pandas常用命令汇总
目录
01_Getting_&_Knowing_Your_Data
02_Filtering_&_Sorting
03_Groupby
04_Apply
01_Getting_&_Knowing_Your_Data
1、读取csv文件
pd.read_csv(file_path,step='\t')2、数据集行列信息
df.shape # 行数、列数
df.shape[0] or len(df) #行数
df.shape[1] #列数
df.index #索引信息
df.columns #列名称
df['column_dtype'] #某列类型
df.info #数据集基本信息:列名、非空行数、类型
df.head(10) #前10行
df.tail(10) #后10行
3、排序
df.sort_values(column,ascending=False) #df按照column降序排列
df.sort_values(column,ascending=False).head(1) #取df最大的一行
df.groupby('column1').sum().sort_values('column2',ascending=False).head(1) #df按c1分组、求和,然后按照c2降序排序,取最大一行4、某列值求和、求平均
df['c1'].sum() #求和
df.c1.mean() #求平均
ps :选取一列的两种方式5、转换一列数据类型
#str =>float
str_to_float = lambda x : float(x[1:-1]) #利用切片删除第一个字符
df['columns'].apply(str_to_float) # 利用apply 转换df列6、查看列中有哪些不同值、每个值有多少重复值
df.column.value_counts() #column的不同的值,每种值有多少个
df.column.value_counts().count() #column列有几个不同的值7、选取行
df.iloc[18] #df 第19行数据,索引从0开始
df.loc['column_name'] #按照行名称选取行
8、数据集的摘要
df.describe() #数值列的信息
df.describe(include='all') #所有列的信息9、选取多列
df[['c1','c2']] #选取 c1列和c2列
df.loc[:,'c1':'c2'] #选取c1到c2列10、删除一列
del df['c1'] #删除 c1列
02_Filtering_&_Sorting
1、删除某列重复数据
data=data.drop_duplicates(column,keep='first',inplace=False)
#删除column列的重复值,可以是列表即列的组合
#keep='first'表示保留第一次出现的重复行,是默认值
#inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本
2、根据某列列的值筛选df的行
df[(df.c1 == 'xxx') & (df.c2 > 10)] #过滤出:c1列为字符串'xxx' 并且 c2 > 10 的行3、某列排序 vs df按照某列排序
df['c1'].sort_values() #选取某列,然后排序
df.sort_values(by=['c1','c2'],ascending=False) #df按照c1、c2排序4、筛选某列以字母'G'开头的行
df[df.column.str.startswich('G')]
#Series.str.startswith(pat, na=nan)查看元素是否以…开头
#参数: pat : 字符串 na : 布尔值
#返回: 序列Series/向量array5、选取前7列
df.iloc[:,0:7]6、选取c1列值为'a','b','c' 的c1、c2列
df.loc[df.c1.isin(['a', 'b', 'c']), ['c1','c2']]7、选取3-7行、3-6列
df.iloc[3:7,3:6]8、选取某列不包含字符串’xxx‘的行
df[ df.column != 'xxx']9、选取索引为’a‘和'b'的行
df.loc[['a','b']]10、生成一个从15000到73000的随机整数series,大小为398
owners = np.random.randint(15000,high=73001,size=398,dtype='l')
03_Groupby
1、根据c1分组,求c2列分组后的平均值
df.groupby('c1').c2.mean() # 分组后c2列的均值
df.groupby('c1').mean() #分组后每列的均值2、分组中位数
df1.groupby('c1').median()3、分组后某一列的mean,min,max
df.groupby('c1).c2.agg(['mean','min','max'])4、按照职业、性别分组,求年龄平均值
df.groupby(['occupation','gender']).age.mean()5、打印出分组后的结果
for name,group in df.groupby('c1'):
print(name)
print(group)04_Apply
1、df的某列应用匿名函数:首字母大写 series元素函数映射: apply()函数 ,原df的列不变
df['c1'].apply(lambda x: x.capitalize())2、df应用函数:每个元素扩大10倍 df元素映射函数:applymap() ,原df不变
def times10(x):
if type(x) is int:
return x * 10
else:
return x
df.applymap(times10).head(10)3、df时间类型转换:str转换为datetime
df.date = pd.to_datetime(df.date,format="%Y%m%d")4、将改好格式的date列,设置为df的index
df.set_index('date',drop=True) #将date列设置为index ,并且在原df中删除df 列5、按时间提数 (因为此时的datetime已经为index了,可以直接[]取行内容)
#按年提数
df['2018']
df['2018':'2021']
#按月提数
df['2018-01']
df['2018-01':'2018-05']
#按天提数
df['2018-05-24':'2018-09-27']6、按日期汇总数据
#将数据以W星期,M月,Q季度,QS季度的开始第一天开始,A年,10A十年,10AS十年聚合日期第一天开始.的形式进行聚合
df.resample('W').sum()
df.resample('M').sum()
#具体某列的数据聚合
df.price.resample('W').sum().fillna(0) #星期聚合,以0填充NaN值
#某两列
