mybatis总结
Mybatis总结
这里写目录标题
- Mybatis总结
- 一、mybatis框架简介
- 1、简介
- 2、特点
- 二、Mybatis环境搭建
- 1、导入jar包
- 2、配置文件
- 2.1、Mybatis配置文件
- 2.2、关联本地dtd文件方法
- 2.3、mybatis.xml配置文件
- 2.4、mybatis SQL映射文件
- 2.5、测试
- 2.6、Log4J日志
- 2.7、properties标签的使用
- 2.8、typeAliases标签
- 3、工具类的封装与事务
- 三、Mapper代理CRUD
- 1、DML(增删改)
- 2、普通三种查询
- 3、接口绑定方案
- 2.1、多种传入参数
- 2.2、分页参数
- 2.3、自增主键回填
- 2.4、动态SQL
- 2.4.1、if
- 2.4.2、where
- 2.4.3、bind
- 2.4.4、set和trim
- 2.4.5、foreach
- 2.5、批量DML(增删改)
- 四、缓存
- 1、一级缓存
- 2、二级缓存
- 五、多表联查
- 1、一对一关联查询
- 2、一对多关联查询
- 3、多对多关联查询
- 六、级联查询
- 1、积极加载
- 2、延迟加载
- 3、总结
- 七、注解开发
一、mybatis框架简介
1、简介
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apachesofware foundation 迁移到了google code,并且改名为MyBatis 。2013年11月迁移到Github。iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架。iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAO)MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架。MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装。MyBatis可以使用简单的XML或注解用于配置和原始映射,将接口和Java的POJO(Plain Old Java Objects,普通的Java对象)映射成数据库中的记录。Mybatis不是一个完全的orm框架,Mybatis需要程序员自己写sql,但是也存在映射(输入参数映射,输出结果映射),学习门槛mybatis比hibernate低;同时灵活性高,特别适用于业务模型易变的项目,使用范围广。
简单概括:
更加简化jdbc代码,简化持久层,sql语句从代码中分离,利用反射,将表中数据与java bean 属性一一映射 即 ORM(Object Relational Mapping 对象关系映射)
使用范围:
在日常的开发项目中,如中小型项目,例如ERP,需求与关系模型相对固定建议使用Hibernate,对于需求不固定的项目,比如:互联网项目,建议使用mybatis,因为需要经常灵活去编写sql语句。总之,mybatis成为当下必须学习掌握的一个持久层框架。
MyBatis 功能架构图:

从上面我们可以看到mybatis的功能架构分为三层:
API接口层:提供给外部使用的接口API,开发人员通过这些本地API来操纵
数据库。接口层接收到调用请求就会调用数据处理层来完成具体的数据处
理。
数据处理层:负责具体的SQL查 找、SQL解析、SQL执行和执行结果映射处
理等。它主要的目的是根据调用的请求完成一次数据库操作。
基础支撑层:负责最基础的功能支撑,包括连接管理、事务管理、配置加
载和缓存处理,这些都是共用的东西,将他们抽取出来作为最基础的组
件。为上层的数据处理层提供最基础的支撑。
2、特点
属于持久层ORM框架
- 持久层: 讲内存中对象数据,转移到数据库中的过程持久层
Mybatis Hibernate Spring-jpa - ORM Object Relational Mapping 对象关系映射框架
类 表
属性 字段
对象 记录 - 半自化 自动化
Mybatis 半自动化
表需要手动进行设计
提供sql
依赖与数据库平台
优点:学习使用简单(基与原声jdbc封装),优化灵活,适合做互联网
项目
Hibernate 自动化ORM框架
表可以通过框架自动创建
省略一些基本的sql
不依赖与数据库平台
缺点: 学生成本高,优化难度大,适合与传统框(OA|图书管理系
统…),不适合做大型互联网项目
二、Mybatis环境搭建
官网地址:https://mybatis.org/mybatis-3/zh/index.html
1、导入jar包
1.1、mybatis核心jar包
![]()
1.2、mybatis依赖的jar包

1.3、数据库驱动jar包
导入包方法:idea:复制到该项目lib目录下,然后右键 As Library
eclipse:选中所有的jar包,右键build path->add to build path 管理外部的jar资源
oracle数据库驱动包:
![]()
mysql数据库驱动jar包:
![]()
2、配置文件
2.1、Mybatis配置文件
mybatis提供两种配置文件, 核心配置文件 mybatis-config.xml|mybatis.xml 与SQL映射文件mapper.xml
核心配置文件的添加:xml文件,命名无要求,位置无要求,一般成为mybatis.xml,放在src路径下。
dtd地址:
2.2、关联本地dtd文件方法
2.2.1、解压mybatis核心jar包,找到本地dtd文件
2.2.2、ide工具中关联mybatis配置文件的dtd约束

2.3、mybatis.xml配置文件
2.3.1、核心配置文件
1.configuration
配置文件的根元素,所有其他的元素都要在这个标签下使用(dtd文件规定)
2.environments default=“environment”
用于管理所有环境, 并可以指定默认使用那个环境,通过defualt属性来指定
3.environment
用来配置环境,id属性用于唯一标识当前环境
4.transactionManager type=“JDBC”
用户配置事务管理器
type属性
用来指定Mybatis采用何种方式管理事务
JDBC : 表示采用与原生JDBC一致方式管理事务
MANAGED: 表示讲事务管理交给其他容器进行, Spring
5.dataSource type=“POOLED”
用于配置数据源, 设置Myabtis是否使用连接池技术,并且配置数据库的四个
连接参数
type属性:
POOLED : 表示采用连接池技术
UNPOOLED: 表示每次都会开启和关闭连接, 不采用连接池技术
JNDI : 使用其他容器提供数据源
6.property
用于配置数据库连接参数 (driver,url,username,password)
7.Mappers
用于配置扫描sql映射文件
<configuration>
<environments default="ev">
<environment id="ev">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver"
value="oracle.jdbc.driver.Oracle.Driver"/>
<property name="url" value="jdbc:oracle:thin:@localhost:1521:XE"/>
<property name="username" value="SCOTT"/>
<property name="password" value="TIGER"/>
dataSource>
environment>
environments>
<mappers>
<mapper resource="com/shsxt/mappers/UserMapper.xml"/>
mappers>
configuration>
2.4、mybatis SQL映射文件
MyBatis 的真正强大在于它的映射语句,也是它的魔力所在。由于它的异常强大,映射器的 XML 文件就显得相对简单。如果拿它跟具有相同功能的JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。MyBatis 就是针对 SQL 构建的,并且比普通的方法做的更好。
SQL 映射文件有很少的几个顶级元素(按照它们应该被定义的顺序):
resultMap – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。
insert – 映射插入语句
update – 映射更新语句
delete – 映射删除语句
select – 映射查询语句
查询语句是 MyBatis 中最常用的元素之一(映射文件配置见代码)
1.mapper
SQL映射文件的根元素
namespace 属性
用于指定命名空间, mydatis通过namespace+id的方式用来定位sql语句,所以必须要指定namespace,通过被配置为权限定路径 包名+xml文件名(不带后缀名)
2.select
用来定义查询语句 update insert delete
id 属性
用阿里唯一表示当前sql语句,在当前的命名空间中唯一,不能重复 , 类型方法名
resultType 属性
用于设定查询返回的结果的数据类型,要写类型的权限定名(包名+类名),如果返回值的是集合类型,要定义集合的泛型类型
在Mybatis中,推荐使用mappers作为包名,我们只需要写一个映射配置文件就可以,UserMapper.xml,用于定义要执行的sql语句,同时可以设置参数|返回值结果类型
