百度PaddlePaddle——深度学习7日入门-CV疫情特辑之口罩分类
说明
✓代码跑通
请大家根据课上所学内容,在 VGGNet类中补全代码,构造VGG网络,保证程序跑通。在VGG构造成功的基础上,可尝试构造其他网络。
✓调优
思考并动手进行调优,以在验证集上的准确率为评价指标,验证集上准确率越高,得分越高!
任务描述:
口罩识别,是指可以有效检测在密集人流区域中携带和未携戴口罩的所有人脸,同时判断该者是否佩戴口罩。通常由两个功能单元组成,可以分别完成口罩人脸的检测和口罩人脸的分类。
本次实践相比生产环境中口罩识别的问题,降低了难度,仅实现人脸口罩判断模型,可实现对人脸是否佩戴口罩的判定。本实践旨在通过一个口罩识别的案列,让大家理解和掌握如何使用飞桨动态图搭建一个经典的卷积神经网络
特别提示:本实践所用数据集均来自互联网,请勿用于商务用途。
代码
引入依赖库
import os
import zipfile
import random
import json
import paddle
import sys
import numpy as np
from PIL import Image
from PIL import ImageEnhance
import paddle.fluid as fluid
from multiprocessing import cpu_count
import matplotlib.pyplot as plt
from paddle.fluid.dygraph import Linear参数配置
'''
参数配置
'''
train_parameters = {
"input_size": [3, 224, 224], #输入图片的shape
"class_dim": -1, #分类数
"src_path":"/home/aistudio/work/maskDetect.zip",#原始数据集路径
"target_path":"/home/aistudio/data/", #要解压的路径
"train_list_path": "/home/aistudio/data/train.txt", #train.txt路径
"eval_list_path": "/home/aistudio/data/eval.txt", #eval.txt路径
"readme_path": "/home/aistudio/data/readme.json", #readme.json路径
"label_dict":{}, #标签字典
"num_epochs": 20, #训练轮数
"train_batch_size": 50, #训练时每个批次的大小
"learning_strategy": { #优化函数相关的配置
"lr": 0.0001 #超参数学习率
}
}数据准备
(1)解压原始数据集
(2)按照比例划分训练集与验证集
(3)乱序,生成数据列表
(4)构造训练数据集提供器和验证数据集提供器
def unzip_data(src_path,target_path):
'''
解压原始数据集,将src_path路径下的zip包解压至data目录下
'''
if(not os.path.isdir(target_path + "maskDetect")):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()参数初始化
'''
参数初始化
'''
src_path=train_parameters['src_path']
target_path=train_parameters['target_path']
train_list_path=train_parameters['train_list_path']
eval_list_path=train_parameters['eval_list_path']
batch_size=train_parameters['train_batch_size']
数据增强
#数据增强
def flip(root_path,img_name): #翻转图像
img = Image.open(os.path.join(root_path, img_name))
filp_img = img.transpose(Image.FLIP_LEFT_RIGHT)
# filp_img.save(os.path.join(root_path,img_name.split('.')[0] + '_flip.jpg'))
return filp_img
def rotation_1(root_path, img_name):
img = Image.open(os.path.join(root_path, img_name))
rotation_img = img.rotate(20) #旋转角度
# rotation_img.save(os.path.join(root_path,img_name.split('.')[0] + '_rotation.jpg'))
return rotation_img
def rotation_2(root_path, img_name):
img = Image.open(os.path.join(root_path, img_name))
rotation_img = img.rotate(-20) #旋转角度
# rotation_img.save(os.path.join(root_path,img_name.split('.')[0] + '_rotation.jpg'))
return rotation_img
def randomColor(root_path, img_name): #随机颜色
"""
对图像进行颜色抖动
:param image: PIL的图像image
:return: 有颜色色差的图像image
"""
image = Image.open(os.path.join(root_path, img_name))
random_factor = np.random.randint(0, 31) / 10. # 随机因子
color_image = ImageEnhance.Color(image).enhance(random_factor) # 调整图像的饱和度
random_factor = np.random.randint(10, 21) / 10. # 随机因子
brightness_image = ImageEnhance.Brightness(color_image).enhance(random_factor) # 调整图像的亮度
random_factor = np.random.randint(10, 21) / 10. # 随机因子
contrast_image = ImageEnhance.Contrast(brightness_image).enhance(random_factor) # 调整图像对比度
random_factor = np.random.randint(0, 31) / 10. # 随机因子
sharpness_image = ImageEnhance.Sharpness(contrast_image).enhance(random_factor) # 调整图像锐度
