本周AI热点回顾:英特尔芯片后门实锤;Adobe等新研究把「自拍」变「他拍」;Kaggle上线arXiv完整数据集...
点击左上方蓝字关注我们

01
脑洞大开!Adobe等新研究把「自拍」变「他拍」,魔幻修图效果感人
智能手机的出现,让摄影变成了一项大众艺术,也让越来越多的人爱上「自拍」。但自拍照常常存在构图问题,比如不自然的肩膀姿势、占据一小半镜头的手臂,或者极其诡异的视角。

要想解决这个问题,可以选择随身携带三脚架或自拍杆,也可以选择随身携带一个朋友作为摄影师(该方法对单身狗极其不友好)。或者,你还可以选择相信后期修图的艺术。近日,来自 Adobe 研究院、UC 伯克利、鲁汶大学的研究者开发了一种「自拍」变「他拍」的新技术,通过识别目标的姿势并生成身体的纹理,在给定的自拍背景中完善和合成人物。

研究者提出了一种叫做 「Unselfie(非自拍)」的图片转换方法,能够将自拍照中的人物,转变为手臂、肩膀、躯干都比较放松舒展的“他拍图像”。它会把所有举起的手臂调整为向下,然后调整服装细节,最后填充好所有暴露出来的背景区域。
除了用来修饰社交媒体上的自拍照,这项技术还有很多应用方式,如果你急需一张证件照,而无人能帮你拍摄,那这项技术就能派上用场。

总的来说,「自拍」转「他拍」存在三大挑战:
没有成对的训练数据(自拍 - 他拍图像对);
一个自拍姿势可能对应多个他拍姿势;
改变姿势会在背景中留下空洞,因此在转换过程中要填补这些空洞。
因此,他们提出借助合成「自拍 - 他拍」图像对和自监督学习的方法来解决上述问题。下图表明,与之前的 DPIG 和 PATN 方法相比,Unselfie 方法生成了更逼真的人体姿势和背景。
信息来源:机器之心
02
英特尔CPU机密数据大量泄露:芯片后门实锤,下一代CPU原理图曝光
英特尔自从7月24日发布财报以来,可谓厄运连连:7nm制程被推迟、半个月内股价跌去2成、首席工程师离职。
更惨的是,今天他们有20GB的数据被黑客泄露了。
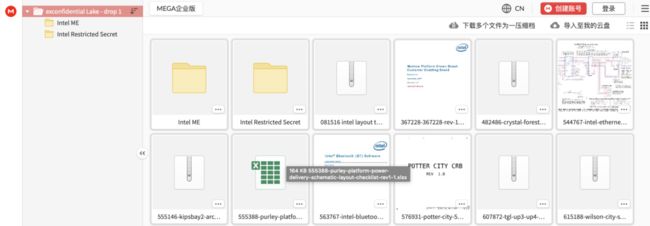
泄露内容可谓触目惊心,不仅包括英特尔还未发布的Tiger Lake笔记本CPU的原理图、固件,还有各种芯片的开发调试工具包,等于把英特尔家底完全暴露。
大家一直怀疑英特尔的CPU是否有后门,通过这次泄露事件得到了证实。获得这份文件的工程师用关键词“backdoor”搜索,发现英特尔居然将其赫然写在代码注释里。
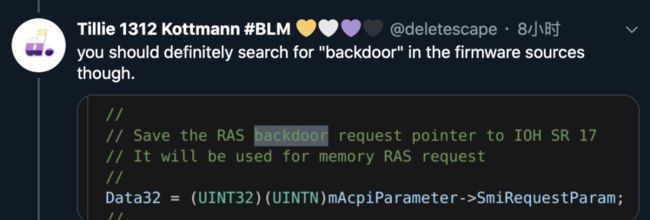
目前已经公开的17GB文件包含各种CPU芯片的设计数据,其中的测试文档、源代码和演示文稿可追溯到2018年甚至更早。

数据中有至强(Xeon)平台的Verilog代码。看过文档的技术人员表示,如果其他CPU厂商看到这份数据,可能会对CPU的研发大有帮助。
文件中不仅包含英特尔过往的核心数据,还有即将发布的两大CPU平台的详细信息。
比如,即将发布的Tiger Lake移动CPU的原理图、文档、工具和固件,将于2020年底发布的第11代桌面级CPU——Rocket Lake——的仿真器。
有专业人士表示,这些代码虽然已经泄露,但不能被当做开源代码使用,之前微软的泄露事件就是前车之鉴。所以,虽然黑客公开了大量技术文档,但是其他厂商像AMD都必须极力避嫌,否则将面临英特尔的律师函警告。
信息来源:量子位
03
用Dota2“最强”算法PPO完成CarPole和四轴飞行器悬浮任务
2019年Dota 2比赛中,OpenAI Five完胜世界冠队伍OG。