<mapper namespace="com.shsxt.mappers.UserMapper">
<select id="queryAll" resultType="com.shsxt.pojo.User">
select * from t_user
select>
mapper>
注意:不要忘记mybatis核心xml文件中的mapper配置
2.5、测试
public class TestUser {
public static void main(String[] args) throws IOException{
//1.加载mybatis全局核心配置文件
InputStream is = Resources.getResourceAsStream("mybatis.xml");
//2.构建SqlSessionFactory对象
SqlSessionFactory factory = newSqlSessionFactoryBuilder().build(is);
//3.通过工厂获取会话SqlSession
SqlSession session = factory.openSession();
//4.通过session调用方法执行查询
//selectList() 查到的数据返回一个list集合,没查到返回空的list
//selectList 的第一个参数为statement: 命名空间+id
List<User> list = session.selectList("com.shsxt.mappers.UserMapper.queryAll");
System.out.println(list);
//5.关闭会话资源
session.close();
}
}
2.6、Log4J日志
2.6.1、简介
日志是应用软件中不可缺少的部分,Apache的开源项目log4j是一个功能强大的日志组件,提供方便的日志记录。在apache网站:jakarta.apache.org/log4j 可以免费下载到Log4j最新版本的软件包。
2.6.2、日志级别
日志五个级别:
DEBUG(人为调试信息)、INFO(普通信息)、WARN(警告)、ERROR(错误)
和FATAL(系统错误)这五个级别是有顺序的,DEBUG < INFO < WARN < ERROR < FATAL,分别用来指定这条日志信息的重要程度,明白这一点很重要,Log4j有一个规则:只输出级别不低于设定级别的日志信息,假设Loggers级别设定为INFO,则INFO、WARN、ERROR和FATAL级别的日志信息都会输出,而级别比INFO低的DEBUG则不会输出。
2.6.3、mybatis开启支持
settings用于设置 MyBatis 在运行时的行为方式, 例如:缓存, 延迟加载, 日志
等.
<settings>
<setting name="logImpl" value="LOG4J"/>
settings>
2.6.3、日志模板
# Set root category priority to INFO and its only appender to CONSOLE.
# log4j.rootCategory=DEBUG, CONSOLE
#log4j.rootCategory=INFO, CONSOLE, LOGFILE
log4j.rootLogger=info,stdout
# 单独设置SQL语句的输出级别为DEBUG级别
# 方法级别
# log4j.logger.com.xxxx.mappers.EmpMapper.queryAll=DEBUG
# 类级别
# log4j.logger.com.xxxx.mappers.EmpMapper=DEBUG
# 包级别
log4j.logger.com.itlazy.mappers=DEBUG
# CONSOLE is set to be a ConsoleAppender using a PatternLayout.
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.err
log4j.appender.stdout.layout=org.apache.log4j.SimpleLayout
# LOGFILE is set to be a File appender using a PatternLayout.
log4j.appender.LOGFILE=org.apache.log4j.FileAppender
log4j.appender.LOGFILE.File=D:/test.log
log4j.appender.LOGFILE.Append=true
log4j.appender.LOGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %F %p %m%n
2.7、properties标签的使用
2.7.1、src下定义配置文件db.properties
#oracle
driver=oracle.jdbc.driver.OracleDriver
url=jdbc:oracle:thin:@localhost:1521:XE
username=SCOTT
password=TIGER
#mysql
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/sxt_stu?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai
username=root
password=root
2.7.2、核心文件的properties标签和使用
mybatis核心配置文件中添加properties标签,指定加载外部的properties文件,注意定义位置
<properties resource="db.properties" />
<environments default="even">
<environment id="even">
<transactionManager type="JDBC">transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
dataSource>
environment>
environments>
2.8、typeAliases标签
用于给JavaBean类型定义别名,方便在配置文件中使用
<typeAliases>
<typeAlias type="com.shsxt.pojo.User" alias="u"/>
typeAliases>
<typeAliases>
<typeAlias type="com.shsxt.pojo.User"/>
typeAliases>
<typeAliases>
<package name="com.shsxt.pojo"/>
typeAliases>
<select id="queryAll" resultType="u">
select id,uname,upwd,birthday from t_user
select>
<select id="queryById" resultType="User">
select id,uname,upwd,birthday from t_user where id=125
select>
Mybatis内建别名:
常见的 Java 类型内建的类型别名。它们都是不区分大小写
的,注意,为了应对原始类型的命名重复,采取了特殊的命名风格。
| 别名 | 映射的类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
3、工具类的封装与事务
如果多个DML操作属于一个事务,因为commit()和rollback()都是由SqlSession完成的,所以必须保证使用一个SqlSession。但是多个不同的DML操作可能在不同类的不同方法中,每个方法中要单独的获取SqlSession。比如商城下订单时,其实涉及商品库存变化、订单添加、订单明细添加、付款、日志添加等多个DML操作,分布在不同类中。
如何在多个DML操作之间使用同一个SqlSession呢,可以使用ThreadLocal来存储。保证一个线程中的操作使用的都是一个SqlSession。
public class SqlSessionUtil {
private static ThreadLocal<SqlSession> th = new ThreadLocal<>();
private static SqlSessionFactory factory = null;
static {
try {
//创建工厂,创建一次即可
factory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader("SqlMapConfig.xml"));
} catch (IOException e) {
e.printStackTrace();
}
}
//获取Sqlsession会话
public static SqlSession getSqlSession(){
SqlSession session = th.get();
if (session==null){
//自动提交事务,默认为false
session = factory.openSession(true);
th.set(session);
}
return session;
}
/**
* 关闭Sqlsession
*/
public static void closeSqlSession(){
SqlSession session = th.get();
