Hadoop高可用安装(HA)
操作系统:CentOS-7.8
Hadoop版本:3.2.1
Zookeeper版本:3.4.14
一、环境说明
本次安装的为完全分布式高可用的Hadoop集群,本次安装使用的是Hadoop 3.2.1,分别部署了3个NameNode和3个ResourceManager,在Hadoop3之前的版本中默认是不支持多个standby的NameNode和ResourceManager,所以本教程使用的是新版本的Hadoop可以部署多个NameNode和ResourceManager
服务器5台:
- biu51:192.168.56.51,8G,2Core
- biu52:192.168.56.52,8G,2Core
- biu53:192.168.56.53,8G,2Core
- biu54:192.168.56.54,8G,2Core
- biu55:192.168.56.55,8G,2Core
服务安装分配:
- Zookeeper:5台均部署
- NameNode:biu51,biu52,biu53
- DataNOde:5台均部署
- JournalNode:5台均部署
- ResourceManager:biu51,biu52,biu53
- NodeManager:5台均部署
服务器hosts文件修改,主机间可以通过主机名访问
192.168.56.51 biu51
192.168.56.52 biu52
192.168.56.53 biu53
192.168.56.54 biu54
192.168.56.55 biu55
服务器之间ssh免密登陆
- ssh安装(已安装跳过):yum install -y openssh-server openssh-clients
- 生成密钥:ssh-keygen -t rsa
- 拷贝密钥:ssh-copy-id -i ~/.ssh/id_rsa.pub [ip/hosts]
注意事项:
- .ssh目录的权限必须是700
- .ssh/authorized_keys文件权限必须是600
二、部署配置
Zookeeper安装
1.{ZK_HOME}/bin/zkEnv.sh配置
#java安装目录
export JAVA_HOME=/app/jdk/jdk1.8.0_231
#zk的日志目录
export ZOO_LOG_DIR=/app/zookeeper/log
2.{ZK_HOME}/conf/zoo.cfg
tickTime=2000
maxSessionTimeout=100000
initLimit=10
syncLimit=5
#zk的数据存储目录
dataDir=/app/zookeeper/data
dataLogDir=/app/zookeeper/dataLog
clientPort=2181
maxClientCnxns=60
autopurge.purgeInterval=48
autopurge.snapRetainCount=5
forceSync=yes
preAllocSize=16384
#zk集群节点信息,server.{myid},myid后续需要写入zkdata目录,参加下面第四步
server.1=biu51:2889:2999
server.2=biu52:2889:2999
server.3=biu53:2889:2999
server.4=biu54:2889:2999
server.5=biu55:2889:2999
3.各个主机上述配置相同,将上述配置同步到5台主机
4.每台主机创建myid文件
每台主机在其zk数据目录下创建文件 “myid”,将该主机在集群节点信息中编号写入该文件。
如第二步配置,则我们需要分别在5台服务器的 /app/zookeeper/data 目录下创建myid文件,biu51写入1,biu52写入2,…。按照zk集群节点配置依次写入
5.启动zookeeper
执行每台主机上启动脚本:{ZK_HOME}/bin/zkServer.sh start
Hadoop安装
1.配置{HADOOP_HOME}/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/app/jdk/jdk1.8.0_231
export HADOOP_HOME=/app/hadoop/hadoop-3.2.1
export HADOOP_CONF_DIR=/app/hadoop/hadoop-3.2.1/etc/hadoop
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root
2.配置{HADOOP_HOME}/etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>/app/hadoop/tmpvalue>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop-biuvalue>
property>
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
configuration>
3.配置{HADOOP_HOME}/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/app/hadoop/tmp/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/app/hadoop/tmp/datavalue>
property>
<property>
<name>dfs.nameservicesname>
<value>hadoop-biuvalue>
property>
<property>
<name>dfs.ha.namenodes.hadoop-biuname>
<value>biu51,biu52,biu53value>
property>
<property>
<name>dfs.namenode.rpc-address.hadoop-biu.biu51name>
<value>biu51:9000value>
property>
<property>
<name>dfs.namenode.rpc-address.hadoop-biu.biu52name>
