Python学习笔记 -- Pyhthon pandas 如何基于一列或多列运算并生成新的列
Python学习笔记 – Pyhthon pandas 如何基于一列或多列运算并生成新的列
在数据处理中,通过前面几列的运算生成一个新列。
最常见的例子是计算成绩 : )
1.eval()
eval是最直接的
举个栗子:
我们这里就用最常见需要增加列的情景之一 成绩统计~
已经有每一门学科的成绩,需要在最后新增一列总分:
df = pd.DataFrame({'math':[89,78,83],'physics':[76,84,96],'chemistry':[87,81,92]})
df.index =["tom","mark","ann"]
print (df)
df.eval('Total = math + physics + chemistry', inplace = True)
print (df)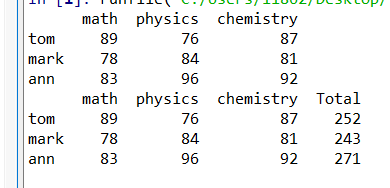
此时通过运行结果可以看出,已经出现新的一列"Total"
inplace参数表示是否在原数据上进行操作,如果inplace = Flase,则会生成新的DataFrame。
2.apply()
apply来添加列也很常见好用
承接上面的例子,我们还想新增一列看看每个人的平均分:
df ["Ave"] = df.Total.apply(lambda x: round(x/3))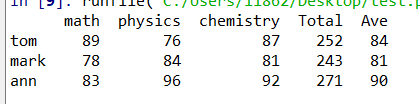
这里的"x"是指Total列的值,也可以写成 df[“Total”].apply
通过运行结果可以看出已经增加新的一列"Ave"
3.map()
还有一种情况用map可以解决。如果涉及到需要使用多个条件语句的时候(如在成绩中需要分出优良中差),用前面两种方法会显得在括号里面的内容过多,导致代码看着比较乱,这时用map就相对清晰明了(ง •_•)ง
def total_allocate(n):
if n > 270:
return "excellent job"
elif 250 < n < 270:
return "good job"
else:
return "need to progress"
df ["Comment"] = df.Total.map(total_allocate)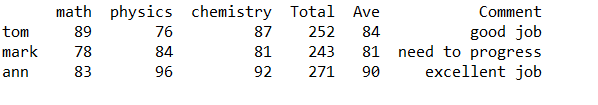
同上,df.Total.map也可以写成 df[“Total”].map
总结了三种添加新的列的方法,在今后的学习中如果遇见了其他的方法更适合解决某类问题也会在这里更新哒!(。・∀・)ノ