return sharpness_image
def data_auga(imageDir,saveDir):
for name in os.listdir(imageDir):
img = Image.open(os.path.join(imageDir, name))
if img.mode != 'RGB':
img = img.convert('RGB')
img.save(os.path.join(saveDir,name))
saveName="flip-"+name
saveImage=flip(imageDir,name)
if saveImage.mode != 'RGB':
saveImage = saveImage.convert('RGB')
saveImage.save(os.path.join(saveDir,saveName))
saveName="rotation_1-"+name
saveImage=rotation_1(imageDir,name)
if saveImage.mode != 'RGB':
saveImage = saveImage.convert('RGB')
saveImage.save(os.path.join(saveDir,saveName))
saveName="rotation_2-"+name
saveImage=rotation_2(imageDir,name)
if saveImage.mode != 'RGB':
saveImage = saveImage.convert('RGB')
saveImage.save(os.path.join(saveDir,saveName))
'''
saveName="randomColor-"+name
saveImage=randomColor(imageDir,name)
if saveImage.mode != 'RGB':
saveImage = saveImage.convert('RGB')
saveImage.save(os.path.join(saveDir,saveName))'''
训练集和测试集
def data_aug(target_path):
data_list_path = target_path+"maskDetect/"
class_dirs = os.listdir(data_list_path)
for class_dir in class_dirs:
if class_dir != ".DS_Store":
if class_dir == "maskimages": # 每10张图片取一个做验证数据
data_auga("data/maskDetect/maskimages/","data/new-maskDetect/new_maskimages/")
else:
data_auga("data/maskDetect/nomaskimages/","data/new-maskDetect/new_nomaskimages/")
生成数据列表
def get_data_list(target_path,train_list_path,eval_list_path):
'''
生成数据列表
'''
#存放所有类别的信息
class_detail = []
#获取所有类别保存的文件夹名称
new_data_list_path=target_path+"new-maskDetect/"
class_dirs = os.listdir(new_data_list_path)
#总的图像数量
all_class_images = 0
#存放类别标签
class_label=0
#存放类别数目
class_dim = 0
#存储要写进eval.txt和train.txt中的内容
trainer_list=[]
eval_list=[]
#读取每个类别,['maskimages', 'nomaskimages']
for class_dir in class_dirs:
if class_dir != ".DS_Store":
class_dim += 1
#每个类别的信息
class_detail_list = {}
eval_sum = 0
trainer_sum = 0
#统计每个类别有多少张图片
class_sum = 0
#获取类别路径
path = new_data_list_path + class_dir
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths: # 遍历文件夹下的每个图片
name_path = path + '/' + img_path # 每张图片的路径
if class_sum % 10 == 0: # 每10张图片取一个做验证数据
eval_sum += 1 # test_sum为测试数据的数目
eval_list.append(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
trainer_list.append(name_path + "\t%d" % class_label + "\n")#trainer_sum测试数据的数目
class_sum += 1 #每类图片的数目
all_class_images += 1 #所有类图片的数目
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir #类别名称,如jiangwen
class_detail_list['class_label'] = class_label #类别标签
class_detail_list['class_eval_images'] = eval_sum #该类数据的测试集数目
class_detail_list['class_trainer_images'] = trainer_sum #该类数据的训练集数目
class_detail.append(class_detail_list)
#初始化标签列表
train_parameters['label_dict'][str(class_label)] = class_dir
class_label += 1
#初始化分类数
train_parameters['class_dim'] = class_dim
print(class_dim)
#乱序
random.shuffle(eval_list)
with open(eval_list_path, 'a') as f:
for eval_image in eval_list:
f.write(eval_image)
random.shuffle(trainer_list)
with open(train_list_path, 'a') as f2:
for train_image in trainer_list:
f2.write(train_image)
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = new_data_list_path #文件父目录
