PyTorch 学习笔记(五):Finetune和各层定制学习率
本文截取自一个github上千星的火爆教程——《PyTorch 模型训练实用教程》,教程内容主要为在 PyTorch 中训练一个模型所可能涉及到的方法及函数的详解等,本文为作者整理的学习笔记(五),后续会继续更新这个系列,欢迎关注。
项目代码:https://github.com/tensor-yu/PyTorch_Tutorial
系列回顾:
PyTorch 学习笔记(一):让PyTorch读取你的数据集
PyTorch 学习笔记(二):PyTorch的数据增强与数据标准化
PyTorch 学习笔记(三):transforms的二十二个方法
PyTorch 学习笔记(四):权值初始化的十种方法
一个良好的权值初始化,可以加快收敛速度,甚至可以获得更好的精度。而在实际应用中,我们通常采用预训练模型的权值参数作为我们模型的初始化参数,也称之为Finetune,更广泛的称之为迁移学习。迁移学习中的Finetune技术,本质上就是让我们新构建的模型,拥有一个较好的权值初始值。
finetune权值初始化三步曲,finetune就相当于给模型进行初始化,其流程共用三步:
第一步:保存模型,拥有一个预训练模型;
第二步:加载模型,把预训练模型中的权值取出来;
第三步:初始化,将权值对应的“放”到新模型中
一、Finetune之权值初始化
在进行finetune之前我们需要拥有一个模型或者是模型参数,因此需要了解如何保存模型。官方文档中介绍了两种保存模型的方法,一种是保存整个模型,另外一种是仅保存模型参数(官方推荐用这种方法),这里采用官方推荐的方法。
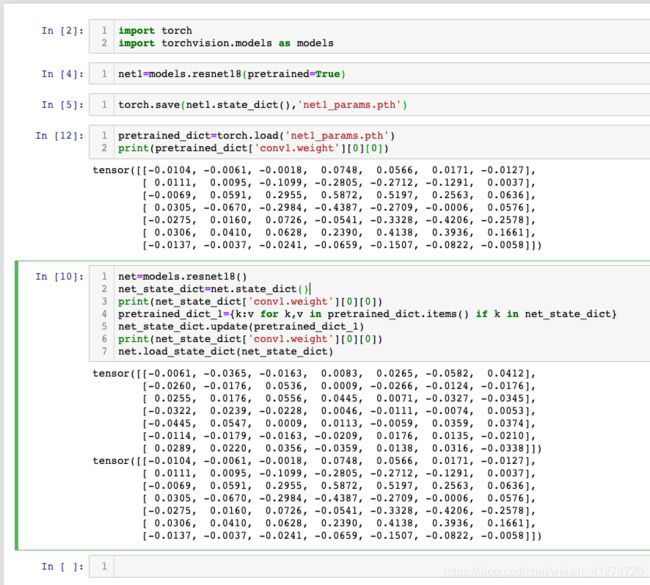
第一步:保存模型参数
# 若拥有模型参数,可跳过这一步。
# 假设创建了一个net = Net(),并且经过训练,通过以下方式保存:
torch.save(net.state_dict(), 'net_params.pth')
第二步:加载模型
# 进行三步曲中的第二步,加载模型,这里只是加载模型的参数:
pretrained_dict = torch.load('net_params.pth')
第三步:初始化
# 进行三步曲中的第三步,将取到的权值,对应的放到新模型中:
# 首先我们创建新模型,并且获取新模型的参数字典net_state_dict:
net = Net() # 创建net
net_state_dict = net.state_dict() # 获取已创建net的state_dict
# 接着将pretrained_dict里不属于net_state_dict的键剔除掉:
pretrained_dict_1 = {k: v for k, v in pretrained_dict.items() if k in net_state_dict}
# 然后,用预训练模型的参数字典 对 新模型的参数字典net_state_dict 进行更新:
net_state_dict.update(pretrained_dict_1)