<value>biu52:9000value>
property>
<property>
<name>dfs.namenode.rpc-address.hadoop-biu.biu53name>
<value>biu53:9000value>
property>
<property>
<name>dfs.namenode.http-address.hadoop-biu.biu51name>
<value>biu51:50070value>
property>
<property>
<name>dfs.namenode.http-address.hadoop-biu.biu52name>
<value>biu52:50070value>
property>
<property>
<name>dfs.namenode.http-address.hadoop-biu.biu53name>
<value>biu53:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://biu51:8485;biu52:8485;biu53:8485;biu54:8485;biu55:8485/hadoop-biuvalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.hadoop-biuname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>shell(/bin/true)value>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/app/hadoop/tmp/qjournalvalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>biu51:2181,biu52:2181,biu53:2181,biu54:2181,biu55:2181value>
property>
configuration>
3.配置{HADOOP_HOME}/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
4.配置{HADOOP_HOME}/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.msname>
<value>2000value>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>hadoop-biuvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>biu51,biu52,biu53value>
property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.hostname.biu51name>
<value>biu51value>
property>
<property>
<name>yarn.resourcemanager.hostname.biu52name>
<value>biu52value>
property>
<property>
<name>yarn.resourcemanager.hostname.biu53name>
<value>biu53value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.biu51name>
<value>biu51:18088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.biu52name>
<value>biu52:18088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.biu53name>
<value>biu53:18088value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>biu51:2181,biu52:2181,biu53:2181,biu54:2181,biu55:2181value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>6144value>
property>
configuration>
5.配置{HADOOP_HOME}/etc/hadoop/workers,将DataNode的主机名写入
biu51
biu52
biu53
biu54
biu55
6.以上配置每台主机都相同,所以将如上配置以及Hadoop的安装包分发到每台主机
7.启动服务
-
首先保证zk是启动状态
-
启动JournalNode:
{HADOOP_HOME}/sbin/hadoop-daemon.sh start journalnode -
格式化ZK:
{HADOOP_HOME}/bin/hdfs zkfc -formatZK -
格式化HDFS:
{HADOOP_HOME}/bin/hdfs namenode -format
选择一台NodeNode节点执行HDFS格式化,格式化后将当前节点的NameNode元数据拷贝到其他NameNode节点,元数据存放位置是hdfs-site.xml中dfs.namenode.name.dir该项配置的
-
启动HDFS:
{HADOOP_HOME}/sbin/start-dfs.sh -
启动yarn:
{HADOOP_HOME}/sbin/start-yarn.sh
验证
查看进程
其中biu51中两个RunJar进程为其他服务的进程,不在本次Hadoop安装所需要进程
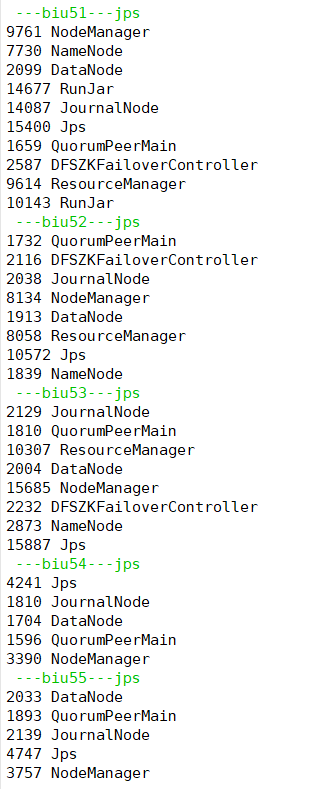
hdfs web页面
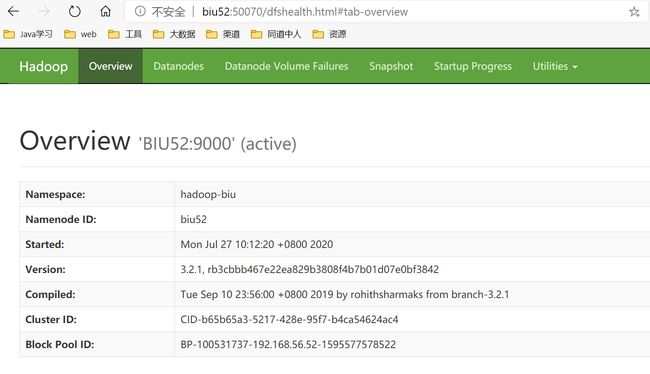
YARN web页面
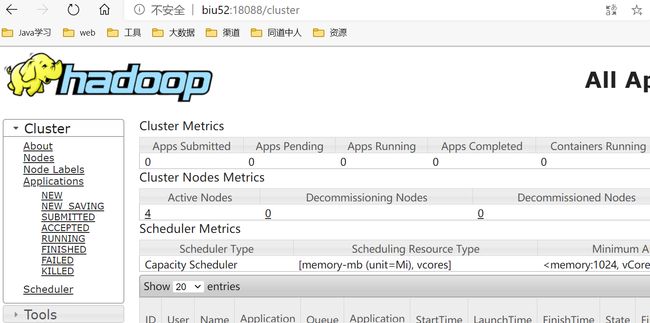
个人公众号【爱做梦的锤子】,全网同id,个站 http://te-amo.site,欢迎关注,里面会分享更多有用知识
觉得不错就点个赞叭QAQ