深度学习论文: Fast-SCNN: Fast Semantic Segmentation Network及其PyTorch实现
深度学习论文: Fast-SCNN: Fast Semantic Segmentation Network及其PyTorch实现
Fast-SCNN: Fast Semantic Segmentation Network
PDF:https://arxiv.org/pdf/1902.04502.pdf
PyTorch: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
Fast SCNN 受 two-branch 结构和 encoder-decoder 网络启发,用于高分辨率(1024×2048)图像上的实时语义分割任务,帧率达到123.5,准确率达到68%;

设计了低容量的Fast-SCNN,并且通过经验验证了在这个网络架构上运行更多迭代次数训练的效果和使用ImageNet预训练或者使用附加精细化训练数据集训练的效果一样成功;
2 Network Architecture
Fast-SCNN网络结构图如下,主要分为四个阶段:1 Learning to Downsample,2 Global Feature Extractor,3 Feature Fusion Module,4 Classifier
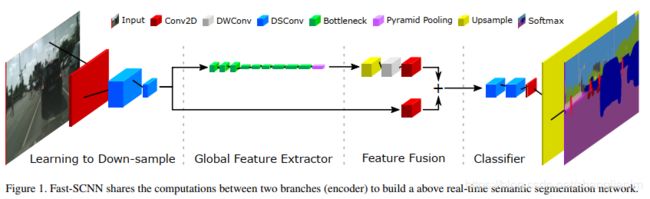
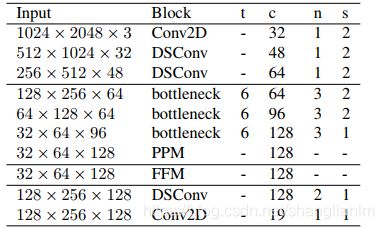
Fast SCNN的详细参数如下
2-1 Learning to Downsample
learn to downsample 模块中包含3个层。
第一层是一个标准的卷积层(Conv2D),其它两个层则为 depthwise separable 卷积层(DSConv)。
class LearningToDownsample(nn.Module):
def __init__(self):
super(LearningToDownsample, self).__init__()
self.conv = Conv3x3BNReLU(in_channels=3, out_channels=32, stride=2)
self.dsConv1 = DSConv(in_channels=32, out_channels=48, stride=2)
self.dsConv2 = DSConv(in_channels=48, out_channels=64, stride=2)
def forward(self, x):
x = self.conv(x)
x = self.dsConv1(x)
out = self.dsConv2(x)
return out
2-2 Global Feature Extractor
多个bottleneck结构用于捕捉图像分割的全局环境信息;

