requests + pyquery 爬取 csdn 博客信息
突然闲来无事想要爬取csdn博客,顺便温习下相关技术点。
爬取目标
以我的csdn主页为例
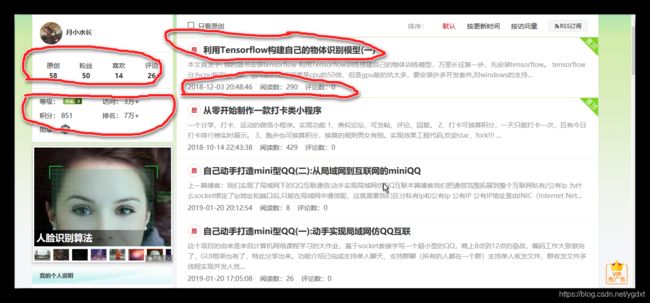
爬取的主要的数据已经在上用红线图标出来了,主要可分为两部分
- 所有博客的八个统计数据,原创的博客数、你的粉丝数、博客获得的赞、博客的评论数、博客等级、访问量、积分和排名
- 每篇博客的具体信息,如标题、发布时间、阅读数、评论数
思路分析
Google Chrome浏览器F12开发者工具查看网页结构,比较简单,如下图所示
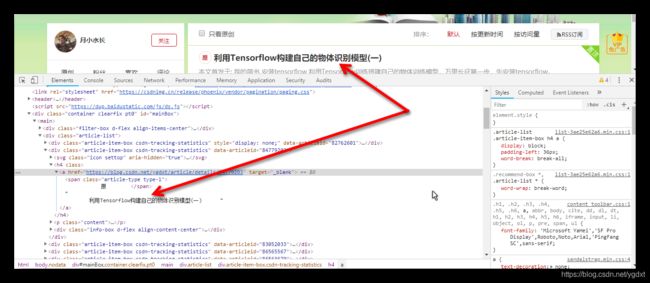
csdn网站虽然是一个技术性博客,但是貌似它的反爬措施做的不那么优秀,举个例子,我在分析网页结构的过程中发现它的评论数不是通过Ajax动态渲染的,而新浪新闻做到了这一点,也许是因为新闻类的实时性要求较高而技术博客类没这个必要吧。
主要技术点
Requests库获取网页
我看到许多爬虫教程都是用的urllib2等比较过时的爬虫库来获取网页信息,一来python2马上停止支持,python2时代的urllib2的凸现出来的毛病会越来越多且无法得到官方的修复;二来无论是基于python2的ulilib2还是python3的urllib3,过程都稍显繁琐,不如requests库简明,而且urllib2/3能做的requests都能做,干嘛不用requests呢?
requests.get(url=myUrl,headers=headers).text
get()接收两个关键字参数,第一个就是我们要爬取网页的URL,第二个就是请求头,用于模拟浏览器访问服务器,不然csdn的服务器会拒绝连接,不懂的可以百度补一下计算机网络相关知识。
get()返回的是一个requests.models.Response对象,通过它的text属性可以得到网页的源码,字符串类型,这样以后我们就能通过各种字符串操作方便地解析网页,从而获取我们想要的信息。
pyqeury库解析网页
其实解析网页最直接的办法是利用re这个库写正则表达式提取信息,优点是正则是万能的,所有的字符串提取都可以通过字符串提取,只有改变匹配的规则就行了,不过缺点是学习起来费劲(最好还是要掌握的,毕竟每个语言的匹配规则都是类似的,在java学的匹配规则照样可以用在python中,只是语法不同,API稍有差异)
第三方解析库有BeautifulSoup、lxml、pyquery等,学习这些库前最好已经掌握css选择器的一些语法规则,再学这些解析库就事半功倍了,个人感觉最好用的是pyquery库。安装pyquery需要在在命令行下输入:
pip istall pyquery
拿到网页源码后,通过
doc = pq(myPage)
得到一个pyquery.pyquery.PyQuery对象,其中参数就是网页源码
然后可以通过
doc(“aside .data-info dl”).items()
来得到aside标签下class为data-info的标签下的所有dl标签,返回的仍是一个pyquery.pyquery.PyQuery对象,如果dl的标签不止一个,我们可以通过.items()把这个对象转乘一个生成器,通过for a in b来迭代获取每一个dl标签,同样地,迭代出来的每一个子项还是pyquery.pyquery.PyQuery对象。
下面是pyquery常见的api
| 名称 | 功能 |
|---|---|
| attr(key) | 得到标签下属性key的属性值,字符串类型 |
| parent()/children() | 得到标签的父/子标签 |
| text() | 得到标签的文本 |
更多的api可以参考:pyqeury官方教程
另外的,假设一个pyquery.pyquery.PyQuery对象a,通过a(“li”),可以对a里的li标签再选择,所以这种选择过程可以是多重嵌套的,一个容易忘记的选择器语法是a("[b=c]"),用来选择a标签下属性b的属性值为c的所有标签。
运行结果
如下图所示,所有的功能目标已经实现
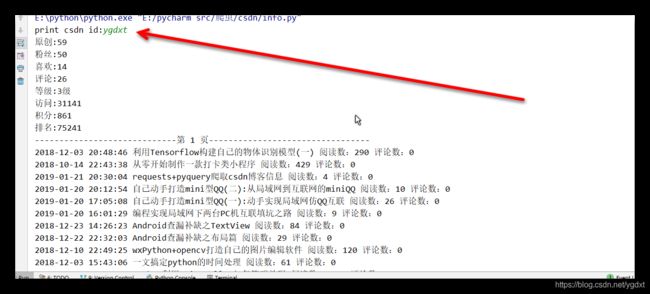
其中csdn id就是想要爬取博主的id,可以去博主的主页看
源代码
2019/01/21,代码如下:
代码最新更新在我的github:python爬虫集合之csdn爬虫
同时可以关注我的csdn爬虫专栏:python3爬虫实战
更多干货在我的微信公众号:inspurer
感谢支持!
