kafka (confluent)学习
kafak学习
- 1.zookeeper解惑
- 2.kafka介绍
- 3.模式解说
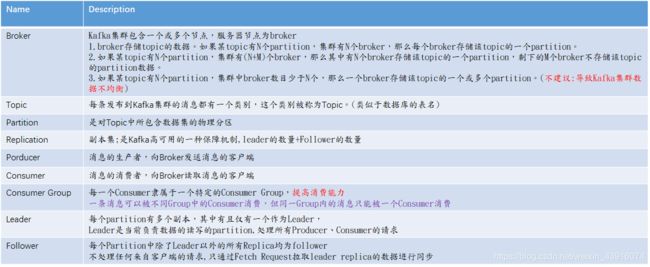
- 4.Terminology
- 5.图解
- 6.command
- 7.生命周期
- 8.Persistence
- 9.数据可靠性
- 10.消息传输一致性
1.zookeeper解惑
1.zookeeper集群最好是奇数个,因为2n+1和2n+2的容灾性是一样的,节省资源,使用2n+1
并且要保证活着的server数大于等于n+1
2.很多人有疑问:如果5个server集群,死掉一个,四个怎么办,怎么选leader??
zookeeper会闲置一个server,使用3个继续开启服务
2.kafka介绍
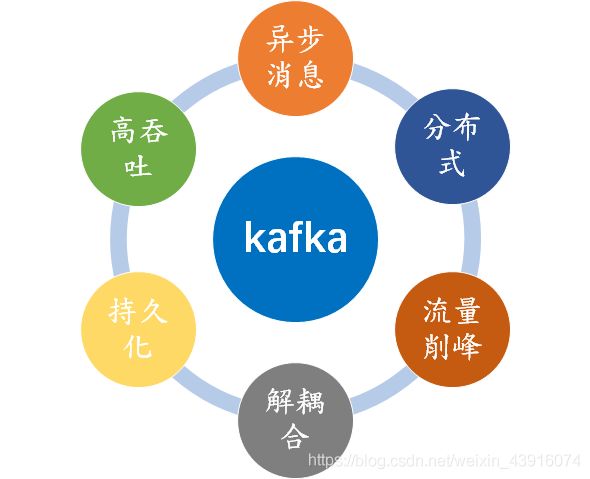
- 高吞吐:kafka每秒可以上产25万消息,每秒处理55万消息
- 持久化:可以将消息持久化到磁盘
- 分布式:所有的producer,consumer,broker都会有多个,无需停机即可扩展
- 异步消息:允许用户把消息放入队列,不用立即处理,而且想放多少消息都可以,有需要的时候再去处
- 流量削峰:比如秒杀活动的时候,可以用来处理抢购带来的流量峰值
- 解耦合:降低工程间的强依赖程度,不直接调用,通过消息传输
3.模式解说
- 点对点模式(一对一)
- 消费者主动拉取数据,消息收到后消息清除(queue清除消息)
- 消息生产者生产消息发送到queue中,消费者从queue中取出并消费消息,消息被消费以后,queue中不再有存储,所以消费者不可能消费到已经被消费的消息。
- queue支持存在多个消费者,但对一个消息而言只会有一个消费者可以消费
- 发布订阅模式(一对多)
-
消费者消费数据之后不会清除消息
-
第一种是消费者主动拉取数据(默认模式)
- 好处:速度可以自己控制
- 坏处:要维护一个长轮询,不断地去询问队列是否有新消息
-
第二种是队列主动推送数据
- 各消费者消费的速率可能不一样,但是推的速率是一样的,
如果消费者能力处理不足,可能直接就崩掉了.