df[['price','num']].resample('W').sum().fillna(0)
#某个时间段内,以W聚合,
df["2018-5":"2018-9"].resample("M").sum().fillna(0)7、df每列最大值的索引
df.idmax()
或
df.argxmax()05_merge
merge
- 默认内连接
- left_on、right_on指定用于连接的列
- left_index=True right=true 用航索引来连接
- suffixes:用于指定附加到左右连个DataFrame对象的重叠列名上的字符串
join
- 按索引合并两个没有重复列的DataFrame
- 默认左连接
- 可同时连接两个以上的DataFrame :df.join([df1,df2])
concat
- 默认纵向连接,axis=1会横向连接series 变成DataFrame
- 默认连接方式是outer
1、两个DataFrame纵向合并:pd.concat()
cars =pd. concat([cars1,cars2])
cars.reset_index()
#reset_index可以还原索引,从新变为默认的整型索引
#DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=”)
#level控制了具体要还原的那个等级的索引
#drop为False则索引列会被还原为普通列,否则会丢失2、两个dataFrame横向合并:axis=1
all_data_col = pd.concat([data1,data2],axis=1)3、按照相同的列左右连接:默认内连接
pd.merge(all_data,data3,on='subject_id') #subject_id 为两个df的连接列4、按照相同的列左右连接:外连接的方式
pd.merge(data1,data2,on='subject_id',how='outer')日期数据处理
pandas有着强大的日期数据处理功能,本期我们来了解下pandas处理日期数据的一些基本功能,主要包括以下三个方面:
- 按日期筛选数据
- 按日期显示数据
- 按日期统计数据
1.读取并整理数据
- 首先引入pandas库
import pandas as pd
- 从csv文件中读取数据
df = pd.read_csv('date.csv', header=None)
print(df.head(2))
0 1
0 2013-10-24 3
1 2013-10-25 4
- 整理数据
df.columns = ['date','number']
df['date'] = pd.to_datetime(df['date']) #将数据类型转换为日期类型
df = df.set_index('date') # 将date设置为index
- df的行数一共是425行。
查看DataFrame的数据类型
print(type(df))
print(df.index)
print(type(df.index))
DatetimeIndex(['2013-10-24', '2013-10-25', '2013-10-29', '2013-10-30',
'2013-11-04', '2013-11-06', '2013-11-08', '2013-11-12',
'2013-11-14', '2013-11-25',
...
'2017-01-03', '2017-01-07', '2017-01-14', '2017-01-17',
'2017-01-23', '2017-01-25', '2017-01-26', '2017-02-07',
'2017-02-14', '2017-02-22'],
dtype='datetime64[ns]', name='date', length=425, freq=None)
2 按日期筛选数据
获取年度数据
df['2013'] #获取2013年数据
df['2016':'2017'] #获取2016至2017年数据获取某月数据
df['2013-11'] #获取2013年11月数据dataframe结构的数据用区间的方式获取某天的数据
df['2013-11-06':'2013-11-06']
3 按日期显示数据
3.1 to_period()方法
- 请注意df.index的数据类型是DatetimeIndex;
- df_peirod的数据类型是PeriodIndex
按月显示
df.to_period('M') #按月显示,但不统计
按季度显示
df.to_period('Q') #按季度显示,但不统计按年度显示
df.to_period('A') #按年度显示,但不统计3.2 asfreq()方法
按年度频率显示
df.index.asfreq('A') #'A'默认是'A-DEC',其他如'A-JAN’PeriodIndex(['2013', '2013', '2013', '2013', '2013', '2013', '2013', '2013',
'2013', '2013',
...
'2017', '2017', '2017', '2017', '2017', '2017', '2017', '2017',
'2017', '2017'],
dtype='period[A-DEC]', name='date', length=425, freq='A-DEC')df_period.index.asfreq('A-JAN') # 'A'默认是'A-DEC',其他如'A-JAN'PeriodIndex(['2014', '2014', '2014', '2014', '2014', '2014', '2014', '2014',
'2014', '2014',
...
'2017', '2017', '2017', '2017', '2017', '2017', '2017', '2018',
'2018', '2018'],
dtype='period[A-JAN]', name='date', length=425, freq='A-JAN')- 按年度频率在不同情形下的显示,可参考下图所示:
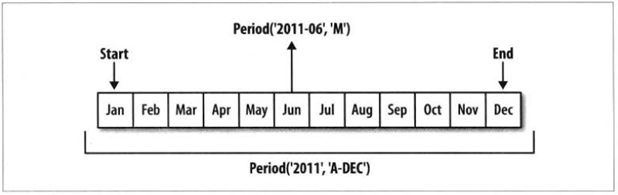
按季度频率显示
df_period.index.asfreq('Q') # 'Q'默认是'Q-DEC',其他如“Q-SEP”,“Q-FEB”- 按季度频率在不同情形下的显示,可参考下图所示:

按工作日显示
- method 1
df_period.index.asfreq('B', how='start') # 按工作日期显示
PeriodIndex(['2013-10-01', '2013-10-01', '2013-10-01', '2013-10-01',
'2013-11-01', '2013-11-01', '2013-11-01', '2013-11-01',
'2013-11-01', '2013-11-01',
...