if (session!=null){
session.close();
th.set(null);
}
}
}
三、Mapper代理CRUD
如果参数只有一个时parameterType 可以不写,但是写了就要写对
#{} 代表sql语句的执行使用PreparedStatment语句对象
${} 代表sql语句的执行使用Statment语句对象
以后基本使用#{}
1、DML(增删改)
DML操作的底层调用executeUpdate(),返回值都是int类型,不需要提供,也没有resultType属性来指定。其实insert、update、delete任何一个元素都可以完成所有DML操作的映射,底层都一样。
public static void main(String[] args) {
SqlSession session = SqlSessionUtil.getSqlSession();
EmpMapper empMapper = session.getMapper(EmpMapper.class);
Emp emp = new Emp();
//增加数据
emp.setEname("李四");
emp.setJob("asd");
int rows = empMapper.insertEmp(emp);
System.out.println(rows>0?"插入成功":"插入失败");
//修改数据
emp.setEname("ddd");
emp.setEmpno(1020);
emp.setJob("ssss");
int rows = empMapper.updateEmp(emp);
System.out.println(rows>0?"更新成功":"更新失败");
//删除数据
int rows = empMapper.deleteEmpById(1020);
System.out.println(rows>0?"删除成功":"删除失败");
//关闭资源
SqlSessionUtil.closeSqlSession();
}
public interface EmpMapper {
//测试增删改
//添加数据
int insertEmp(Emp emp);
//修改数据
int updateEmp(Emp emp);
//删除数据
int deleteEmpById(int empno);
}
<insert id="insertEmp" parameterType="emp">
insert into emp(empno,ename,job) values(sq_emp_empno.nextval,#{ename},#{job})
insert>
<update id="updateEmp" parameterType="emp">
update emp set ename=#{ename},job=#{job} where empno=#{empno}
update>
<delete id="deleteEmpById" parameterType="_int">
delete from emp where empno=#{empno}
delete>
2、普通三种查询
selectList(“命名空间.id”) 用户查询多条数据情况,返回一个List集合, 没有查到数据返回空集合,不是null
selectOne(“命名空间.id”) 用于查询单条数据,返回一个数据, 如果没有查到返回null
selectMap(“命名空间.id”,key的字段名) 用于查询多条记录情况, 返回Map集合, 需要指定那个属性作为key, sql查询结果作为value,指定的字段值作为key, 如果查不到, 返回一个空map集合,不是null
缺点:
1.不管是selectList()、selectOne()、selectMap(),都只能提供一个查询参数。如果要多个参数,需要封装到JavaBean中,并不一定永远是一个好办法。
2.返回值类型较为固定
3.只提供了映射文件,没有提供数据库操作的接口,不利于后期的维护扩展。
测试代码:
public static void main(String[] args) throws IOException {
SqlSession sqlSession = SqlSessionUtil.getSqlSession();
//根据id查询姓名
String name = sqlSession.selectOne("com.itlazy.mappers.EmpMapper2.selectNameById",7499);
System.out.println(name);
//根据id查询入职日期
Date date = sqlSession.selectOne("com.itlazy.mappers.EmpMapper2.selectDateById",7499);
System.out.println(date);
//根据mgr的selectMap查询Map数据,使用selectMap方法查询时可以查询多个
Map<Integer,Emp> maps = sqlSession.selectMap("com.itlazy.mappers.EmpMapper2.selectMapById",7839,"empno");
System.out.println(maps);
//根据姓名查询Map数据,使用selectOne查询返回map时只能返回一个,要返回多个可以使用selectList返回List<map>数据
Map<String,Object> map1 = sqlSession.selectOne("com.itlazy.mappers.EmpMapper2.selectMapByName","KING");
System.out.println(map1);
//根据姓名模糊查询List数据
List<Emp> list = sqlSession.selectList("com.itlazy.mappers.EmpMapper2.selectListByName","A");
list.forEach(System.out::println);
//根据姓名模糊查询list-map数据
List<String,Object>> list1 = sqlSession.selectList("com.itlazy.mappers.EmpMapper2.selectMapListByName","A");
list1.forEach(System.out::println);
sqlSession.close();
}
xml代码:
3、接口绑定方案
一个mapper的xml文件对应一个接口,名字必须一样,必须放在同一位置。

2.1、多种传入参数
在EmployeeMapper接口中定义方法实现同时按照job、deptno两个字段完成信息查询。可以有四种方式来实现。分别为:
方式1:直接传递多个参数
映射文件中,参数可以使用param1,param2…表示,或者使用arg0,arg1…表 示,可读性低。
方式2:使用Param注解传递多个参数
映射文件中参数可以使用Param注解指定的名称来表示,同时保留使用param1, param2…表示,但是不可以再使用arg0,arg1…表示
方式3:使用JavaBean传递多个参数
映射文件中的参数直接使用JavaBean的属性来接收,可读性高。底层调用是相应 属性的getter方法。
方式4:使用Map传递多个参数
映射文件中使用相应参数在map中的key来表示。
<select id="selectById" parameterType="int" resultType="emp">
select * from emp where empno=#{empno}
select>
<select id="selectByName" parameterType="string" resultType="emp">
select * from emp where ename like '%'||#{ename}||'%'
select>
<select id="selectEmpByJobDeptno" resultType="emp">
select * from emp where job=#{param1} and deptno=#{param2}
select>
<select id="selectByEmp" parameterType="emp" resultType="emp">
select * from emp where ename=#{ename} and sal=#{sal}
select>
<select id="selectByMap" parameterType="map" resultType="emp">
select * from emp where job=#{job} and empno=#{empno}
select>
<select id="selectByList" resultType="emp">
select * from emp where empno in (
<foreach collection="list" item="item" separator=",">
#{item}
foreach>
)
select>
dao代码:
public interface EmpMapper {
//使用id查询
Emp selectById(int id);
//根据姓名模糊查询
List<Emp> selectByName(String name);
//根据部门与工种查询
//不使用注解可以使用param1,param2..和arg0,arg1..来调用参数,有注解则不可以使用arg0,arg1..