- 各消费者消费的速率可能不一样,但是推的速率是一样的,
-
4.Terminology
5.图解
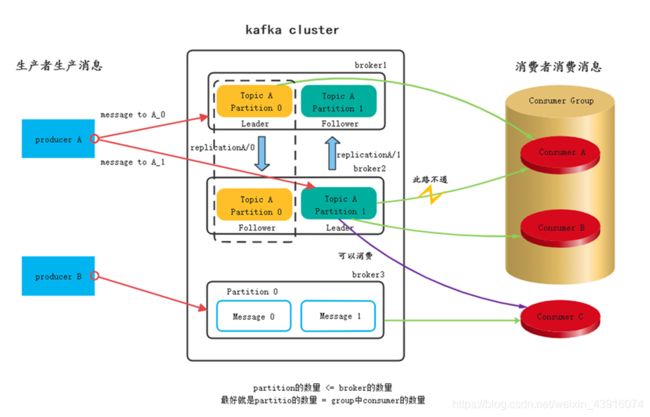
1.生产,消费,broker ,partition,replication的关系
partition的作用就是现实topic的负载均衡,把消息均匀的分到对应的topic中
2.replication的解说
Replication的数量 = broker的数量 ,最大程度的提高了系统的容错率
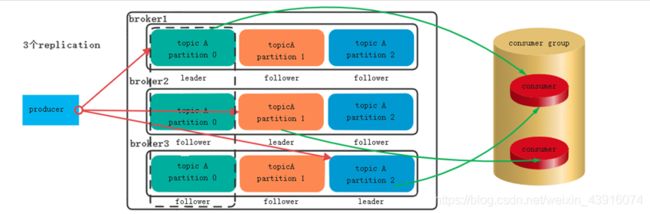
Replication的数量大于broker的数量没有任何意义,还会报警
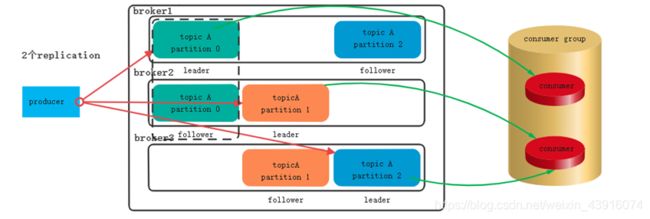
replica副本数越高,系统虽然越稳定,但是会带来资源和性能上的下降;replica副本少的话,也会造成系统丢数据的风险。
3.offset解说
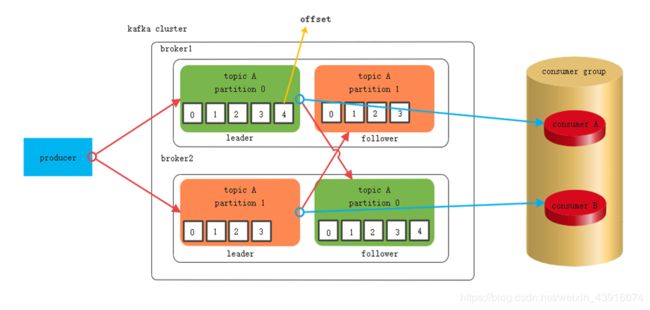
6.command
1.创建和删除topic(如果不指定,就是1个partition,1个replication)
./kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic superman
./kafka-topics --delete --zookeeper localhost:2181 --topic superman
2.生产者
./kafka-console-producer --broker-list localhost:9092 --topic superman
3.消费者
./kafka-console-consumer --bootstrap-server localhost:9092 --from-beginning --group test-consumer-group --topic superman
4.消费者组列表
./kafka-consumer-groups --bootstrap-server localhost:9092 --list
5.消费者消费的topic详情
./kafka-consumer-groups --bootstrap-server localhost:9092 --group test-consumer-group --describe
6.清空offset:offset由consumer来管理
./kafka-consumer-groups --bootstrap-server localhost:9092 --group test-consumer-group --topic superman --reset-offsets --to-earliest --execute
7.生命周期
1.配置文件server.properties中可以配置
保存168H的配置
log.retention.hours=168
2.用命令去配置
7.Message的生命周期(全局的设置在server.properties)
./kafka-configs --zookeeper localhost:2181 --alter --entity-name deltaman --entity-type topics --add-config retention.ms=86400000
8.查看topic设置
./kafka-configs --zookeeper localhost:2181 --entity-name deltaman --entity-type topics --describe
输出:Configs for topics:wordcounttopic are retention.ms=86400000
9.立即删除某个topic下的数据
./kafka-topics --zookeeper localhost:2181 --alter --topic mytopic --config cleanup.policy=delete