# -*- coding: utf-8 -*-
# author: inspurer(月小水长)
# pc_type lenovo
# create_date: 2019/1/21
# file_name: csdn
# qq_mail [email protected]
import requests
from pyquery import PyQuery as pq
# 当前的博客列表页号
page_num = 1
account = str(input('print csdn id:'))
#account = "ygdxt"
# 首页地址
baseUrl = 'http://blog.csdn.net/' + account
# 连接页号,组成爬取的页面网址
myUrl = baseUrl + '/article/list/' + str(page_num)
headers = {'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'}
# 构造请求
# 访问页面
myPage = requests.get(myUrl,headers=headers).text
doc = pq(myPage)
data_info = doc("aside .data-info dl").items()
for i,item in enumerate(data_info):
if i==0:
print("原创:"+item.attr("title"))
if i==1:
print("粉丝:"+item.attr("title"))
if i==2:
print("喜欢:"+item.attr("title"))
if i==3:
print("评论:"+item.attr("title"))
grade_box = doc(".grade-box dl").items()
for i,item in enumerate(grade_box):
if i==0:
childitem = item("dd > a")
print("等级:"+childitem.attr("title")[0:2])
if i==1:
childitem = item("dd")
print("访问:"+childitem.attr("title"))
if i==2:
childitem = item("dd")
print("积分:"+childitem.attr("title"))
if i==3:
print("排名:"+item.attr("title"))
# 获取每一页的信息
while True:
# 首页地址
baseUrl = 'http://blog.csdn.net/' + account
# 连接页号,组成爬取的页面网址
myUrl = baseUrl + '/article/list/' + str(page_num)
# 构造请求
myPage = requests.get(myUrl,headers=headers).text
if len(myPage) < 30000:
break
print('-----------------------------第 %d 页---------------------------------' % (page_num,))
doc = pq(myPage)
articles = doc(".article-list > div").items()
articleList = []
for i,item in enumerate(articles):
if i == 0:
continue
title = item("h4 > a").text()[2:]
date = item("p > .date").text()
num_item = item("p > .read-num").items()
ariticle = [date, title]
for j,jitem in enumerate(num_item):
if j == 0:
read_num = jitem.text()
ariticle.append(read_num)
else:
comment_num = jitem.text()
ariticle.append(comment_num)
articleList.append(ariticle)
for item in articleList:
if(len(item)==4):
print("%s %s %s %s"%(item[0],item[1],item[2],item[3]))
page_num = page_num + 1