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(train_parameters['readme_path'],'w') as f:
f.write(jsons)
print ('生成数据列表完成!')自定义reader
def custom_reader(file_list):
'''
自定义reader
'''
def reader():
with open(file_list, 'r') as f:
lines = [line.strip() for line in f]
for line in lines:
img_path, lab = line.strip().split('\t')
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
yield img, int(lab)
return reader解压数据、构造数据提供器
'''
解压原始数据到指定路径
'''
unzip_data(src_path,target_path)
'''
划分训练集与验证集,乱序,生成数据列表
'''
#每次生成数据列表前,首先清空train.txt和eval.txt
with open(train_list_path, 'w') as f:
f.seek(0)
f.truncate()
with open(eval_list_path, 'w') as f:
f.seek(0)
f.truncate()
#生成数据列表
data_aug(target_path)
get_data_list(target_path,train_list_path,eval_list_path)
'''
构造数据提供器
'''
train_reader = paddle.batch(custom_reader(train_list_path),
batch_size=batch_size,
drop_last=True)
eval_reader = paddle.batch(custom_reader(eval_list_path),
batch_size=batch_size,
drop_last=True)模型配置
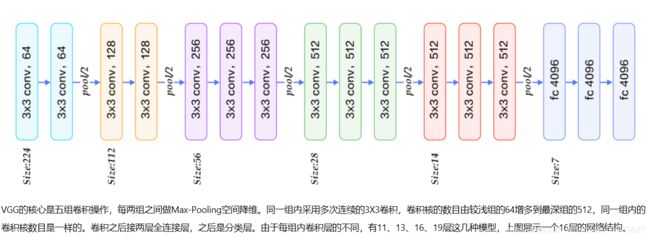
卷积+池化函数定义
class ConvPool(fluid.dygraph.Layer):
'''卷积+池化'''
def __init__(self,
num_channels,
num_filters,
filter_size,
pool_size,
pool_stride,
groups,
conv_stride=1,
conv_padding=1,
act=None,
pool_type='max'
):
super(ConvPool, self).__init__()
self._conv2d_list = []
for i in range(groups):
conv2d = self.add_sublayer( #返回一个由所有子层组成的列表。
'bb_%d' % i,
fluid.dygraph.Conv2D(
num_channels=num_channels, #通道数
num_filters=num_filters, #卷积核个数
filter_size=filter_size, #卷积核大小
stride=conv_stride, #步长
padding=conv_padding, #padding大小,默认为0
act=act)
)
num_channels= num_filters
self._conv2d_list.append(conv2d)
self._pool2d = fluid.dygraph.Pool2D(
pool_size=pool_size, #池化核大小
pool_type=pool_type, #池化类型,默认是最大池化
pool_stride=pool_stride, #池化步长
)
def forward(self, inputs):
x = inputs
for conv in self._conv2d_list:
x = conv(x)
x = self._pool2d(x)
return xVGG网络的定义
class VGGNet(fluid.dygraph.Layer):
'''
VGG网络
'''
def __init__(self):
super(VGGNet, self).__init__()
#num_channels,num_filters,filter_size,pool_size,pool_stride,groups,pool_padding,pool_type,conv_stride,conv_padding,act
#通道数,卷积核数,卷积核大小,池化大小,池化步长,卷积次数,池化padding,池化类型,卷积步长,卷积padding,激活类型。
self.hidden1 = ConvPool(3,64,3,2,2,2,act="relu")
self.hidden2 = ConvPool(64,128,3,2,2,2,act="relu")
self.hidden3 = ConvPool(128,256,3,2,2,3,act="relu")
self.hidden4 = ConvPool(256,512,3,2,2,3,act="relu")
self.hidden5 = ConvPool(512,512,3,2,2,3,act="relu")
self.pool_5_shape=512*7*7
self.hidden6 = Linear(self.pool_5_shape,4096,act="relu")
self.hidden7 = Linear(4096,4096,act="relu")
self.hidden8 = Linear(4096,2,act="softmax")
def forward(self, inputs, label=None):
"""前向计算"""
#print(inputs.shape)
out = self.hidden1(inputs)
out = self.hidden2(out)
out = self.hidden3(out)
out = self.hidden4(out)
out = self.hidden5(out)
out = fluid.layers.reshape(out,shape=[-1,512*7*7])
out = self.hidden6(out)
out = self.hidden7(out)
out = self.hidden8(out)
if label is not None:
acc= fluid.layers.accuracy(input=out,label=label)
return out,acc
else:
return out模型训练
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
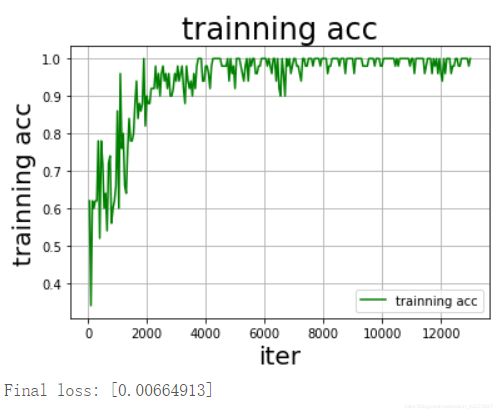
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data,color=color,label=label)