List<Emp> selectEmpByJobDeptno(@Param("job") String job,@Param("deptno") Integer deptno);
//根据javaBean查询
List<Emp> selectByEmp(Emp emp);
//根据map查询
Emp selectByMap(Map map);
//根据list查询
List<Emp> selectByList(List<Integer> empnos);
}
java代码:
public static void main(String[] args) {
SqlSession session = SqlSessionUtil.getSqlSession();
EmpMapper empMapper = session.getMapper(EmpMapper.class);
//根据id查询数据
Emp emp = empMapper.selectById(7499);
System.out.println(emp);
//根据姓名查询
List<Emp> list = empMapper.selectByName("A");
list.forEach(System.out::println);
//传入多个参数查询,根据部门与工种查询
List<Emp> emps = empMapper.selectEmpByJobDeptno("CLERK", 30);
emps.forEach(System.out::println);
//根据javaBean查询
Emp e = new Emp();
e.setEname("WARD");
e.setSal(1250.0);
List<Emp> list1 = empMapper.selectByEmp(e);
list1.forEach(System.out::println);
//根据Map查询
Map map = new HashMap();
map.put("job","CLERK");
map.put("empno",7900);
Emp emp1 = empMapper.selectByMap(map);
System.out.println(emp1);
//根据List查询
List l = Arrays.asList(7499,7369,7782);
List<Emp> list3 = empMapper.selectByList(l);
list3.forEach(System.out::println);
session.close();
}
2.2、分页参数
MyBatis不仅提供分页,还内置了一个专门处理分页的类RowBounds,其实就是一个简单的实体类。其中有两个成员变量:
offset:偏移量,从0开始计数
limit:限制条数
在映射文件中不需要接收RowBounds的任何信息,MyBatis会自动识别并据此完成分页 。从控制台显示的SQL日志中发现,SQL语句中也没有引入分页。这说明是MyBatis先查询出所有符合条件的数据,再根据偏移量和限制条数筛选指定内容。所有仅适用小数据量情况,对于大数据的情况,请自己编写分页类来实现。
//接口代码
public interface EmployeeMapper {
public List<Employee> findEmp6(@Param("ename") String ename,
@Param("hireDate") Date hireDate,
RowBounds rowBounds);
public List<Employee> findEmp7(@Param("ename") String ename,
@Param("hireDate") Date hireDate,
@Param("offset") int offset,
@Param("limit") int limit);
}
<select id="findEmp6" resultType="employee">
select * from emp where
ename like concat("%",#{ename},"%") and hiredate < #{hireDate}
select>
<select id="findEmp7" resultType="employee">
select * from emp where
ename like concat("%",#{ename},"%") and hiredate < #{hireDate}
limit #{offset},#{limit}
select>
//测试类代码
RowBounds rowBounds = new RowBounds(4, 3);
List<Employee> list = mapper.findEmp6("A", Date.valueOf("1987-12-1"),rowBounds);
List<Employee> list = mapper.findEmp7("", Date.valueOf("1987-12-23"), 3, 5);
2.3、自增主键回填
MySQL支持主键自增。有时候完成添加后需要立刻获取刚刚自增的主键,由下一个操作来使用。比如结算购物车后,主订单的主键确定后,需要作为后续订单明细项的外键存在。如何拿到主键呢,MyBatis提供了支持,可以非常简单的获取。
mysql数据库:
<insert id="save" useGeneratedKeys="true" keyProperty="empno">
insert into emp
values(null,#{ename},#{job},#{mgr},#{hireDate},#{sal},#{comm},#{deptno})
insert>
<insert id="save" >
<selectKey order="AFTER" keyProperty="empno" resultType="int">
select @@identity
selectKey>
insert into emp (empno,ename,sal)values(null,#{ename},#{sal})
insert>
Oracle数据库:
<insert id="userRegister" keyProperty="sno" useGeneratedKeys="true">
<selectKey resultType="int" keyProperty="sno" order="BEFORE">
select seq_user.nextval as sno from dual
selectKey>
insert into sxt_student(sno,sname,psw,sex,studytime) select #{sno},#{sname},#{psw},#{sex},#{studytime} from dual
insert>
2.4、动态SQL
MyBatis在简化操作方法提出了动态SQL功能,将使用Java代码拼接SQL语句,改变为在XML映射文件中截止标签拼接SQL语句。相比而言,大大减少了代码量,更灵活、高度可配置、利于后期维护。
MyBatis中动态SQL是编写在mapper.xml中的,其语法和JSTL类似,但是却是基于强大的OGNL表达式实现的。MyBatis也可以在注解中配置SQL,但是由于注解功能受限,尤其是对于复杂的SQL语句,可读性很差,所以较少使用。
2.4.1、if
每一个if相当于一个if单分支语句。一般添加一个where 1=1 的查询所有数据的条件,作为第一个条件。这样可以让后面每个if语句的SQL语句都以and开始。
<select id="findByCondition" resultType="emp">
select * from emp where 1=1
<if test="empno != null">
and empno =#{empno}
if>
<if test="ename != null">
and ename like concat('%',#{ename},'%')
if>
<if test="job != null">
and job like concat('%',#{job},'%')
if>
<if test="hiredate != null">
and hiredate =#{hiredate}
if>
<if test="sal != null">
and sal =#{sal}
if>
<if test="comm != null">
and comm =#{comm}
if>
<if test="deptno != null">
and deptno =#{deptno}
if>
select>
2.4.2、where
使用where元素,就不需要提供where 1=1 这样的条件了。如果标签内容不为空字符串则自动添加where关键字,并且会自动去掉第一个条件前面的and或or。
<select id="findByCondition" resultType="emp">
select * from emp
<where>
<if test="empno != null">
and empno =#{empno}
if>
<if test="ename != null">
and ename like concat('%',#{ename},'%')
if>
<if test="job != null">
and job like concat('%',#{job},'%')
if>
<if test="hiredate != null">
and hiredate =#{hiredate}
if>
<if test="sal != null">
and sal =#{sal}
if>
<if test="comm != null">
and comm =#{comm}
if>
<if test="deptno != null">
and deptno =#{deptno}
if>
where>
select>
2.4.3、bind
bind主要的一个重要场合是模糊查询,通过bind通配符和查询值,可以避免使用数据库的具体语法来进行拼接。比如MySQL中通过concat来进行拼接,而Oracle中使用||来进行拼接。
<select id="findByCondition" resultType="emp" parameterType="emp">
select * from emp
<where>
<if test="empno != null">
and empno =#{empno}
if>
<if test="ename != null">
<bind name="enamex" value="'%'+ename+'%'"/>
and ename like #{enamex}
if>
