kafka-producer参数详细
producer参数
主要介绍下kafka的producer配置参数,只取了其中的一部分常用的,后续的有时间,也会补充一些,更多的详细参数,可以参考《kafka官网连接》,参数的内容,主要是选取《apache kafka实战》书中的一些讲解和官网相互参看
bootstrap.servers
该参数指定了一组 host:port 对,用于创建向 Kafka broker 服务器的连接,比如 kl:9092, k2:9092,k3 :9092。上面的代码清单中指定了 localhost:9092, producer 使用时需要替换成实际的 broker 列表。如果 Kafka 集群中机器数很多,那么只需要指定部分 broker 即可,不需要列出所 有的机器。因为不管指定几台机器, producer 都会通过该参数找到井发现集群中所有的 broker。 为该参数指定多台机器只是为了故障转移使用。这样即使某一台 broker 挂掉了, producer 重启 后依然可以通过该参数指定的其他 broker 连入 Kafka 集群。 另外,如果 broker 端没有显式配置 listeners 使用 IP 地址,那么最好将该参数也配置成主 机名,而不是 IP 地址。因为 Kafka 内部使用的就是 FQDN (Fully Qualified Domain Name )。
key.serializer
被发送到 broker 端的任何消息的格式都必须是宇节数组,因此消息的各个组件必须首先做 序列化,然后才能发送到 broker。该参数就是为消息的 key 做序列化之用的。这个参数指定的 是实现了 org.apache.kafka.common.serialization.Serializer 接口的类的全限定名称。 Kafka 为大部 分的初始类型( primitive type )默认提供了现成的序列化器。上面的代码清单中使用了 org.apache. kafka.common.serialization.StringSerializer,该类会将一个字符串类型转换成字节数组 。 这个参数也揭示了一个事实,那就是用户可以自定义序列化器,只要实现 Serializer 接口即可。 需要注意的是,即使 producer 程序在发送消息时不指定 key,这个参数也是必须要设置的, 否则程序会抛出 ConfigException 异常,提示“ key.serializer”参数无默认值,必须要配置。
value.serialize
和 key.serializer 类似,只是它被用来对消息体(即消息 value )部分做序列化,将消息 value 部分转换成宇节数组 。上面的代码清单中该参数指定了与 key.serializer 相同的值,即都 使用 StringSerializer。当然了, value.serializer 也可以设置成与 key. serializer 不同的值 。 一定要注意的是,这两个参数都必须是全限定类名。只使用单独的类名是不行的,比如只 是指定 StringSerializer 是不够的,必须是 org.apache.kafka.common.serialization.Serializer 这样的 形式。这一规定对于自定义序列化也是适用的。
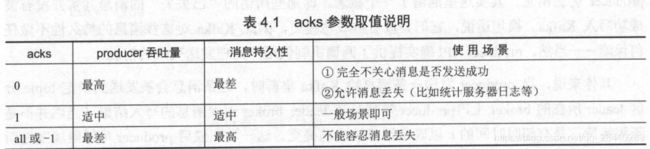
acks
acks 参数用于控制 producer 生产消息的持久性( durability ) 。 对于 producer 而言, Kafka 在乎的是“己提交”消息的持久性。一旦消息被成功提交,那么只要有任何一个保存了该消息 的副本“存活”,这条消息就会被视为“不会丢失的” 。 经常碰到有用户抱怨 Kafka 的 producer 会丢消息,其实这里混淆了 一个概念,即那些所谓的“己丢失”的消息其实并没有被 成功写入 Kafka 。 换句话说,它们井没有被成功提交,因此 Kafka 对这些消息的持久性不做任 何保障一一当然, producer API 确实提供了回调机制供用户处理发送失败的情况。 具体来说,当 producer 发送一条消息给 Kafka 集群时,这条消息会被发送到指定 topic 分 区 leader 所在的 broker 上, producer 等待从该 leader broker 返回消息的写入结果(当然并不是 无限等待,是有超时时间的)以确定消息被成功提交。这一切完成后 producer 可以继续发送新 的消息 。 Kafka 能够保证的是 consumer 永远不会读取到尚未提交完成的消息一一这和关系型数 据库很类似,即在大部分情况下,某个事务的 SQL 查询都不会看到另一个事务中尚未提交的 数据 。
显然, leader broker 何时发送写入结果返还给 producer 就是一个需要仔细考虑的问题了, 它也会直接影响消息的持久性甚至是 producer 端的吞吐量: producer 端越快地接收到 leader broker 响应,它就能越快地发送下一条消息,即吞吐量也就越大 。 producer 端的 acks 参数就是 用来控制做这件事情的 。 acks 指定了在给 producer 发送响应前, leader broker 必须要确保己成 功写入该消息的副本数 。 当前 acks 有 3 个取值: 0、 l 和 all 。
