python爬虫-urllib,urllib3库的使用
理解虚拟机的使用
由于服务器的开发往往是基于linux系统的,例如Ubuntu,Centos等等,所以如果我们是windows操作系统的个人电脑,利用虚拟机来进行相关后端的学习是非常有好处的,这里只陈述在开发时物理机和虚拟机的python文件的逻辑关系。
本地windows物理机需要有python解释器,pycharm;
pycharm是对本地文件进行编辑的;
虚拟Ubuntu机需要有python解释器;
以上一篇下载一张图片的脚本为例,如果我们运行了Ubuntu虚拟机,通过pycharm创建的文件是在本地的,由于pycharm连接了虚拟机,可以设置自动上传文件,会将我们的本地创建的脚本上传到虚拟机中,在本地运行时,其实是通过虚拟机的解释器来运行虚拟机上的文件,因此我们在程序最后的将图片写入文件中这一操作产生的图片文件,在本地中是不会有的,在pycharm的项目目录中就不会看到,但是虚拟机中的对应的项目目录已经创建图片了,所以我们需要通过pycharm的Romote Host这个窗口将虚拟机中的图片下载到本地。
urllib库的使用
爬虫开发时,一般不会使用这个库,但是我们需要学习这个库。
urllib库简介
urllib是一个用来处理网络请求的python标准库,它包含4个模块
- urllib.requests:请求模块,用于发起网络请求
- urllib.parse:解析模块,用于解析
- urllib.error:异常处理模块,用于处理request引起的异常
- urllib.robotparse:用于解析robots.txt文件
urllib.request模块
request模块主要负责构造和发起网络请求,并在其中添加Hearders,Proxy等。利用它可以模拟浏览器的请求发起过程——1.发起网络请求;2.操作cookie;3.添加Hearders;4.使用代理
方法:
urrlib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False,context=None)
urlopen是一个简单发送网络请求的方法。它接收一个字符串格式的url,它会向传入的url发送网络请求,然后返回结果
from urllib import request
response = request.urlopen(rul='http://httpbin.org/get')
urlopen默认会发送GET请求,当传入data参数时,则会发起POST请求。data参数是字节类型、或者类文件对象或可迭代对象。
response = request.urlopen(url='http://httpbin.org/post',data=b'username=wgdh&password=123456')
还可以设置超时,如果请求超过设置时间,则抛出异常。timeout没有指定则用系统默认设置,timeout只对http,https以及ftp连接起作用,它以秒为单位,比如可以设置timeout=0.1 超时时间为0.1秒
reponse = request.urlopen(url='http://www.baidu.com',timeout=0.1)
以下是通过request代理的脚本:
from urllib import request
'''
urllib库
'''
# 设置超时
request.urlopen("http://httpbin.org/get",timeout=0.1)
# 发送一个get请求
response = request.urlopen(url="http://httpbin.org/get")
# 发送一个post请求
response2 = request.urlopen(
url="http://httpbin.org/post",
data = b'username=wgdh&password=123456'
)
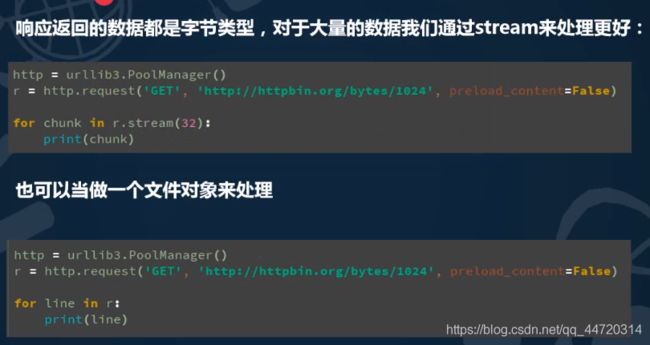
urllib.Response对象
urllib库中的类或者方法,在发送网络请求后,都会返回一个urllib.response的对象,它包含了请求回来的数据结果。并且还包含了一些属性和方法,供我们处理返回的结果
- read()获取响应返回的数据,只能用一次
print(reponse.read())
- readline()读取一行
while True:
data = response.readline()
if data:
print(data)
- info()获取响应头信息
print(response.info())
- geturl()获取访问的url
print(response.geturl())
- getcode()返回状态码
print(response.getcode())
以下是方法使用的结果:
from urllib import request
'''
urllib库
'''
# 设置超时
request.urlopen("http://httpbin.org/get")
# 发送一个get请求
response = request.urlopen(url="http://httpbin.org/get")
print(response.getcode())
print(response.info())
print(response.read())
# 发送一个post请求
response2 = request.urlopen(
url="http://httpbin.org/post",
data = b'username=wgdh&password=123456'
)
打印出的结果