# 最后,将更新了参数的字典 “放”回到网络中:
net.load_state_dict(net_state_dict)
这样,利用预训练模型参数对新模型的权值进行初始化过程就做完了。
下面我们模拟一下上述过程。
采用finetune的训练过程中,有时候希望前面层的学习率低一些,改变不要太大,而后面的全连接层的学习率相对大一些。这时就需要对不同的层设置不同的学习率,下面就介绍如何为不同层配置不同的学习率。
二、不同层设置不同的学习率
在利用pre-trained model的参数做初始化之后,我们可能想让fc层更新相对快一些,而希望前面的权值更新小一些,这就可以通过为不同的层设置不同的学习率来达到此目的。
为不同层设置不同的学习率,主要通过优化器对多个参数组进行设置不同的参数。
所以,只需要将原始的参数组,划分成两个,甚至更多的参数组,然后分别进行设置学习率。
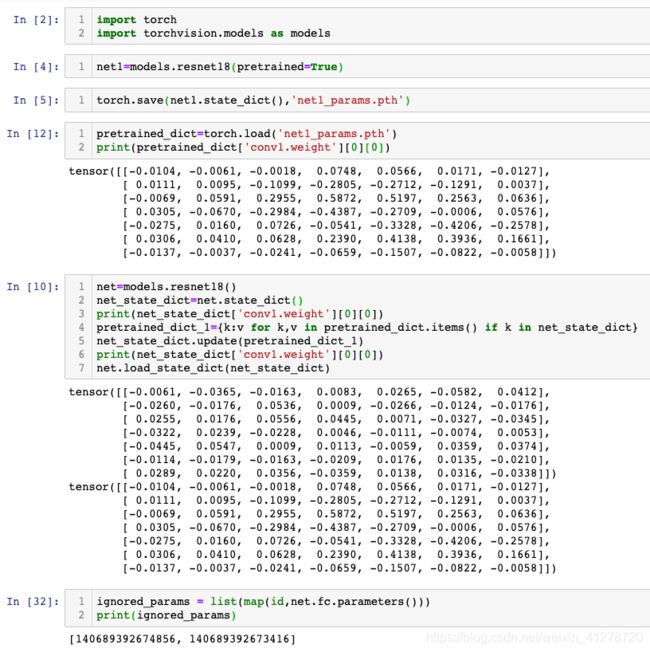
这里将原始参数“切分”成fc3层参数和其余参数,为fc3层设置更大的学习率。
请看代码:
ignored_params = list(map(id, net.fc3.parameters())) # 返回的是parameters的 内存地址
base_params = list(filter(lambda p: id(p) not in ignored_params, net.parameters()))
optimizer = optim.SGD([
{'params': base_params},
{'params': net.fc3.parameters(), 'lr': 0.001*10}], 0.001, momentum=0.9, weight_decay=1e-4)
第一行,取得net.fc3.parameters()的id(即内存地址)
第二行,根据内存地址将ignore_params从net.parameters()中剔除,得到base_params
合起来就是,将fc3层的参数net.fc3.parameters()从原始参数net.parameters()中剥离出来
base_params就是剥离了fc3层的参数的其余参数,然后在优化器中为fc3层的参数单独设定学习率。
optimizer = optim.SGD(…)这里的意思就是 base_params中的层,用 0.001, momentum=0.9, weight_decay=1e-4
fc3层设定学习率为: 0.001*10
完整代码位于 :
https://github.com/tensor-yu/PyTorch_Tutorial/blob/master/Code/2_model/2_finetune.py
补充:
挑选出特定的层的机制是利用内存地址作为过滤条件,将需要单独设定的那部分参数,从总的参数中剔除。
ignored_params = list(map(id, net.fc3.parameters()))中,net.fc3.parameters() 是一个
简单模拟

参考资料
PyTorch 学习笔记(五):Finetune和各层定制学习率
PyTorch学习笔记