那么OpenAI Five应用了什么技术,实现在Dota中完胜世界冠军的呢?那就是Proximal Policy Optimization(PPO)算法
PPO算法将游戏中所有的状态作为数据输入,通过数据分析计算,由PPO优化的智能体Agent做出相应的动作,智能体Agent的思考过程如下图所示。

智能体Agent在Env中不断学习,根据环境的状态State(也可以为观察到的observation,下文统一用State)来执行动作Action,过程中会根据反馈的Reward来选择效果更好的动作。
优化的目标是策略的期望回报,即所有轨迹的回报与对应轨迹发生概率的加权和。当N足够大时,通过采样N个轨迹求平均的方式近似表达,简单理解就是所得Reward的平均值。每次都让网络来拟合之前Reward的平均值,通常优化策略越好,Reward会越高,不过也不是绝对的。
先了解强化学习常用的两种训练方式:On-policy和Off-policy。
On-policy:训练的agent一边互动一边学习(互动的agent就是训练的agent);
Off-policy:训练的agent一边看一边学习(互动的agent不是训练的agent)。
举例来说,古代杰出帝王都需要深入了解民间百姓的真实生活,这两种策略就类似帝王们获取信息的途径。皇帝可以选择微服出巡(On-policy),虽然眼见为实,但毕竟皇帝本人分身乏术,掌握情况不全;也可以选择派不同的官员去了解情况,再向皇帝汇报(Off-policy)。
在网络训练过程中,通过采样更新权重非常耗时,每更新一个参数就需要采样一次,因此我们需要把On-policy训练方式转化成Off-policy。
基于飞桨PARL,使用PPO实现四轴飞行器悬浮任务。您只需要获取如下文件,并在终端安装parl和rlschool后,运行python train.py,即可查看实践效果。
mujoco_model.py
mujoco_agent.py
scaler.py
train.py
.py文件获取路径:
https://aistudio.baidu.com/aistudio/projectdetail/632270
实践效果
在rlschool环境下 四轴飞行器悬浮任务 Evaluate reward一直在上涨,达到了7107。


完整项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/632270
信息来源:飞桨PaddlePaddle
04
Facebook开发玩德州扑克的AI,大比分击败顶尖人类选手!
继百度词法分析工具 LAC 2.0开源之后,8月4日,百度 NLP 又重磅发布了中文依存句法分析工具——DDParser!
DDParser 是什么 :
DDParser(Baidu Dependency Parser)是百度 NLP 基于大规模标注数据和深度学习平台飞桨研发的中文依存句法分析工具,可帮助用户直接获取输入文本中的关联词对、长距离依赖词对等。
如图1所示,输入文本通过 DDParser 输出其对应的句法分析树,其中,两词之间的弧表示两个词具有依赖关系,由核心词指向依存词,弧上的标签表示依存词对核心词的关系。