request.Request对象
利用urlopen可以发起最基本的请求,但这几个简单的参数不足以构建一个完整的请求,可以利用一个更强大的Request对象来构建更加完整的请求
req = request.Request('http://www.baidu.com')
response = request.urlopen(req)
1.请求头添加
通过urllib发送的请求会有一个默认的Headers:“User-Agent” : “Python-urllib/3.6”,指明请求是由urllib发送的。所以遇到一些验证User-Agent的网站时,需要我们自定义Headers把自己伪装起来
from urllib import request
'''
urllib库
'''
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
#如果请求遇到403 Forbidden 一般使用Referer可以解决
'Referer':'http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E5%9B%BE%E7%89%87'
}
req = request.Request(
url='https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1571545714469&di=8f1211786f1072b68c8f9d834161fd32&imgtype=0&src=http%3A%2F%2Fpic26.nipic.com%2F20121230%2F9034633_172138299000_2.jpg',
headers=headers
)
response = request.urlopen(req)
with open('test.jpg','wb') as f:
f.write(response.read())
相对路径下产生图片:
2.操作cookie

3.设置代理

urllib.parse模块
parse模块是一个工具模块,提供了需要对url处理的方法,用于解析url。
- parse.quote()
url中只能包含ascii字符,在实际操作中,get请求通过url传递的参数中会有大量的特殊字符,例如汉字,那么就需要进行url编码。
例如https://baike.baidu.com/item/URL编码/3703727?fr=aladdin
下面的例子,我们需要将编码进行url编码:
url = 'http://httpbin/org/get?aaa={}'
safa_url = url.format(parse.quote('五更灯火'))
print(safe_url
运行结果:
http://httpbin.org/get?aaa=%E5%BF%83%E8%93%9D
完整示例:
from urllib import request,parse
'''
urllib库
'''
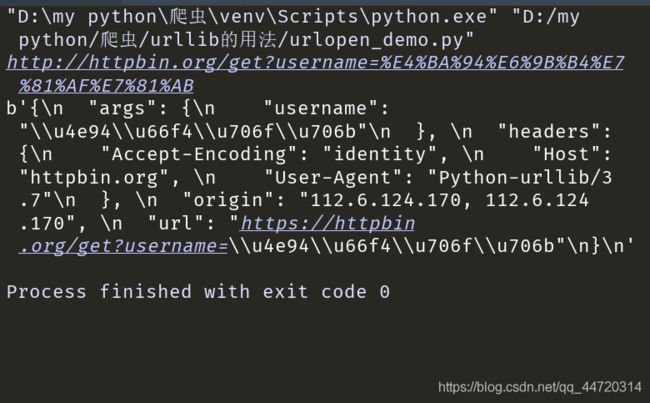
url = 'http://httpbin.org/get?username={}'.format(parse.quote('五更灯火'))
print(url)
response = request.urlopen(url)
print(response.read())
利用parse.unquote()可以进行解码
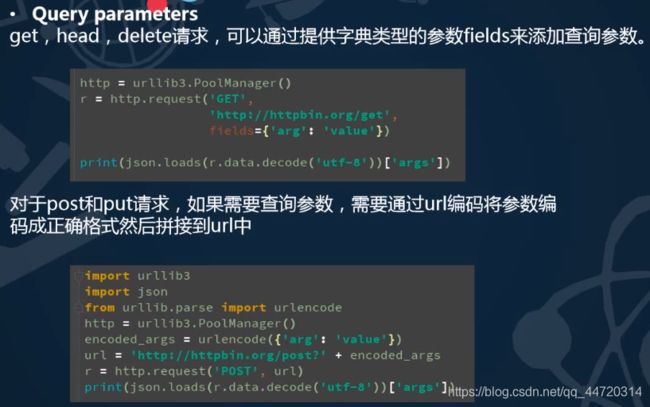
- parse.urlencode()
在发送请求的时候,往往需要传递很多的参数,如果用字符串方法去拼接会比较麻烦,parse.urlencode()方法就是用来拼接url参数的
from urllib import request,parse
'''
urllib库
'''
args = {
'username':'五更灯火',
'age':'19'
}
url_args = parse.urlencode(args)
print(url_args)
运行结果:
username=%E4%BA%94%E6%9B%B4%E7%81%AF%E7%81%AB&age=19
也可以通过parse.parse.qs()方法将它转回字典
print(parse.parse_qs('username=%E4%BA%94%E6%9B%B4%E7%81%AF%E7%81%AB&age=19')
运行结果:
{'username':['五更灯火'],'age':['19']}
urllib.error模块
error模块主要负责处理异常,如果请求出现错误,我们可以用error模块进行处理,主要包含URLError和HTTPError
- URLRError:是error异常模块的基类,由request模块产生的异常都可以用这个类来处理
- HTTPError:是URLError的子类,主要包含三个属性:code:请求的状态码,reason:报错原因,headers:请求头
urllib.robotparse模块
robotparse模块主要负责处理爬虫协议文件,robots.txt的解析
https://taobao.com/robots.txt
Robots协议(也成为爬虫协议,机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocal),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots.txt是一个文本文件,使用任何一个常见的文本编辑器,比如Windows系统自带的Notepad,就可以创建和编辑它。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt的文件告诉爬虫程序在服务器上什么文件是可以被查看的。
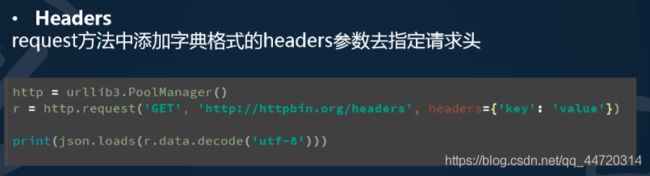
urllib3库的使用
urlib3是一个基于python3的功能强大,友好的http客户端。越来越多的python应用开始采用urllib3。它提供了很多python标准库里没有的重要功能。
python3.4以下需要通过pip来安装 :pip install urllib3,3.4以上则已经成为标准库
初识实例:
import urllib3
http = urllib3.PoolManager()
r = http.request('GET','http://www.baidu.com')
print(r.status)
print(r.data)
一.构造请求(request)
第一件事情导入urllib3库: import urllib3
之后需要实例化一个PoolManager对象构造请求。这个对象处理连接池和线程安全的所有细节,所以我们不用自行处理。
http = urllib3.PoolManager()
用request()方法发送一个请求
r = http.request('GET','http://httpbin.org/robots.txt')
b'User-agent:*\nDisallow: /deny\n'
可以用request()方法发送任意http请求,我们发送一个POST请求
r = http.request(
'POST',
'http://httpbin.org/post',
fields={'hello':'world'})