plt.legend()
plt.grid()
plt.show()'''
模型训练
'''
#with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):
with fluid.dygraph.guard():
print(train_parameters['class_dim'])
print(train_parameters['label_dict'])
vgg = VGGNet()
optimizer=fluid.optimizer.AdamOptimizer(learning_rate=train_parameters['learning_strategy']['lr'],parameter_list=vgg.parameters())
for epoch_num in range(train_parameters['num_epochs']):
for batch_id, data in enumerate(train_reader()):
dy_x_data = np.array([x[0] for x in data]).astype('float32')
y_data = np.array([x[1] for x in data]).astype('int64')
y_data = y_data[:, np.newaxis]
#将Numpy转换为DyGraph接收的输入
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
out,acc = vgg(img,label)
loss = fluid.layers.cross_entropy(out, label)
avg_loss = fluid.layers.mean(loss)
#使用backward()方法可以执行反向网络
avg_loss.backward()
optimizer.minimize(avg_loss)
#将参数梯度清零以保证下一轮训练的正确性
vgg.clear_gradients()
all_train_iter=all_train_iter+train_parameters['train_batch_size']
all_train_iters.append(all_train_iter)
all_train_costs.append(loss.numpy()[0])
all_train_accs.append(acc.numpy()[0])
if batch_id % 10 == 0:
print("Loss at epoch {} step {}: {}, acc: {}".format(epoch_num, batch_id, avg_loss.numpy(), acc.numpy()))
draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
draw_process("trainning loss","red",all_train_iters,all_train_costs,"trainning loss")
draw_process("trainning acc","green",all_train_iters,all_train_accs,"trainning acc")
#保存模型参数
fluid.save_dygraph(vgg.state_dict(), "vgg")
print("Final loss: {}".format(avg_loss.numpy()))输出
Loss at epoch 0 step 0: [0.6781367], acc: [0.62]
Loss at epoch 0 step 10: [0.6586403], acc: [0.6]
Loss at epoch 1 step 0: [0.6643871], acc: [0.72]
Loss at epoch 1 step 10: [0.4043163], acc: [0.8]
Loss at epoch 2 step 0: [0.54546624], acc: [0.76]
Loss at epoch 2 step 10: [0.26674366], acc: [0.88]
Loss at epoch 3 step 0: [0.3002169], acc: [0.9]
Loss at epoch 3 step 10: [0.10048617], acc: [0.96]
Loss at epoch 4 step 0: [0.13937579], acc: [0.96]
Loss at epoch 4 step 10: [0.07831122], acc: [0.96]
Loss at epoch 5 step 0: [0.20240352], acc: [0.88]
Loss at epoch 5 step 10: [0.04829586], acc: [1.]
Loss at epoch 6 step 0: [0.13690934], acc: [0.94]
Loss at epoch 6 step 10: [0.0467197], acc: [1.]
Loss at epoch 7 step 0: [0.05981888], acc: [0.98]
Loss at epoch 7 step 10: [0.00501409], acc: [1.]
Loss at epoch 8 step 0: [0.05218565], acc: [0.96]
Loss at epoch 8 step 10: [0.07819565], acc: [0.96]
Loss at epoch 9 step 0: [0.05089414], acc: [1.]
Loss at epoch 9 step 10: [0.26118517], acc: [0.94]
Loss at epoch 10 step 0: [0.21141733], acc: [0.9]
Loss at epoch 10 step 10: [0.00512533], acc: [1.]
Loss at epoch 11 step 0: [0.1195049], acc: [0.96]
Loss at epoch 11 step 10: [0.04839851], acc: [1.]
Loss at epoch 12 step 0: [0.01893314], acc: [1.]
Loss at epoch 12 step 10: [0.00199971], acc: [1.]
Loss at epoch 13 step 0: [0.00656221], acc: [1.]
Loss at epoch 13 step 10: [0.00896903], acc: [1.]
Loss at epoch 14 step 0: [0.00773319], acc: [1.]
Loss at epoch 14 step 10: [0.01701871], acc: [1.]
Loss at epoch 15 step 0: [0.02368888], acc: [1.]
Loss at epoch 15 step 10: [0.00347399], acc: [1.]