<if test="job != null">
<bind name="jobx" value="'%'+job+'%'"/>
and job like #{jobx}
if>
<if test="hiredate != null">
and hiredate =#{hiredate}
if>
<if test="sal != null">
and sal =#{sal}
if>
<if test="comm != null">
and comm =#{comm}
if>
<if test="deptno != null">
and deptno =#{deptno}
if>
where>
select>
2.4.4、set和trim
set元素用在update语句中给字段赋值。借助if的配置,可以只对有具体值的字段进行更新。set元素会自动帮助添加set关键字,自动去掉最后一个if语句的多余的逗号。
<update id="updateEmp" parameterType="emp">
update emp
<set>
<if test="ename != null">
ename =#{ename},
if>
<if test="job != null">
job = #{job},
if>
<if test="hiredate != null">
hiredate =#{hiredate},
if>
<if test="sal != null">
sal =#{sal},
if>
<if test="comm != null">
comm =#{comm},
if>
<if test="deptno != null">
deptno =#{deptno},
if>
set>
where empno =#{empno}
update>
where 标签和set标签都可以理解为trim的两种特殊情况
trim可以实现在sql语句的前面追加/减少什么文字,在sql语句的后面追加/减少什么文字
<select id="findByCondition" resultType="emp" parameterType="emp">
select * from emp
<trim prefixOverrides="and" prefix="where">
<if test="empno != null">
and empno =#{empno}
if>
<if test="ename != null">
<bind name="enamex" value="'%'+ename+'%'"/>
and ename like #{enamex}
if>
<if test="job != null">
<bind name="jobx" value="'%'+job+'%'"/>
and job like #{jobx}
if>
<if test="hiredate != null">
and hiredate =#{hiredate}
if>
<if test="sal != null">
and sal =#{sal}
if>
<if test="comm != null">
and comm =#{comm}
if>
<if test="deptno != null">
and deptno =#{deptno}
if>
trim>
select>
<update id="updateEmp" parameterType="emp">
update emp
<trim prefix="set" suffixOverrides=",">
<if test="ename != null">
ename =#{ename},
if>
<if test="job != null">
job = #{job},
if>
<if test="hiredate != null">
hiredate =#{hiredate},
if>
<if test="sal != null">
sal =#{sal},
if>
<if test="comm != null">
comm =#{comm},
if>
<if test="deptno != null">
deptno =#{deptno},
if>
trim>
where empno =#{empno}
update>
2.4.5、foreach
foreach 元素是非常强大的,它允许你指定一个集合或者数组,声明集合项和索引变量,它们可以用在元素体内。它也允许你指定开放和关闭的字符串,在迭代之间放置分隔符。这个元素是很智能的,它不会偶然地附加多余的分隔符。
注意 你可以传递一个 List 实例或者数组作为参数对象传给 MyBatis。当你这么做的时候,MyBatis 会自动将它包装在一个 Map 中,用名称在作为键。List 实例将会以“list” 作为键,而数组实例将会以“array”作为键。
查询部门号为 10 20 30 40 … … 的员工信息
<select id="findByDeptnos1" resultType="emp" >
select * from emp where deptno in
<foreach collection="array" item="deptno" open="(" separator="," close=")" >
#{deptno}
foreach>
select>
<select id="findByDeptnos2" resultType="emp" >
select * from emp where deptno in
<foreach collection="list" item="deptno" open="(" separator="," close=")" >
#{deptno}
foreach>
select>
在进行SQL优化是有一点就是建议少使用in语句,因为对性能有影响。如果in中元素很多的话,会对性能有较大影响,此时就不建议使用foreach语句了。
2.5、批量DML(增删改)
<insert id="insertEmpMany">
insert into emp(empno, ename, job)
<foreach collection="list" item="item" separator="union">
select #{item.empno}, #{item.ename}, #{item.job} from dual
foreach>
insert>
<update id="updateEmpMany">
<foreach collection="list" separator=";" item="item" open="begin" close=";end;">
update emp set ename=#{item.ename},job=#{item.job} where empno=#{item.empno}
foreach>
update>
<insert id="deleteEmpMany">
delete from emp where empno in(
<foreach collection="list" item="item" separator=",">
#{item}
foreach>
)
insert>
四、缓存
什么是缓存:
从硬件角度来说:缓存(cache),原始意义是指访问速度比一般随机存取存储器(RAM)快的一种高速存储器,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。缓存的设置是所有现代计算机系统发挥高性能的重要因素之一。
从硬件角度来说:暂时存储数据的一种技术,我们通常将需要反复获取的,又相对稳定的数据通过一些编码手段暂时的存储起来,再次获取数据时,我们直接到缓存中获取数据,可以降低IO的读写次数数据库的访问次数,提高效率.
缓存的重要性是不言而喻的。将相同查询条件的SQL语句执行一遍后所得到的结果存在内存或者某种缓存介质当中,当下次遇到一模一样的查询SQL时候不在执行SQL与数据库交互,而是直接从缓存中获取结果,减少服务器的压力;尤其是在查询越多、缓存命中率越高的情况下, 使用缓存对性能的提高更明显。
MyBatis允许使用缓存,缓存一般放置在高速读/写的存储器上,比如服务器的内存,能够有效的提供系统性能。MyBatis分为一级缓存和二级缓存,同时也可配置关于缓存设置。
一级存储是SqlSession上的缓存,二级缓存是在SqlSessionFactory上的缓存。默认情况下,MyBatis开启一级缓存,没有开启二级缓存。当数据量大的时候可以借助一些第三方缓存框架或Redis缓存来协助保存Mybatis的二级缓存数据。
1、一级缓存
一级存储是SqlSession上的缓存,默认开启,不要求实体类对象实现Serializable接口。下面在没有任何配置的情况下,测试一级缓存。

public static void main(String[] args) throws IOException {
SqlSessionFactoryBuilder ssfb =new SqlSessionFactoryBuilder();
SqlSessionFactory factory = ssfb.build(Resources.getResourceAsReader("mybatis.xml"));
// 测试一级缓存
SqlSession sqlSession = factory.openSession();
EmpMapper3 mapper = sqlSession.getMapper(EmpMapper3.class);
Emp emp = mapper.findEmp(7499);
Emp emp2 = mapper.findEmp(7499);
System.out.println(emp);
System.out.println(emp2);
sqlSession.close();
SqlSession sqlSession2 = factory.openSession();
EmpMapper3 mapper2 = sqlSession2.getMapper(EmpMapper3.class);
Emp emp1 = mapper2.findEmp(7499);
System.out.println(emp1);
sqlSession2.close();
}

从输出结果可以看出,两次执行相同的查询语句,只访问了一次数据库。第一次执行该SQL语句,结果缓存到一级缓存中,后续执行相同语句,会使用缓存中缓存的数据,而不是对数据库再次执行SQL,从而提高了查询效率。
然而将SqlSession关闭重新开启一个SqlSession时,再次执行前面的查询时会重新访问数据库。一级缓存作用域为SqlSession。
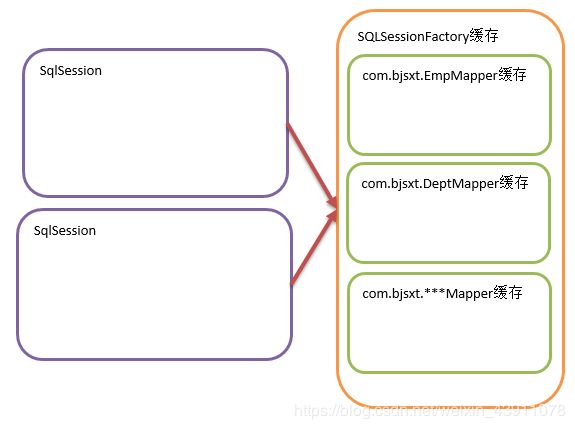
2、二级缓存
二级缓存是SqlSessionFactory上的缓存,可以是由一个SqlSessionFactory创建的SqlSession之间共享缓存数据。默认并不开启。下面的代码中创建了两个SqlSession,执行相同的SQL语句,尝试让第二个SqlSession使用第一个SqlSession查询后缓存的数据。
开启二级缓存有三个开关
1.mybatis核心配置文件中要开启全局二级缓存
2.mapper映射文件中要开启局部二级缓存
3.sql语句要开启独立的二级缓存
1)全局开关:在mybatis.xml文件中的标签配置开启二级缓存
<settings>
<setting name="cacheEnabled" value="true"/>
settings>
cacheEnabled的默认值就是true,所以这步的设置可以省略。
2)分开关:在要开启二级缓存的mapper文件中开启缓存:
<mapper namespace="com.bjsxt.mapper.EmployeeMapper">
<cache/>
mapper>
3)缓存中存储的JavaBean对象必须实现序列化接口
public class Employee implements Serializable { }
经过设置后,查询结果如图所示。发现第一个SqlSession会首先去二级缓存中查找,如果不存在,就查询数据库,在commit()或者close()的时候将数据放入到二级缓存。第二个SqlSession执行相同SQL语句查询时就直接从二级缓存中获取了。
public static void main(String[] args) throws IOException, InterruptedException {
SqlSessionFactoryBuilder ssfb =new SqlSessionFactoryBuilder();
SqlSessionFactory factory = ssfb.build(Resources.getResourceAsReader("mybatis.xml"));
// 测试二级缓存
SqlSession sqlSession = factory.openSession();
EmpMapper3 mapper = sqlSession.getMapper(EmpMapper3.class);
Emp emp = mapper.findEmp(7499);
System.out.println(emp);
// sqlSession 只有提交或者close之后才会将数据放入二级缓存
sqlSession.commit();
sqlSession.close();
Thread.sleep(10000);
SqlSession sqlSession2 = factory.openSession();
EmpMapper3 mapper2 = sqlSession2.getMapper(EmpMapper3.class);
Emp emp1 = mapper2.findEmp(7499);
System.out.println(emp);
sqlSession2.close();
}

注意:
1) MyBatis的二级缓存的缓存介质有多种多样,而并不一定是在内存中,所以需要对JavaBean对象实现序列化接口。
2) 二级缓存是以 namespace 为单位的,不同 namespace 下的操作互不影响
3) 加入Cache元素后,会对相应命名空间所有的select元素查询结果进行缓存,而其中的insert、update、delete在操作是会清空整个namespace的缓存。
4) 如果在加入Cache元素的前提下让个别select 元素不使用缓存,可以使用useCache属性,设置为false。
<select id="findEmp3" resultType="employee" flushCache="false" useCache="false" >
5) cache 有一些可选的属性 type, eviction, flushInterval, size, readOnly, blocking。
<cache type="" readOnly="" eviction="" flushInterval="" size="" blocking=""/>
五、多表联查
在实际开发中,经常会将来自多张表的数据在一个位置显示。
无论是多表关联查询还是级联查询,都是通过resultMap手动配置映射关系完成的,那么resultMap又是什么?它是如何使用的?接下来给大家演示一个resultMap的基础使用场景
1、一对一关联查询
public class Emp implements Serializable {
// 对应Emp表格的八个属性
private Integer empno;
private String ename;
private String job;
private Integer mgr;
private Date hiredate;
private Double sal;
private Double comm;
private Integer deptno;
// 对应部门的属性
private Dept dept;
public Dept getDept() {
return dept;
}
public void setDept(Dept dept) {
this.dept = dept;
}
<mapper namespace="com.bjsxt.mapper.EmpMapper">
<resultMap id="empJoinDept" type="emp">
<id property="empno" column="empno">id>
<result property="ename" column="ename">result>
<result property="job" column="job">result>
<result property="sal" column="sal">result>
<result property="hiredate" column="hiredate">result>
<result property="mgr" column="mgr">result>
<result property="comm" column="comm">result>
<result property="deptno" column="deptno">result>
<association property="dept" javaType="dept">
<id property="deptno" column="deptno">id>
<result property="dname" column="dname">result>
<result property="loc" column="loc">result>
association>
resultMap>
<select id="findEmpJoinDept" resultMap="empJoinDept">
select * from emp e left outer join dept d on e.deptno=d.deptno where e.empno =#{empno}
select>
mapper>
总结:
一对一关联查询通过association标签标示 property代表关联对象的属性 javaType代表关联属性的数据类型
2、一对多关联查询
一对多关系举例:
一个部门中可以有多个员工,dept表中的一条数据可以对应emp表中的多条数据
//根据部门号查询部门信息以及该部门的所有员工信息
//实体类代码
public class Dept implements Serializable {
private Integer deptno;
private String dname;
private String loc;
private List<Emp> emps;
public List<Emp> getEmps() {
return emps;
}
public void setEmps(List<Emp> emps) {
this.emps = emps;
}
}
//接口定义方法
public interface DeptMapper {
Dept getDeptJoinEmps(int deptno);
}
<mapper namespace="com.bjsxt.mapper.DeptMapper">
<resultMap id="deptJoinEmps" type="dept">
<id property="deptno" column="deptno">id>
<result property="dname" column="dname">result>
<result property="loc" column="loc">result>
<collection property="emps" ofType="emp">
<id property="empno" column="empno">id>
<result property="ename" column="ename">result>
<result property="job" column="job">result>
<result property="sal" column="sal">result>
<result property="hiredate" column="hiredate">result>
<result property="mgr" column="mgr">result>
<result property="comm" column="comm">result>
<result property="deptno" column="deptno">result>
collection>
resultMap>
<select id="getDeptJoinEmps" resultMap="deptJoinEmps">
select * from dept d left outer join emp e on d.deptno =e.deptno where d.deptno =#{deptno}
select>
mapper>
3、多对多关联查询
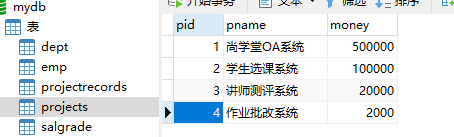
项目表:记录本公司研发过哪些项目
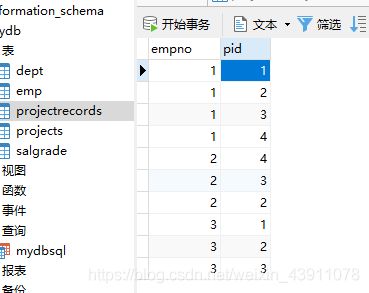
项目记录表:记录哪些员工参与了哪些项目
多对多关系举例:
一个员工可能参与了多个项目的研发,一个项目由多个员工参与,员工表中的一条数据对应项目表中的多条数据,项目表中的一条数据对应员工表中的多条,这就是多对多,多对多关系要借助中间表来体现,中间表将一个多对多关系转换为两个一对多.