末端增加了一个金字塔池化模块来聚合不同区域的环境信息。
class InvertedResidual(nn.Module):
def __init__(self, in_channels, out_channels, stride, expansion_factor=6):
super(InvertedResidual, self).__init__()
self.stride = stride
mid_channels = (in_channels * expansion_factor)
self.bottleneck = nn.Sequential(
Conv1x1BNReLU(in_channels, mid_channels),
Conv3x3BNReLU(mid_channels, mid_channels, stride,groups=mid_channels),
Conv1x1BN(mid_channels, out_channels)
)
if self.stride == 1:
self.shortcut = Conv1x1BN(in_channels, out_channels)
def forward(self, x):
out = self.bottleneck(x)
out = (out+self.shortcut(x)) if self.stride==1 else out
return out
class PyramidPooling(nn.Module):
"""Pyramid pooling module"""
def __init__(self, in_channels, out_channels):
super(PyramidPooling, self).__init__()
mid_channels = in_channels // 4
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=mid_channels, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(in_channels=in_channels, out_channels=mid_channels, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(in_channels=in_channels, out_channels=mid_channels, kernel_size=3, stride=1, padding=1)
self.conv4 = nn.Conv2d(in_channels=in_channels, out_channels=mid_channels, kernel_size=3, stride=1, padding=1)
self.out = Conv3x3BNReLU(in_channels * 2, out_channels, 1)
def pool(self, x, size):
avgpool = nn.AdaptiveAvgPool2d(size)
return avgpool(x)
def upsample(self, x, size):
return F.interpolate(x, size, mode='bilinear', align_corners=True)
def forward(self, x):
size = x.size()[2:]
feat1 = self.upsample(self.conv1(self.pool(x, 1)), size)
feat2 = self.upsample(self.conv2(self.pool(x, 2)), size)
feat3 = self.upsample(self.conv3(self.pool(x, 3)), size)
feat4 = self.upsample(self.conv4(self.pool(x, 6)), size)
x = torch.cat([x, feat1, feat2, feat3, feat4], dim=1)
x = self.out(x)
return x
class GlobalFeatureExtractor(nn.Module):
def __init__(self):
super(GlobalFeatureExtractor, self).__init__()
self.bottleneck1 = self._make_layer(inplanes=64, planes=64, blocks_num=3, stride=2)
self.bottleneck2 = self._make_layer(inplanes=64, planes=96, blocks_num=3, stride=2)
self.bottleneck3 = self._make_layer(inplanes=96, planes=128, blocks_num=3, stride=1)
self.ppm = PyramidPooling(in_channels=128, out_channels=128)
def _make_layer(self, inplanes, planes, blocks_num, stride=1):
layers = []
layers.append(InvertedResidual(inplanes, planes, stride))
for i in range(1, blocks_num):
layers.append(InvertedResidual(planes, planes, 1))
return nn.Sequential(*layers)
def forward(self, x):
x = self.bottleneck1(x)
x = self.bottleneck2(x)
x = self.bottleneck3(x)
out = self.ppm(x)
return out
2-3 Feature Fusion Module
为了确保算法计算效率,所以 FFM只是将不同特征做累加

class FeatureFusionModule(nn.Module):
def __init__(self, num_classes=20):
super(FeatureFusionModule, self).__init__()
self.dsConv1 = nn.Sequential(
DSConv(in_channels=128, out_channels=128, stride=1),
Conv3x3BN(in_channels=128, out_channels=128, stride=1)
)
self.dsConv2 = DSConv(in_channels=64, out_channels=128, stride=1)
def forward(self, x, y):
x = F.interpolate(x, scale_factor=4, mode='bilinear', align_corners=True)
x = self.dsConv1(x)
return x + self.dsConv2(y)
2-4 Classifier
两个深度可分离卷积层加上一个逐点卷积。
Softmax 在训练中使用,因为有用到梯度下降。在前向推理时,我们可以将昂贵的 softmax 替换为 argmax,因为它们都是单调递增的。我们将这个方案称作 Fast-SCNN cls(classification)。
class Classifier(nn.Module):
def __init__(self, num_classes=19):
super(Classifier, self).__init__()
self.dsConv = nn.Sequential(
DSConv(in_channels=128, out_channels=128, stride=1),
DSConv(in_channels=128, out_channels=128, stride=1)
)
self.conv = Conv3x3BNReLU(in_channels=128, out_channels=num_classes, stride=1)
def forward(self, x):
x = self.dsConv(x)
out = self.conv(x)
return out
3 Experiments
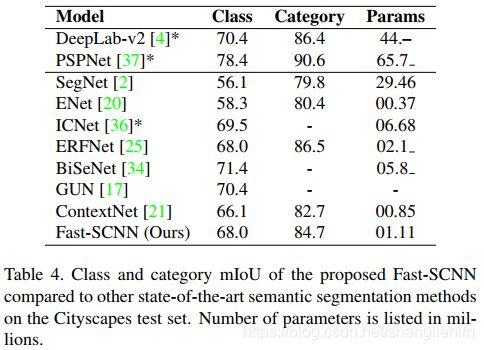
classes IoU和Categories IoU:
运行时间:
