【Scrapy学习心得】爬虫实战四(动态加载的页面数据获取)
【Scrapy学习心得】爬虫实战四(动态加载的页面数据获取)
声明:仅供技术交流,请勿用于非法用途,如有其它非法用途造成损失,和本博客无关
目录
- 【Scrapy学习心得】爬虫实战四(动态加载的页面数据获取)
- 本次爬虫使用的是:`scrapy+selenium`
- 一、配置环境
- 二、准备工作
- 三、分析网页
- 四、爬取数据
- 五、保存数据
- 六、数据展示
- 写在最后
爬取的网站:今日头条各个板块的新闻信息 点击跳转
本次爬虫使用的是:scrapy+selenium
一、配置环境
python3.7pycharmScrapy1.7.3win10pymysql
二、准备工作
- 在
cmd命令行中进入需要创建项目的目录运行scrapy startproject haha - 创建成功后继续执行
cd haha - 然后执行
scrapy genspider tt toutiao.com - 最后在spider文件夹下可以看到刚创建的
tt.py爬虫文件
三、分析网页
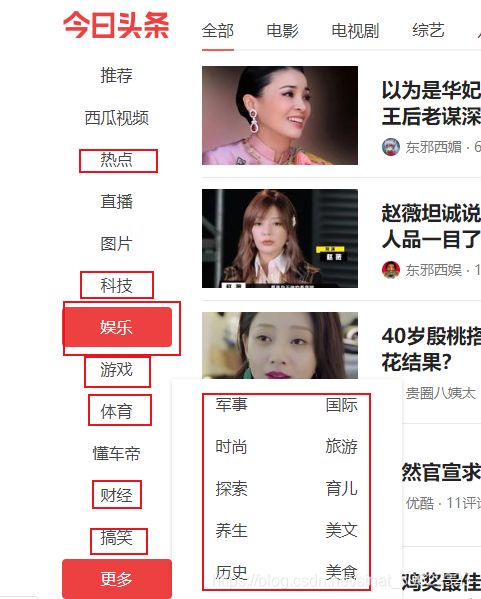
可以在页面的左边找到对应板块的url,并且会发现,页面是通过AJAX加载页面的,就是鼠标滑轮往下滚动,页面内容才会加载新的出来,所以此时如果用requests来爬的话,返回的信息肯定是不多的,那么简单粗暴的方法就是用selenium来爬了,那么scrapy怎么使用selenium呢,很简单,只需添加一个中间件就行了
所以总共我要爬取的内容有:
- 分类的名称以及其具体的
url地址 - 新闻的标题以及对应的
url地址
查找元素的那些操作我就不放上来了,因为没什么难度的,会来学scrapy框架的同学肯定是跟我一样那些什么requests啊,urllib啊,selenium啊等等都是用腻了才来的,是吧
四、爬取数据
下面首先放上最重要的middlewares.py的代码:
from scrapy import signals
import time
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from scrapy.http.response.html import HtmlResponse
class seleniumDownloaderMiddleware(object):
def __init__(self):
options = webdriver.ChromeOptions()
# options.add_argument('disable-infobars') #去除警告
options.add_argument('headless') #无头模式
self.driver = webdriver.Chrome(options=options)
# self.driver.maximize_window()
self.num = 10 #需要滑滚页面的次数,想拿多一点数据就设置的大一点
def process_request(self,request,spider):
#第一次请求只需拿到各个板块的url
if request.url == 'https://www.toutiao.com/':
self.driver.get(request.url)
time.sleep(1)
html = self.driver.page_source
response = HtmlResponse(
url=self.driver.current_url,
body=html,
request=request,
encoding="utf-8"
)
return response
else:
self.driver.get(request.url)
for i in range(self.num):
ActionChains(self.driver).send_keys([Keys.END, Keys.PAGE_UP]).perform()
time.sleep(1)
html = self.driver.page_source
response = HtmlResponse(
url=self.driver.current_url,
body=html,
request=request,
encoding="utf-8"
)
return response
下面是爬虫文件tt.py的代码如下:
# -*- coding: utf-8 -*-
import scrapy
class TtSpider(scrapy.Spider):
name = 'tt'
allowed_domains = ['toutiao.com']
start_urls = ['https://www.toutiao.com/']
def parse(self, response):
li_list = response.xpath('//div[@class="channel"]/ul/li')
for li in li_list:
item = {}
url = li.xpath('./a/@href').get()
url = response.urljoin(url)
name = li.xpath('.//span/text()').get()
if name not in ['推荐', '西瓜视频', '直播', '图片', '懂车帝', '更多']:
item['url']=url
item['name']=name
yield scrapy.Request(item['url'],callback=self.parse_news,meta={'item':item})
li_list1 = response.xpath('//ul[@class="bui-box"]/li')
for li in li_list1:
item={}
url = li.xpath('./a/@href').get()
url = response.urljoin(url)
name = li.xpath('.//span/text()').get()
item['url'] = url
item['name'] = name
yield scrapy.Request(item['url'], callback=self.parse_news, meta={'item': item})
def parse_news(self,response):
item=response.meta['item']
li_list = response.xpath('//div[@class="wcommonFeed"]/ul/li')
for li in li_list:
if li.xpath('.//a[@class="link title"]/text()').get() is not None:
title = li.xpath('.//a[@class="link title"]/text()').get()
title_url = li.xpath('.//a[@class="link title"]/@href').get()
title_url = response.urljoin(title_url)
item['title']=title
item['title_url']=title_url
yield item
五、保存数据
直接保存到pymysql数据库当中,修改pipeline.py文件,代码如下:
import pymysql
class HahaPipeline(object):
def __init__(self):
dbparams = {
'host': 'localhost',
'user': 'youruser',
'password': 'yourpassword',
'database': 'yourdatabase',
'charset': 'utf8'
}
self.conn=pymysql.connect(**dbparams)
self.cursor=self.conn.cursor()
self.sql='insert into tt(name,title,title_url) values(%s,%s,%s)'
def process_item(self, item, spider):
self.cursor.execute(self.sql, [item['name'], item['title'], item['title_url']])
self.conn.commit()
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
现在我们的爬虫大致已经是写完了,不过我还要修改一下setting.py文件的一些设置,需要增加的语句有:
LOG_LEVEL='WARNING' #设置日志输出级别
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36' #设置请求头
ROBOTSTXT_OBEY = False #把这个设置成False,就不会去请求网页的robots.txt,因为不改为False的话,scrapy就会去访问该网站的robots.txt协议,如果网站没有这个协议,那么它就不会去访问该网站,就会跳过,进而爬不到数据
ITEM_PIPELINES = {
'haha.pipelines.HahaPipeline': 300,
}
DOWNLOADER_MIDDLEWARES = {
'haha.middlewares.seleniumDownloaderMiddleware': 543,
}
最后在cmd中先进入到这个项目的根目录下,即有scrapy.cfg文件的目录下,然后输入并运行scrapy crawl tt,最后静静等待就行了
六、数据展示
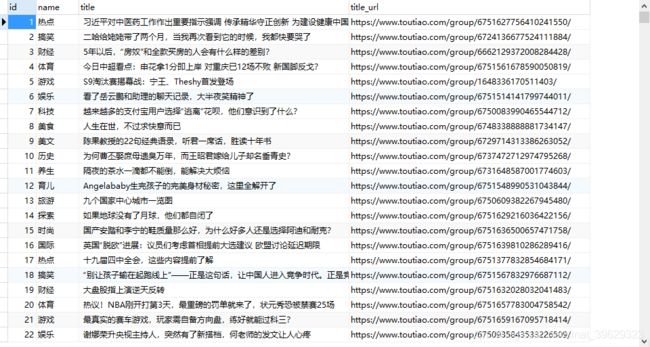
经过几分钟后,数据库里面会出现以下数据:
写在最后
这次主要是想在scrapy中实现selenium来处理请求返回动态加载的网页数据,进而在scrapy中完美爬取动态页面,不过,你会发现它是等所有的网页请求完毕之后才会有输出,这个问题待解决,不过只要代码写正确了,也不影响哈哈,除非网络断了那数据就不能及时保存,爬虫就白跑了,关键一点这里不能用异步保存数据,会保存有重复的数据目前由于时间的原因,我没有再去探究这个问题,希望有大佬给我指点指点