图1
DDParser 能做什么:
通过依存句法分析可直接获取输入文本中的关联词对、长距离依赖词对等,其对事件抽取、情感分析、问答等任务均有帮助。
如图1所示实例,在事件抽取任务中,我们通过依存分析结果可提取句子中所包含的各种粒度的事件,如“纳达尔击败梅德韦杰夫”、“纳达尔夺得冠军”、“纳达尔夺得2019年美网男单冠军”。
相应的,在问答任务中,我们根据问题的句法树与答案所在文本的句法树进行基于树的结构匹配,可获取对应的答案。例如,问题“谁夺得了2019年美网男单冠军”,句法树见图2,其答案所在文本的句法树见图1,我们通过两棵树的对应部分匹配,可得出答案为“纳达尔”。
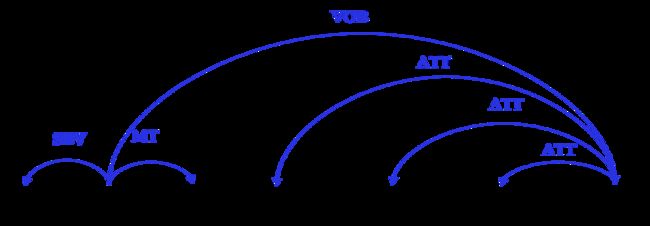
图2
依存分析将句子表示为一棵树,提供了词之间的依赖关系和关联路径,其在句子序列基础上提供了更多的句子结构信息,可帮助其他任务从句子结构角度获取所需信息。
DDParser 的优势
1. 基于大规模优质标注数据:
DDParser 训练数据近百万,包含搜索 query、网页文本、语音输入数据等,覆盖了新闻、论坛等多种场景。从应用的角度出发,为了方便用户快速上手,DDParser 共设计了14种依存关系,并着重凸显实词间的关系,在随机数据上 LAS 可达到86.9%。
2. 基于深度学习框架,不依赖繁复的特征工程:
首先,DDParser 采用 bilinear attention mechanism 对句子语义进行表示,代替复杂的特征工程模式。其次,其输入层加入了词的 char 级别表示,缓解粒度不同带来的效果下降,网络结构如图5所示。
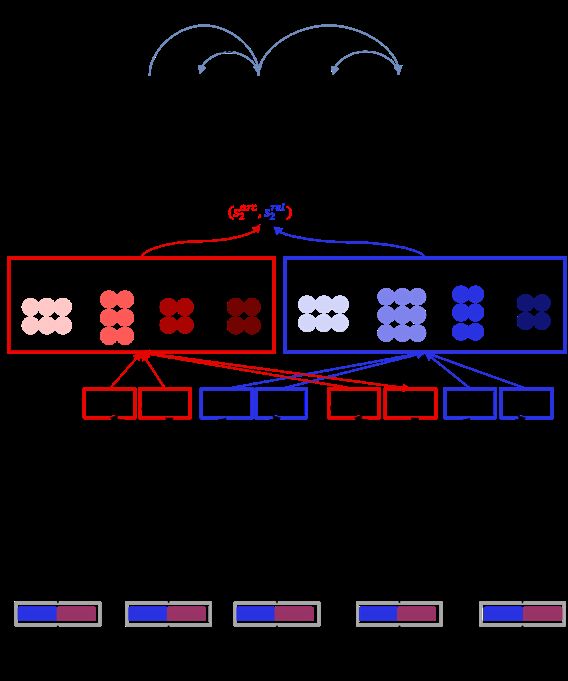
▲ 图5
3. 调用便捷:
DDParser 支持 Python 一键安装,方便用户快速使用。DDParser 支持 pip 一键安装,兼容 Windows、Linux 和 MacOS,调用方法如下所示:
pip install ddparserfrom ddparser import DDParserddp = DDParser()ddp.parse("百度是一家高科技公司")
具体安装方法参见 GitHub 的 README 文档中的快速开始。
信息来源:百度AI
05
170多万篇论文,存储量达1.1 TB,Kaggle上线arXiv完整数据集
众所周知,arXiv 是我们搜索、浏览和下载学术论文的重要工具。arXiv 上研究论文数量之多有利也有弊。一方面,对于在自身研究领域迅速成长的研究生,以及致力于用科研为公众提供服务的研究者而言,这一丰富的信息库可以提供极有效的助力。另一方面,arXiv 有时在搜索时也有不便。

近期,为了让 arXiv 可用度更高,康奈尔大学和其他一些开发者在 kaggle 上创建了一个免费、开放的 arXiv 数据集。该数据集是一个含有 170 多万篇学术论文的存储库,用户可以获取论文的标题、作者、类别、摘要、全文 pdf 等。
这是一个包含 170 多万篇理工科(STEM)学术论文的 arXiv 数据集和元数据。目前,开发者已经更新了 5 个版本,从第一版的 arXiv 元数据集(arXiv metadata)到最新版本的 arXiv 数据集,包含的论文数量越来越多,范围也更广。该数据集将每周更新一次。
第一版的 arXiv 元数据。
该数据集是原始 arXiv 数据的镜像,存储量高达 1.1TB,并且还会继续增加。数据集仅提供了 json 格式的元数据文件,它包含每篇论文的相关条目,具体如下:
id:arXiv ID,可用于访问论文;
submitter:论文提交者;
authors:论文作者;
title:论文标题;
comments:论文页数和图表等其他信息;
journal-ref:论文发表的期刊;
doi:数字对象标识符;
abstract:论文摘要;
categories:论文在 arXiv 系统的所属类别或标签;
versions:论文版本。
此外,用户可以通过以下两个链接直接在 arXiv 上访问每篇论文:
https://arxiv.org/abs/{id}:包含摘要和进一步链接的论文页面;
https://arxiv.org/pdf/{id}:论文 PDF 下载页面。
信息来源:机器之心
END