-
acks = 0 :设置成 0 表示 producer 完全不理睬 leader broker 端的处理结果。此时, producer 发送消息后立即开启下一条消息的发送,根本不等待 leader broker 端返回结果 。 由于不接收发送结果,因此在这种情况下 producer.send 的回调也就完全失去了作用, 即用户无法通过回调机制感知任何发送过程中的失败,所以 acks=O 时 producer 并不保 证消息会被成功发送。但凡事有利就有弊,由于不需要等待响应结果,通常这种设置 下 producer 的吞吐量是最高的
-
acks = all 或者- 1 :表示当发送消息时, leader broker 不仅会将消息写入本地日志,同时 还会等待 ISR 中所有其他副本都成功写入它们各自的本地日志后,才发送响应结果给 producer。显然当设置 acks=all 时,只要 ISR 中 至少有一个副本是处于“存活”状态的 , 那么这条消息就肯定不会丢失,因而可以达到最高的消息持久性,但通常这种设置下 producer 的吞吐量也是最低的 。
-
acks = 1 :是 0 和 all 折中的方案,也是默认的参数值。 producer 发送消息后 leader broker 仅将该消息写入本地日志,然后便发送响应结果给 producer ,而无须等待 ISR 中其他副本写入该消息。 那么此时只要该 leader broker 一直存活 , Kafka 就能够保证这 条消息不丢失。这实际上是一种折中方案,既可以达到适当的消息持久性,同时也保 证了 producer 端的吞吐量。
总结一下, acks 参数控制 producer 实现不同程度的消息持久性,它有 3 个取值,对应的优 缺点以使用场景如表 4.1 所示。
buffer.memory
该参数指定了 producer 端用于缓存消息的缓冲区大小,单位是字节,默认值是 33554432, 即 32MB 。 如前所述,由于采用了异步发送消息的设计架构, Java 版本 producer 启动时会首先 创建一块内存缓冲区用于保存待发送的消息,然后由另 一个专属线程负责从缓冲区中读取消息 执行真正的发送。这部分 内存空间的大小即是由 buffer.memory 参数指定的。若 producer 向缓 冲区写消息的速度超过了专属 1/0 线程发送消息的速度,那么必然造成该缓冲区空间的不断增 大。此时 producer 会停止手头的工作等待 1/0 线程追上来,若一段时间之后 1/0 线程还是无法 追上 producer 的进度,那么 producer 就会抛出异常并期望用户介入进行处理。
虽说 producer 在工作过程中会用到很多部分的内存,但我们几乎可以认为该参数指定的内 存大小就是 producer 程序使用的内存大小。若 producer 程序要给很多分区发送消息,那么就需 要仔细地设置这个参数以防止过小的内存缓冲区降低了 producer 程序整体的吞吐量。
compression.type
compression均pe 参数设置 producer 端是否压缩消息,默认值是 none ,即不压缩消息 。和 任何系统相同的是, Kafka 的 producer 端引入压缩后可以显著地降低网络 νo 传输开销从而提 升整体吞吐量,但也会增加 producer 端机器的 CPU 开销 。另外,如果 broker 端的压缩参数设 置得与 producer 不同, broker 端在写入消息时也会额外使用 CPU 资源对消息进行对应的解压 缩-重压缩操作。 目前 Kafka 支持 3 种压缩算法: GZIP 、 Snappy 和 LZ4。由于篇幅有限,我们在这里不对 这 3 种压缩算法的优劣进行比较,不过根据实际使用经验来看 producer 结合 LZ4 的性能是最 好的。由于 Kafka 源代码中某个关键设置的硬编码使得 Snappy 的表现远不如 LZ4,因此至少 对于当前最新版本的 Kafka ( 1.0 .0 版本)而言,若要使用压缩, compression均pe 最好设置为 LZ4 。令人感到振奋的是, Facebook 公司于 2016 年 8 月底正式开源了新一代的压缩算法 Zstandard . 该算法有着超高的压缩率(根据其官网测试结果, Zstandard 的压缩率可达 2.8, Snappy 和 LZ4 分别是 2.091 和 2.101 )以及优良的压缩/解压缩速度 。 Kafka 社区己经计划将在 未来的版本中支持该压缩算法,相信在 Kafka 的后续版本中就可以使用 Zstandard 来压缩 producer 发送的消息了 。
retries
