PyTorch笔记7-optimizer
本系列笔记为莫烦PyTorch视频教程笔记 github源码
概要
Torch 提供了几种 optimizer,如:SGD, Momentum, RMSprop, Adam
SGD: stochastic gradient descent,随机梯度下降,每次迭代只训练一个样本,不能利用 CPU 或 GPU 并行计算 speed up,且每个样本都进行gradient descent,这无疑增加了样本中的概率,所以学习速度较慢, 但是要注意,在 PyTorch 中,SGD optimizer in PyTorch actually is Mini-batch Gradient Descent with momentum
Momentum: 学习速度快于标准的 gradient descent,基本思想是:计算 gradient 的 exponentially weighted average,并利用该 average 来 update weight
Momentum 可以这样理解:把要优化的 cost function 想象为一个碗状函数,梯度 dw, db 想象为给一个在碗表面的小球提供了初速度,而 Momentum(Vdw, Vdb)相当于提供了加速度。在 PyTorch 中,SGD optimizer 实际上封装 了 带 Momentum 的 SGD,通过出入设置 momentum > 0 这个参数即可实现 Momentum 算法。RMSporp: root mean square prop, 基本思想跟 Momentum 类似,只是具体的计算形式跟 Momentum 不同而已
Adam: Adam 可以理解为 Momentum + RMSprop, Adam 被证明能有效使用不同神经网络,适用广泛的结构
下面演示 Torch 中的各种 optimizer
import torch
import torch.utils.data as Data
import torch.nn.functional as F # activation function
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # reproducible
%matplotlib inline伪数据
生成一些伪数据来演示各种 optimizer 的 performance
# fake data
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1) # shape (1000, 1)
# *x.size() --> 1000 1, x.size()-->torch.Size([1000, 1])
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
# plot
plt.scatter(x.numpy(), y.numpy())
plt.show()
# MINI BATCH
MINIBATCH_SIZE = 32
# first transform data to dataset that can be processed by torch
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=MINIBATCH_SIZE,
shuffle=True,
num_workers=2
)为每种 optimizer 构造一个NN
为了对比每种 optimizer,为它们各自创建一个神经网络,且该神经网络来自同一个 Net architecture
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x)
return x
# build net for optimizer
net_SGD, net_Momentum, net_RMSprop, net_Adam = Net(), Net(), Net(), Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]optimizer
接下来构建用不同的 optimizer,并创建一个 loss_func 用来计算 cost
# different optimizers
LR = 0.01
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # store losstrain & plot
接下来训练和出图
EPOCH = 12
for epoch in range(EPOCH):
for step, (batch_x, batch_y) in enumerate(loader):
b_x, b_y = Variable(batch_x), Variable(batch_y) # only Variable can be train
# train
for net, opt, l_his in zip(nets, optimizers, losses_his):
predict = net(b_x) # get output for every net
loss = loss_func(predict, b_y) # compute loss for every net
opt.zero_grad() # clear gradient for next train
loss.backward() # compute gradient
opt.step() # udpate paramters by gradient
l_his.append(loss.data[0]) # store loss
# plot
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('steps')
plt.ylabel('loss')
plt.ylim((0, 0.2))
plt.show()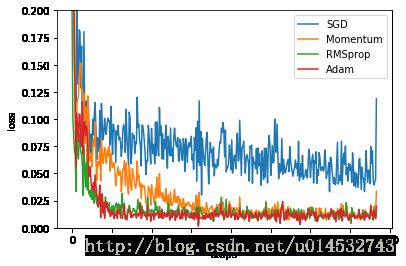
SGD 是最普通的优化器, 也可以说没有加速效果, 而 Momentum 是 SGD 的改良版, 它加入了动量原则. 后面的 RMSprop 又是 Momentum 的升级版. 而 Adam 又是 RMSprop 的升级版. 不过从这个结果中我们看到, Adam 的效果似乎比 RMSprop 要差一点. 所以说并不是越先进的优化器, 结果越佳. 我们在自己的试验中可以尝试不同的优化器, 找到那个最适合你数据/网络的优化器.