Loss at epoch 16 step 0: [0.02928501], acc: [0.98]
Loss at epoch 16 step 10: [0.03078933], acc: [0.98]
Loss at epoch 17 step 0: [0.06260974], acc: [0.96]
Loss at epoch 17 step 10: [0.00022023], acc: [1.]
Loss at epoch 18 step 0: [0.00179655], acc: [1.]
Loss at epoch 18 step 10: [0.01840296], acc: [1.]
Loss at epoch 19 step 0: [0.12508206], acc: [0.98]
Loss at epoch 19 step 10: [0.01097393], acc: [1.]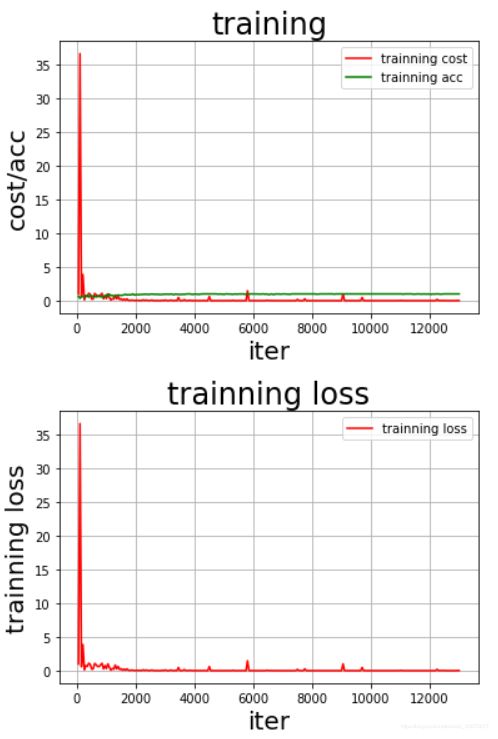
模型校验
'''
模型校验
'''
with fluid.dygraph.guard():
model, _ = fluid.load_dygraph("vgg")
vgg = VGGNet()
vgg.load_dict(model)
vgg.eval()
accs = []
for batch_id, data in enumerate(eval_reader()):
dy_x_data = np.array([x[0] for x in data]).astype('float32')
y_data = np.array([x[1] for x in data]).astype('int')
y_data = y_data[:, np.newaxis]
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
out, acc = vgg(img, label)
lab = np.argsort(out.numpy())
accs.append(acc.numpy()[0])
print(np.mean(accs))输出:1.0
模型预测
def load_image(img_path):
'''
预测图片预处理
'''
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
return img
label_dic = train_parameters['label_dict']
'''
模型预测
'''
with fluid.dygraph.guard():
model, _ = fluid.dygraph.load_dygraph("vgg")
vgg = VGGNet()
vgg.load_dict(model)
vgg.eval()
#展示预测图片
infer_path='/home/aistudio/data/data23615/infer_mask01.jpg'
img = Image.open(infer_path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
#对预测图片进行预处理
infer_imgs = []
infer_imgs.append(load_image(infer_path))
infer_imgs = np.array(infer_imgs)
for i in range(len(infer_imgs)):
data = infer_imgs[i]
dy_x_data = np.array(data).astype('float32')
dy_x_data=dy_x_data[np.newaxis,:, : ,:]
img = fluid.dygraph.to_variable(dy_x_data)
out = vgg(img)
lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
print("第{}个样本,被预测为:{}".format(i+1,label_dic[str(lab)]))
print("结束")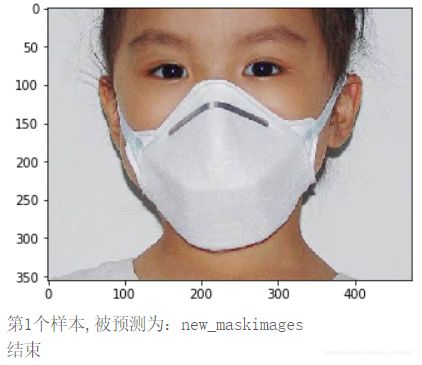
总结:
通过一周的简单学习,感谢各位老师的悉心答疑,为小班班点赞,为靳老师点赞!
如果大家自己的算力不足的话,推荐大家可以尝试使用百度推出的平台,百度大脑AI Studio是面向AI学习者的一站式开发实训平台,平台集成了丰富的免费AI课程,深度学习样例项目,各领域经典数据集,云端超强GPU算力及存储资源,更有新手练习赛、精英算法大赛。个人认为挺好用的。
AI小学生
注:代码源于飞桨平台,本人在其基础上进行了添加和改动。