6) 对不同item点击/收藏/购物车/购买的总计 =>商品维度统计特征
(7) 对不同item点击/收藏/购物车/购买平均每个user的计数 =>用户维 度统计特征
(8) 变热门的品牌/商品 =>商品维度统计特征(差值型)
(9) 最近第1/2/3/7天的行为数与平均行为数的比值 =>用户维度统计
特征(比例型)
(10) 商品在类别中的排序 =>商品维度统计特征(次序型)
(11) 商品交互的总人数 =>商品维度统计特征(求和型)
(12) 商品的购买转化率及转化率与类别平均转化率的比值=>商品维度统
计特征(比例型)
(13) 商品行为/同类同行为均值=>商品维度统计特征(比例型)
(14) 最近1/2/3天的行为(按4类统计)=>时间型+用户维度统计特征
(15) 最近的交互离现在的时间=>时间型
(16) 总交互的天数=>时间型
(17) 用户A对品牌B的总购买数/收藏数/购物车数=>用户维度统计特征
(18) 用户A对品牌B的点击数的平方 =>用户维度统计特征
(19) 用户A对品牌B的购买数的平方=>用户维度统计特征
(20) 用户A对品牌B的点击购买比=>用户维度统计特征(比例型)
(21) 用户交互本商品前/后,交互的商品数=>时间型+用户维度统计特征
(22) 用户前一天最晚的交互行为时间=>时间型
(23) 用户购买商品的时间(平均,最早,最晚)=>时间型
2.7 特征结合feature stacker
from sklearn.pipeline import FeatureUnion
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest
pca = PCA(n_components = 10)
skb = SelectKBest(k =1)
combine_features = FeatureUnion([('pca',pca),('skb',skb)])对于不同类型的数据(稀疏数据和稠密数据)
import numpy as np
from scipy import sparse
#对稀疏数据
X = sparse((x1, x2, x3,..., xn))
#对稠密数据
X = np.hstack((x1, x2, x3,..., xn))3 . 特征选择
3.1 Filter
方差选择法
使用方差作为衡量标准,选择方差大于某阀值的特征,使得他们对预测结果的区分性最大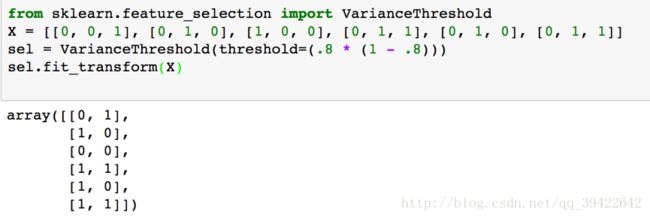
相关系数法
把特征高度相关的数据去掉,留下区分度大的数据。一般会采用Pearson相关系数,它是协方差除以两个变量的标准差得到的,其中协方差计算公式如下:
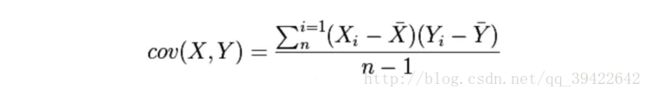
Pearson相关系数:
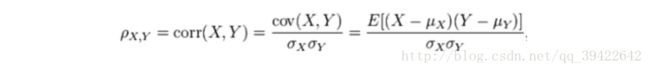 Scipy中提供了计算Pearson相关系数的函数。
Scipy中提供了计算Pearson相关系数的函数。
卡方检验法
卡方检验是一种统计量的分布在零假设成立时近似服从卡方分布的假设检验,它考察的是观察值与期望值之间的差距。
计算公式如下:

在sklearn相应的函数:
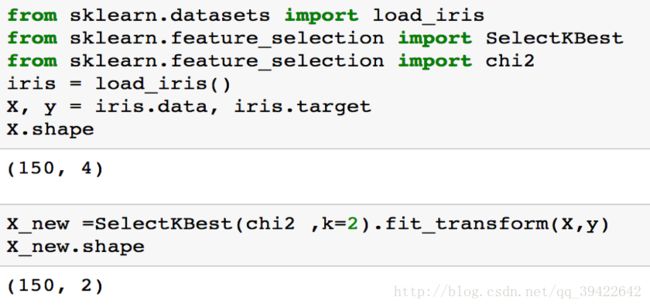
互信息法
可以简单理解为自变量对因变量的相关性。
计算公式如下:
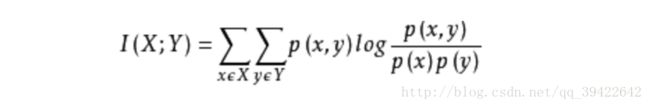
3.2 Wrapper
把特征选择看作特征子集搜索问题,筛选特征子集,用模型评估效果。
递归消除特征法
递归消除特征法基于多轮训练,每轮训练后消除一些权值系数(也就是逐步删除特征),再用新的数据集训练,重复以上步骤若干步,看auc或其他指标的变化,如果变化太大,说明特征删太多了。
可以用feature_selection的RFE库来选择:

from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
rfe = RFE(estimator = LogisticRegression(),n_features_to_select = 2)
rfe.fit(X,y)
print('features sorted by their rank')
print(rfe.ranking_)
#输出特征重要度的排名:features sorted by their rank
#[3 1 2 1]3.3 Embedded
基于惩罚项的特征选择
使用feature_selection库的SelectFromModel结合L1惩罚项的逻辑回归进行特征选择,代码如下:
 L1惩罚项只是选择了具有同等相关性的特征中的一个,但不代表特征重要性,故可以使用L2惩罚项优化。
L1惩罚项只是选择了具有同等相关性的特征中的一个,但不代表特征重要性,故可以使用L2惩罚项优化。
基于树模型的特征选择
树模型中GBDT也可以用于特征选择,使用feature_selection库的SelectFromModel结合GBDT选择:

4 . 降维技术
如果特征矩阵的维度过大,有很多分类能力比较差的特征,这时候直接训练就会导致计算量非常大,训练时间长且效果不佳,这时降维必不可少。但降维不是特征选择,因为降维的本质在于寻找某种映射方法,把高维空间中的数据映射低维空间中。
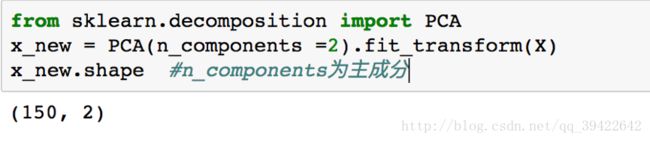
4.1 PCA(Principal Component Analysis)
PCA也称主成分分析法,是目前应用最广泛线性降维方法,它通过寻找一个线性投影,把高维数据映射到低维,同时在所投影的维度上方差尽可能大,以便使用较少的数据维度的同时,较好的保持原有数据的特性。
python中也提供了相关的库函数:
4.2 LDA
Linear Discriminant Analysis是一种有监督的线性降维算法,它希望降维后的数据点尽可能地容易被区分。

注:经测试,python2的sklearn中没有lda这个包
4.3 SVD(文本降维)
在对文本数据进行向量化以后,由于是稀疏矩阵太稀疏,同样可以使用降维技术,这里使用的是奇异值分解。
from sklearn.decomposition import TruncatedSVD
tsvd = TruncatedSVD(n_components = 120)
Xdata = tsvd.fit_transform(X)一般对于tf-idf对应的主成分为120-200个左右,如果更多的主成分也许数据有所提升,但对计算机的资源消耗太大了。
降维技术不是特征选择,降维是把高维数据的特征映射到低维空间中,而特征选择是在高维空间中直接剔除部分特征,选出重要特征。
送一张模型选择的图
参考
很多细小的点参考了七月算法课课件
自己总结的
知乎回答
当然还有官网给的案例的代码
Approaching (Almost) Any Machine Learning Problem |
更新1
2017.12.11
增加文本方面的详细处理
特征结合feature stacker