//根据员工工号查询该员工参与了哪些项目的研发
//实体类
public class Projects implements Serializable {
private Integer pid;
private String pname;
private Integer money;
}
// 项目记录表中关联一个项目
public class ProjectRecords implements Serializable {
private Integer empno;
private Integer pid;
/*关联一个对应的项目属性*/
private Projects projects;
}
// 员工表中关联多个项目记录表
public class Emp implements Serializable {
// 对应Emp表格的八个属性
private Integer empno;
private String ename;
private String job;
private Integer mgr;
private Date hiredate;
private Double sal;
private Double comm;
private Integer deptno;
// 对应项目记录的属性
private List<ProjectRecords> records;
}
//接口中定义方法
Emp findEmpJoinProjects(int empno);
<resultMap id="empJoinProjects" type="emp">
<id property="empno" column="empno">id>
<result property="ename" column="ename">result>
<result property="job" column="job">result>
<result property="sal" column="sal">result>
<result property="hiredate" column="hiredate">result>
<result property="mgr" column="mgr">result>
<result property="comm" column="comm">result>
<result property="deptno" column="deptno">result>
<collection property="records" ofType="projectRecords">
<id property="empno" column="empno">id>
<id property="pid" column="pid">id>
<association property="projects" javaType="projects">
<id property="pid" column="pid">id>
<result property="pname" column="pname">result>
<result property="money" column="money">result>
association>
collection>
resultMap>
<select id="findEmpJoinProjects" resultMap="empJoinProjects">
select * from
emp e left outer join projectrecords p
on e.empno =p.empno
left outer join projects pc
on p.pid =pc.pid
where e.empno = #{empno}
select>
//测试代码
EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);
Emp emp = mapper.findEmpJoinProjects(2);
System.out.println(emp);
List<ProjectRecords> records = emp.getRecords();
for (ProjectRecords r:records){
System.out.println(r+r.getProjects().toString());
}
总结:
多对多关联查询通过中间表将关联关系传递并在resultMap中使用collection和association嵌套形式实现。
六、级联查询
级联查询顾名思义就是一级一级的查询,级联查询有上一级查询引发下一级及再下一级的连锁反应式的查询,级联查询同样可以实现一对一,一对多和多对多的关系处理,但是处理的方式并不是由一条sql语句直接体现,而是将一个多表关联查询转换为多个单表查询,然后通过association或者collection一级一级的调用已有sql语句而实现的。
级联在实现时有两种策略,一种是积极加载策略,一种是延时加载策略。
1、积极加载
//查询10号部门及该部门的员工信息
//可以将需求分为两个部分,一个是根据部门编号查询一个部门,另一个是根据部门编号查询所有员工
/* 1、先实现根据部门号查询所有员工信息
2、再实现根据部门编号查询部门
3、在查询部门时,调用根据部门号查询员工的功能,实现级联查询
*/
//实体类
public class Dept implements Serializable {
private Integer deptno;
private String dname;
private String loc;
/*组合部门下所有的员工List集合作为属性*/
private List<Emp> emps;
}
public class Emp implements Serializable {
// 对应Emp表格的八个属性
private Integer empno;
private String ename;
private String job;
private Integer mgr;
private Date hiredate;
private Double sal;
private Double comm;
private Integer deptno;
}
//接口方法
//Emp接口
public interface EmpMapper {
List<Emp> getEmpByDeptno(int deptno);
}
//Dept接口
public interface DeptMapper {
Dept getDeptByDeptno(int deptno);
}
<mapper namespace="com.bjsxt.mapper.EmpMapper">
<select id="getEmpByDeptno" resultType="emp">
select * from emp where deptno =#{deptno}
select>
mapper>
<mapper namespace="com.bjsxt.mapper.DeptMapper">
<resultMap id="deptJoinEmp" type="dept">
<id property="deptno" column="deptno">id>
<result property="dname" column="dname">result>
<result property="loc" column="loc">result>
<collection
property="emps"
ofType="emp"
column="deptno"
select="com.bjsxt.mapper.EmpMapper.getEmpByDeptno"
fetchType="eager"
/>
resultMap>
<select id="getDeptByDeptno" resultMap="deptJoinEmp">
select * from dept where deptno = #{deptno}
select>
mapper>
//测试代码
DeptMapper mapper = sqlSession.getMapper(DeptMapper.class);
Dept dept = mapper.getDeptByDeptno(10);
System.out.println(dept.getDname()+dept.getLoc());
List<Emp> emps = dept.getEmps();
for(Emp emp :emps){
System.out.println(emp);
}
总结:
级联查询通过collection/association标签实现, property代表关联多个对象的属性 ofType/javaType代表关联属性或者集合中元素的数据类型.select属性表示要调用的其他sql语句 column表示用上一级中的那个字段的值作为下一级查询的参数.fetchType用来表示级联查询策略
2、延迟加载
**延迟加载,又称按需加载。**延迟加载的内容等到真正使用时才去进行加载(查询)。多用在关联对象或集合中。
延迟加载的好处:先从单表查询、需要时再从关联表去关联查询,大大降低数据库在单位时间内的查询工作量,将工作在时间上的分配更加均匀,而且单表要比关联查询多张表速度要快。
延迟加载的设置
第一步:全局开关:在mybatis.xml核心xml中打开延迟加载的开关。配置完成后所有的association和collection元素都生效
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
settings>
lazyLoadingEnabled:是否开启延迟加载。是Mybatis是否启用懒加载的全局开关。当开启时,所有关联对象都会延迟加载。特定关联关系中可通过设置fetchType属性来覆盖该项的开关状态
aggressiveLazyLoading**:**当开启时,任何方法的调用都会懒加载对象的所有属性。否则,每个属性会按需加载,
第二步:分开关:指定的association和collection元素中配置fetchType属性。eager:表示立刻加载;lazy:表示延迟加载。将覆盖全局延迟设置。