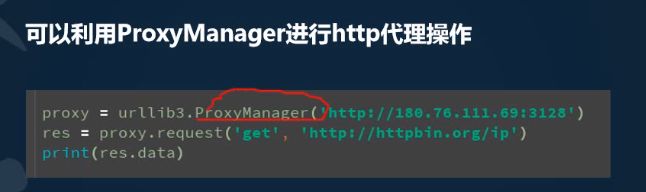
http代理:将请求发送到一个代理ip,让其代替我们访问url,达到匿名访问的效果,可以百度搜索国内的代理公司提供的代理ip

爬虫的一般开发流程
开发一个爬虫可以简单的分为以下5个步骤:
- 找到目标数据
- 分析请求流程
- 构造http请求
- 提取清洗数据
- 数据持久化(存储到本地,数据库)
示例代码:
import urllib3
import re
'''
下载百度图片首页面的所有图片
'''
# 1.找到目标数据
page_url = 'http://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%CD%BC%C6%AC&fr=ala&ala=1&alatpl=others&pos=0'
# 2.分析请流程
# 下载html
http = urllib3.PoolManager()
res = http.request('get',page_url)
#print(res.data)
html = res.data.decode('utf-8')#通过ctrl+f查找charset
# 提取img_urls
img_urls = re.findall(r'"thumbURL":"(.*?)"',html)
#print(img_urls)
# 构造请求头,防止请求被禁止
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'Referer': 'http://image.baidu.com/search/detail?ct=503316480&z=0&ipn=d&word=%E5%9B%BE%E7%89%87&step_word=&hs=0&pn=6&spn=0&di=206910&pi=0&rn=1&tn=baiduimagedetail&is=0%2C0&istype=0&ie=utf-8&oe=utf-8&in=&cl=2&lm=-1&st=undefined&cs=2156100763%2C2013807410&os=4249095823%2C194405355&simid=3276684632%2C157455792&adpicid=0&lpn=0&ln=1247&fr=&fmq=1571541153419_R&fm=&ic=undefined&s=undefined&hd=undefined&latest=undefined©right=undefined&se=&sme=&tab=0&width=undefined&height=undefined&face=undefined&ist=&jit=&cg=&bdtype=0&oriquery=&objurl=http%3A%2F%2Fpic26.nipic.com%2F20121230%2F9034633_172138299000_2.jpg&fromurl=ippr_z2C%24qAzdH3FAzdH3Fooo_z%26e3Bgtrtv_z%26e3Bv54AzdH3Ffi5oAzdH3FdAzdH3Fm8AzdH3F0nmacmbh8dkmnad9_z%26e3Bip4s%3F_p%3Dp&gsm=&rpstart=0&rpnum=0&islist=&querylist=&force=undefined'
}
# 遍历 下载
for index,img_url in enumerate(img_urls):
# 下载图片
img_res = http.request('get',img_url,headers=headers)
# 动态的拼接文件名
img_file_name = '%s.%s'%(index,img_url.split('.')[-1])
with open('img_file_name','wb') as f:
f.write(img_res.data)
# 图片是浏览器下载下来的
# 通过图片的url也是资源,也是数据,会比图片更早的下载回来