8.Persistence
1.持久化到本地磁盘
Kafka的持久化策略更像redis,数据都在内存中,定期flush到硬盘上持久化存储,以保证重启的时候数据不丢

每个topic可以存储于多个partition,每个partition在kafka的log目录下表现为[topicname]-[id]这样的文件夹,如mytopic-0。kafka队列中的内容会按照日志的形式持久化到硬盘上。每个日志文件称为“段”(segment)。
producer发送message必须指定是发送到哪个topic,但是不需要指定topic下的哪个partition,因为kafka会把收到的message进行load balance,均匀的分布在这个topic下的不同的partition上。
Partition的存储结构:topic设定20个partition

9.数据可靠性
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer的数据后,都需要向producer发送ack(acknowledgement),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
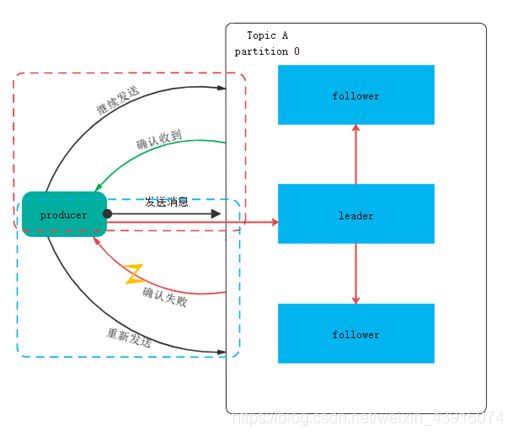
有一个问题,什么时候发送ack:
1.follower和leader同步完成,leader再发送ack
2.半数以上的follower完成同步,即可发送ack
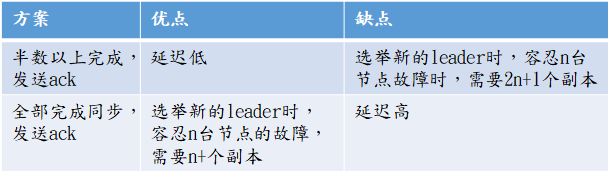
Kafka选择了第二种方案,原因如下:
1.followe同样容忍n个节点故障,A方案需要2n+1个副本,B方案只需要n+1个,kafka每个分区都有大量数据,会造成数据冗余
2.B方案虽然网络延迟比较高,但网络延迟对kafka影响较小

如果有10个副本,1个leader,9个follower,那么可以其中4个跑得最快的放到isr中,如果这四个follower跑完了,就发送ack。
ACK的参数配置:
0:代表不等待borker的ack,有消息procuder就发送,有消息就发送,不管有没有送达。
1:producer等待leader写完后返回的ack,不等待follower是否完成
-1(all):等待isr中所有的follower都写完返回的ack。(会造成数据重复)
10.消息传输一致性
Kafka提供3种消息传输一致性语义:最多1次,最少1次,恰好1次。
最少1次:可能会重传数据,有可能出现数据被重复处理的情况;
最多1次:可能会出现数据丢失情况;
恰好1次:并不是指真正只传输1次,只不过有一个机制。确保不会出现“数据被重复处理”和“数据丢失”的情况。
at most once: 消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中consumer进程失效(crash),导致部分消息未能继续处理.那么此后可能其他consumer会接管,但是因为offset已经提前保存,那么新的consumer将不能fetch到offset之前的消息(尽管它们尚没有被处理),这就是"at most once".
at least once: 消费者fetch消息,然后处理消息,然后保存offset.如果消息处理成功之后,但是在保存offset阶段zookeeper异常或者consumer失效,导致保存offset操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once".
"Kafka Cluster"到消费者的场景中可以采取以下方案来得到“恰好1次”的一致性语义:
最少1次+消费者的输出中额外增加已处理消息最大编号:由于已处理消息最大编号的存在,不会出现重复处理消息的情况。
--------------------------- 有新的知识再更新 ------------------------------------