优点:
延迟加载可以根据用户的需要动态的决定查询数据的时机. 可以将查询的工作量在时间上分散. 减少单位时间内对于数据库的查询次数.进而减少了数据库单位时间内的运算压力,提高数据库的相应速度.级联查询将一个多表关联查询转换成多个单边查询,sql语句变得简单了,单次单表查询比单次表查询效率更高,相应速度更快
级联查询缺点:
关联查询转换成级联查询,由原来的一次查询,转换成多次查询,查询次数增多,工作总量是增加的. 延迟加载可以简单理解为是级联查询的一种优化策略
3、总结
3.1、级联查询和多表连接查询的比较及其选择
| 对比角度 | 级联查询 | 多表连接查询 |
|---|---|---|
| SQL语句数量 | 多条 | 一条 |
| 性能 | 性能低 | 性能高 |
| 延迟加载 | 立即加载、延迟加载 | 只有立即加载 |
| 灵活性 | 更灵活 | 不灵活 |
| SQL难易度 | 简单 | 复杂 |
| 选择依据 | 简单、灵活 | 高性能 |
3.2、resultMap中的常见属性
| 属性 | 描述 |
|---|---|
| property | 需要映射到JavaBean 的属性名称。 |
| javaType | property的类型,一个完整的类名,或者是一个类型别名。如果你匹配的是一个JavaBean,那MyBatis 通常会自行检测到。 |
| column | 数据表的列名或者列别名。 |
| jdbcType | column在数据库表中的类型。这个属性只在insert,update 或delete 的时候针对允许空的列有用。JDBC 需要这项,但MyBatis 不需要。 |
| typeHandler | 使用这个属性可以覆写类型处理器,实现javaType、jdbcType之间的相互转换。一般可以省略,会探测到使用的什么类型的typeHandler进行处理 |
| fetchType | 自动延迟加载 |
| select | association、collection的属性,使用哪个查询查询属性的值,要求指定namespace+id的全名称 |
| ofType | collection的属性,指明集合中元素的类型(即泛型类型) |
ResultType和ResultMap使用场景
1) 如果你做的是单表的查询并且封装的实体和数据库的字段一一对应 resultType
2) 如果实体封装的属性和数据库的字段不一致 resultMap
3) 使用N+1级联查询的时候 resultMap
4) 使用的是多表的连接查询 resultMap
一对一关联映射的实现
1) 实例:学生和学生证、雇员和工牌
2) 数据库层次:主键关联或者外键关联(参看之前内容)
3) MyBatis层次:在映射文件的设置双方均使用association即可,用法相同
多对多映射的实现(两个一对多)
1) 实例:学生和课程、用户和角色
2) 数据库层次:引入一个中间表将一个多对多转为两个一对多
3) MyBatis层次
方法1:在映射文件的设置双方均使用collection即可,不用引入中间类
方法2:引入中间类和中间类的映射文件,按照两个一对多处理
自关联映射
1) 实例:Emp表中的员工和上级。一般是一对多关联
2) 数据库层次:外键参考当前表的主键(比如mgr参考empno)
3) MyBatis层次:按照一对多处理,但是增加的属性都写到一个实体类中,增加的映射也都写到一个映射文件中
七、注解开发
MyBatis编写SQL除了使用Mapper.xml还可以使用注解完成。当可以使用Auto Mapping时使用注解非常简单,不需要频繁的在接口和mapper.xml两个文件之间进行切换。但是必须配置resultMap时使用注解将会变得很麻烦,这种情况下推荐使用mapper.xml进行配置。
MyBatis支持纯注解方式,支持纯mapper.xml方式,也支持注解和mapper.xml混合形式。当只有接口没有mapper.xml时在mybatis.cfg.xml中可以通过加载接口类。如果是混合使用时,使用。此方式一直是官方推荐方式。
如果某个功能同时使用两种方式进行配置,XML方式将覆盖注解方式。
public interface IEmpMapper {
//增加数据
@Insert("insert into emp values(#{empno},#{ename},#{job},#{mgr},#{hiredate},#{sal},#{comm},#{deptno})")
int insertEmp(Emp emp);
//更新数据
@Update("update emp set job=#{job},sal=#{sal} where empno=#{empno}")
int updateEmp(Emp emp);
//删除数据
@Delete("delete from emp where empno=#{empno}")
int deleteEmp(int empno);
//查询所有
@Select("select * from emp")
List<Emp> selectAll();
//使用id查询
@Select("select * from emp where empno=#{empno}")
Emp selectById(int id);
//根据部门查询
@Select("select * from emp where deptno=#{deptno}")
List<Emp> selectByDeptno(int deptno);
//使用姓名模糊查询
@Select("select * from emp where ename like '%'||#{ename}||'%'")
List<Emp> selectEmpByName(String ename);
//使用Javabean查询 前面必须要有script标签
//涉及动态sql的不推荐使用注解,没有代码提示,敲代码效率不高
@Select({""})
List<Emp> selectEmpByEmp(Emp emp);
//根据list方式查询
//涉及动态sql的不推荐使用注解,没有代码提示,敲代码效率不高
@Select({""
})
List<Emp> selectEmpsByList(List<Integer> list);
//一对一
/**
* properts:javabean中的属性名
* column:数据库中的列名,在一对多中表示同名连接的列
* javaType:表示many中select的返回值类型,用字节码表示,一对多为 List.class 而非Emp.class
* @return
*/
@Select("select * from emp e,dept d where e.deptno=d.deptno")
@Results({
@Result(column = "empno",property = "empno",id = true),
@Result(column = "ename",property = "ename"),
@Result(column = "job",property = "job"),
@Result(column = "mgr",property = "mgr"),
@Result(column = "sal",property = "sal"),
@Result(column = "comm",property = "comm"),
@Result(column = "hiredate",property = "hiredate"),
@Result(column = "deptno",property = "deptno"),
@Result(property = "dept",one = @One(select = "com.itlazy.mappers.IDeptMapper.selectDeptById"),column = "deptno",javaType = Dept.class)
})
List<Emp> selectOne2One();
}
如果希望通过注解实现和mapper.xml中相同功能的效果,可以使用@Results注解实现。
如果对象中关联了集合类型对象可以通过@Result - many属性加载集合属性的值。在注解实现中只能通过N+1查询方式,而没有连接查询方式。
如果对象中关联了另一个对象,使用@Result - one属性加载另一个对象。
在MyBatis3的注解中包含了@SelectProvider、@UpdateProvider、@DeleteProvider、@InsertProvider,统称@SqlProvider,这些方法分别对应着查询、修改、删除、新增。当使用这些注解时将不在注解中直接编写SQL,而是调用某个类的特定方法形成的SQL
@SelectProvider(type= MyProvider.class,method = "selectStudents")
List<Student> selectStudent();
public class MyProvider {
public String selectStudents(){
return "select * from student";
}
}
具体在框架中使用注解还是XML配置方式,要视框架情况而定。Spring、SpringBoot中更推荐注解方式。但是在MyBatis中更推荐使用XML配置方式。原因如下:
1) 使用注解没有实现Java代码和SQL语句的解耦
2) 无法实现SQL语句的动态拼接
3) 进行多表的查询时定制ResultMap比较麻烦
注解和XML的对比
| XML | 注解 | |
|---|---|---|
| 各自优势 | 1.sql语句和类之间的解耦2.利于修改。直接修改XML文件,无需到源代码中修改。 3.配置集中在XML中,对象间关系一目了然,利于快速了解项目和维护 4.容易和其他系统进行数据交换 | 1.简化配置 2.使用起来直观且容易,提升开发效率 3.类型安全,编译器进行校验,不用等到运行期才会发现错误。 4.注解的解析可以不依赖于第三方库,可以之间使用Java自带的反射 |