Kafka broker 在处理写入请求时可能因为瞬时的故障 (比如瞬时 的 leader 选举或者网络抖 动〉导致消息发送失败。这种故障通常都是可以自行恢复的,如果把这些错误封装进回调函数 的异常中返还给 producer, producer 程序也并没有太多可以做的,只能简单地在回调函数中重 新尝试发送消息。与其这样,还不如 producer 内部自动实现重试。因此 Java 版本 producer 在 内部自动实现了重试,当然前提就是要设置 re仕ies 参数。
该参数表示进行重试的次数,默认值是 0,表示不进行重试。在实际使用过程中,设置重 试可以很好地应对那些瞬时错误,因此推荐用户设置该参数为一个大于 0 的值 。 只不过在考虑 retries 的设置时,有两点需要着重注意 。
-
重试可能造成消息的重复发送一一-比如由于瞬时的网络抖动使得 broker 端己成功写入 消息但没有成功发送响应给 producer,因此 producer 会认为消息发送失败,从而开启 重试机制。为了应对这一风险, Kafka 要求用户在 consumer 端必须执行去重处理 。 令 人欣喜 的是,社区己于 0.11.0.0 版本开始支持“精确一次”处理语义,从设计上避免 了类似的问题 。
-
重试可能造成消息的乱序一一当前 producer 会将多个消息发送请求(默认是 5 个) 缓 存在内存中,如果由于某种原因发生了消息发送的重试,就可能造成消息流的乱序 。 为了避免乱序发生, Java 版本 producer 提供了 max.in.flight.requets.per.connection 参数 。 一旦用户将此参数设置成 1, producer 将确保某一时刻只能发送一个请求 。
另外, producer 两次重试之间会停顿一段时间,以防止频繁地重试对系统带来冲击 。 这段 时间是可以配置的,由参数目的1.backo旺ms 指定,默认是 100 毫秒 。 由于 leader “换届选举 ” 是最常见的瞬时错误,笔者推荐用户通过测试来计算平均 leader 选举时间并根据该时间来设定 retries 和 re问1.backff.ms 的值 。
batch.size
batch.size 是 producer 最重要的参数之一 !它对于调优 producer 吞吐量和延时性能指标都 有着非常重要的作用 。 前面提到过, producer 会将发往同一分区的多条消息封装进一个 batch 巾。当 batch 满了的时候, producer 会发送 batch 中的所有消息 。 不过, producer 并不总是等待 batch 满了才发送消息,很有可能当 batch 还有很多空闲空间时 producer 就发送该 batch 。 显然, batch 的大小就显得非常重要 。 通常来说, 一个小的 batch 中包含的消息数很少,因 而一次发送请求能够写入的消息数也很少,所以 producer 的吞吐量会很低;但若一个 batch 非 常之巨大,那么会给内存使用带来极大的压力,因为不管是否能够填满, producer 都会为该 batch 分配固定大小的内存。因此 batch.size 参数的设置其实是一种时间与空间权衡的体现 。 batch.size 参数默认值是 16384 ,即 16阻 。 这其实是一个非常保守的数字。 在实际使用过 程中合理地增加该参数值,通常都会发现 producer 的吞吐量得到了相应的增加 。
linger.ms
上面说到 batch.size 时,我们提到了消息没有填满 batch 也可以被发送的情况。这是为什么 呢?难道不是等 batch 满了再发送比较好吗?实际上这也是一种权衡,即吞吐量与延时之间的 权衡 。 linger.ms 参数就是控制消息发送延时行为的 。 该参数默认值是 0,表示消息需要被立即 发送,无须关心 batch 是否己被填满,大多数情况下这是合理的 , 毕竟我们总是希望消息被尽 可能快地发送 。 不过这样做会拉低 producer 吞吐量,毕竟 producer 发送的每次请求中包含的消 息数越多 , producer 就越能将发送请求的开销摊薄到更多的消息上 , 从而提升吞吐量。
max.request.size
官网中给出的解释是 , 该参数用于控制 producer 发送请求的大小 。 实际上该参数控制的是 producer 端能够发送的最大消息大小 。 由于请求有一些头部数据结构,因此包含一条消息的请 求的大小要比消息本身大 。 不过姑且把它当作请求的最大尺寸是安全的 。 如果 producer 要发送 尺寸很大的消息 , 那么这个参数就是要被设置的 。默认的 1048576 字节太小 了 , 通常无法满足 企业级消息的大小要求 。
request.timeout.ms
当 producer 发送请求给 broker 后 , broker 需要在规定 的时 间范围 内 将处理结果返还给 produce r 。 这段时间便是由该参数控制的,默认是 30 秒 。 这就是说,如果 broker 在 30 秒内都 没有给 producer 发送响应,那么 producer 就会认为该请求超时了,并在回调函数中显式地抛出 TimeoutException 异常交由用户处理 。 默认的 30 秒对于一般的情况而言是足够的 , 但如果 producer 发送的负载很大 , 超时的情 况就很容易碰到,此时就应该适当调整该参数值。