'2017-01-02', '2017-01-02', '2017-01-02', '2017-01-02',
'2017-01-02', '2017-01-02', '2017-01-02', '2017-02-01',
'2017-02-01', '2017-02-01'],
dtype='period[B]', name='date', length=425, freq='B')
- method 2
df_period.index.asfreq('B', how='end') # 按工作日期显示
PeriodIndex(['2013-10-31', '2013-10-31', '2013-10-31', '2013-10-31',
'2013-11-29', '2013-11-29', '2013-11-29', '2013-11-29',
'2013-11-29', '2013-11-29',
...
'2017-01-31', '2017-01-31', '2017-01-31', '2017-01-31',
'2017-01-31', '2017-01-31', '2017-01-31', '2017-02-28',
'2017-02-28', '2017-02-28'],
dtype='period[B]', name='date', length=425, freq='B')4.按日期统计数据
4.1按日期统计数据
按周统计数据
print(df.resample('w').sum().head())
# “w”,week number
date
2013-10-27 7.0
2013-11-03 3.0
2013-11-10 5.0
2013-11-17 7.0
2013-11-24 NaN按月统计数据
print(df.resample('M').sum().head())
#MS是每个月第一天,M是每个月最后一天按季度统计数据
print(df.resample('Q').sum().head())
#QS是每个季度第一天为开始日期,“Q是每个季度最后一天” number
date
2013-12-31 51
2014-03-31 73
2014-06-30 96
2014-09-30 136
2014-12-31 148
按年统计数据
print(df.resample('AS').sum())
#AS是每年第一天为开始日期,“A”是每年最后一天 number
date
2013-01-01 51
2014-01-01 453
2015-01-01 743
2016-01-01 1552
2017-01-01 92关于日期的类型,按参考下图所示来选择合适的分期频率:
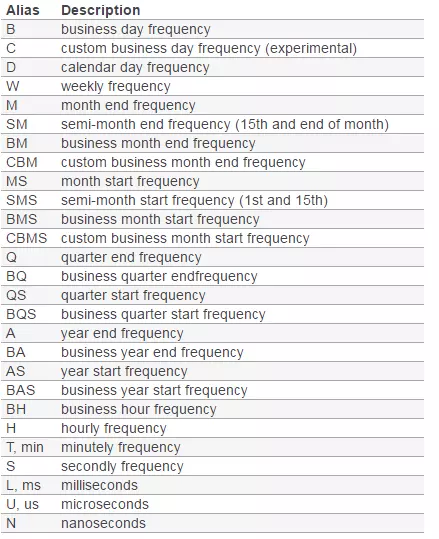
4.2按日期统计后,按年或季度或月份显示
按年统计并显示
print(df.resample('AS').sum().to_period('A'))
# 按年统计并显示 number
date
2013 51
2014 453
2015 743
2016 1552
2017 92按季度统计并显示
print(df.resample('Q').sum().to_period('Q').head())
# 按季度统计并显示
number
date
2013Q4 51
2014Q1 73
2014Q2 96
2014Q3 136
2014Q4 148按月度统计并显示
print(df.resample('M').sum().to_period('M').head())
# 按月度统计并显示 number
date
2013-10 10
2013-11 14
2013-12 27
2014-01 16
2014-02 406 Stats
1、读取数据,前三列解析为日期
data = pd.read_csv(data_url, sep = "\s+", parse_dates = [[0,1,2]]) #原本数据前三列分别是年月日2、统计每列中的空值
data.isnull.sum()3、每列中不为空的值
df.notnull().sum()4、整个数据集的平均值
data.fillna(0).values.flatten().mean() #先填充空值,在用flatten降维,然后计算平均值5、求每一行的最大/最小/平均值
day_stats = pd.DataFrame()
day_stats['min'] = data.min(axis=1)
day_stats['max'] = data.max(axis=1)
day_stats['std'] = data.std(axis=1)
day_stats.head(10)6、数据集中每年一月份的平均值
df.loc[data.index.month==1].mean() #索引是datetime类型,可直接取月份7、记录数据按照年份求平均值
data.resample('A').mean().to_period('A') #resample :升采样到年,求均值,然后按照年份显示数据
#不写to_period 日期索引会显示为:1961-12-31
#写上to_period 日期索引会显示为:19618、按照月份显示数据
data.to_period('M')9、按照星期显示数据
data.to_period('W')10、重采样到周,求每列的最小、最大、平均、标准差
data.resample('W').agg(['min','max','mean','std'])09_Time_Series
1、判断列值是否为唯一
df.index.is_unique2、索引为时间类型的天数差
(df.index.max() - df.index.min()).days3、有几个月份的数据
df = apple.resample('BM').mean()
len(df.index)10_Deleting
1、重新命名列
columns = ['a','b','c']
df.coumns = columns2、查看数据集中有没有有缺失值
pd.isnull(df).sum()3、用特定值代替数据集中缺失值
df.fillna(1,inplace=True)#inplace=True表示替换原df4、删除有缺失值的行
df.dropna(how='any')5、重新索引,从0开始
df.reset_index(drop=True) #drop=True 表示丢掉原来的索引,不将所用作为新的一列