python爬虫09:scrapy数据写入json并录入mysql
scrapy配置items数据写入json当中
scrapy数据的保存都交由 pipelines.py 处理,接前几篇,
导出文件的常用格式和方法(scrapy自带的): https://docs.scrapy.org/en/latest/topics/exporters.html
scrapy自带的用不好还是自己写控制吧
scrapy自带的json exporter的源码:
class JsonItemExporter(BaseItemExporter):
def __init__(self, file, **kwargs):
super().__init__(dont_fail=True, **kwargs)
self.file = file
# there is a small difference between the behaviour or JsonItemExporter.indent
# and ScrapyJSONEncoder.indent. ScrapyJSONEncoder.indent=None is needed to prevent
# the addition of newlines everywhere
json_indent = self.indent if self.indent is not None and self.indent > 0 else None
self._kwargs.setdefault('indent', json_indent)
self._kwargs.setdefault('ensure_ascii', not self.encoding)
self.encoder = ScrapyJSONEncoder(**self._kwargs)
self.first_item = True
def _beautify_newline(self):
if self.indent is not None:
self.file.write(b'\n')
def start_exporting(self):
self.file.write(b"[")
self._beautify_newline()
def finish_exporting(self):
self._beautify_newline()
self.file.write(b"]")
def export_item(self, item):
if self.first_item:
self.first_item = False
else:
self.file.write(b',')
self._beautify_newline()
itemdict = dict(self._get_serialized_fields(item))
data = self.encoder.encode(itemdict)
self.file.write(to_bytes(data, self.encoding))
pipelines.py追加写上
import codecs
import json
class JsonWithEncodingPipeline(object):
# 自定义json文件的导出
# 注意方法的名称不能乱写,都是固定好的
def __init__(self):
self.file = codecs.open("article.json", "a", encoding="utf8") # 打开文件
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + "\n" # 注意ensure_ascii一定要设为False,不然可能会出错
self.file.write(lines)
return item # 习惯上要return item
def spider_close(self, spider):
self.file.close()
# 用自带的exporter的方式
from scrapy.exporters import JsonItemExporter
class JsonExporterPipeline(object):
def __init__(self):
self.file = open("articleexport.json", 'ab')
def process_item(self, item, spider):
self.exporter = JsonItemExporter(self.file, encoding='utf8', ensure_ascii=False)
self.exporter.start_exporting()
self.exporter.export_item(item)
self.exporter.finish_exporting()
return item # 习惯上要return item
def spider_close(self, spider):
self.exporter.finish_exporting()
self.file.close()
settings.py补上:
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'ArticleSpider.pipelines.ArticlespiderPipeline': 300,
'ArticleSpider.pipelines.ArticleImagePipelines': 1,
'ArticleSpider.pipelines.JsonWithEncodingPipeline': 2,
'ArticleSpider.pipelines.JsonExporterPipeline': 3,
}
数据库选择mysql,为操作方便使用navicat
设计表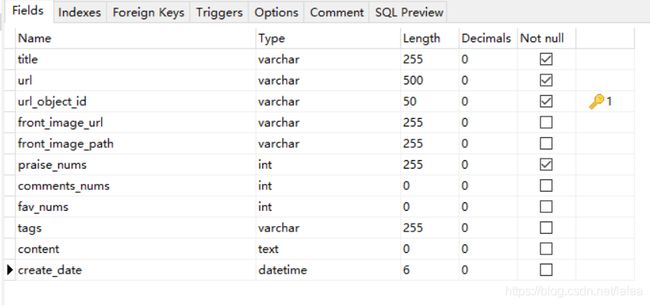
pipelines.py 加上
import MySQLdb
class MysqlPipeline(object):
def __init__(self):
self.conn = MySQLdb.connect("127.0.0.1", 'root', '', 'article_spider', charset='utf8', use_unicode=True)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
insert_sql = """
insert into jobbole_aricle(title, url, url_object_id, front_image_url, front_image_path, praise_nums, comments_nums,
fav_nums, tags, content, create_date)
values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
params = list()
params.append(item.get('title', '')) # 健壮性体现
params.append(item.get('url', ''))
params.append(item.get('url_object_id', ''))
front_image_list = ','.join(item.get('front_image_url', '')) # 入库时候是字符串
params.append(front_image_list)
params.append(item.get('front_image_path', ''))
params.append(item.get('praise_nums', 0))
params.append(item.get('comments_nums', 0))
params.append(item.get('fav_nums', 0))
params.append(item.get('tags', ''))
params.append(item.get('content', ''))
params.append(item.get('create_date', '1999-09-09'))
self.cursor.execute(insert_sql, tuple(params))
self.conn.commit()
return item
之后把这个pip一样配置到settings中
入库成功

由于解析速度远大于入库速度,入库需要异步化
异步写入:
# 异步写入
from twisted.enterprise import adbapi
class MysqlTwistedPipeline(object):
@classmethod
def from_settings(cls, settings): # 从setting py文件中读取, 方便配置. 这个方法名称固定
from MySQLdb.cursors import DictCursor
dbparams = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWORD'],
charset='utf8',
cursorclass=DictCursor,
use_unicode=True,
)
dbpool = adbapi.ConnectionPool('MySQLdb', **dbparams) # 注意**不要漏
return cls(dbpool)
def __init__(self, dbpool):
self.dbpool = dbpool
def process_item(self, item, spider):
queue = self.dbpool.runInteraction(self.do_insert, item) # 将某个方法扔到池里执行
queue.addErrback(self.handle_error, item, spider) # 出错时的回调
def do_insert(self, cursor, item):
insert_sql = """
insert into jobbole_aricle(title, url, url_object_id, front_image_url, front_image_path, praise_nums, comments_nums,
fav_nums, tags, content, create_date)
values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
title=VALUES(title),
url=VALUES(url),
front_image_url=VALUES(front_image_url),
front_image_path=VALUES(front_image_path),
praise_nums=VALUES(praise_nums),
comments_nums=VALUES(comments_nums),
fav_nums=VALUES(fav_nums),
tags=VALUES(tags),
content=VALUES(content),
create_date=VALUES(create_date)
"""
# 上方还处理了主键冲突
params = list()
params.append(item.get('title', '')) # 健壮性体现
params.append(item.get('url', ''))
params.append(item.get('url_object_id', ''))
front_image_list = ','.join(item.get('front_image_url', ''))
params.append(front_image_list)
params.append(item.get('front_image_path', ''))
params.append(item.get('praise_nums', 0))
params.append(item.get('comments_nums', 0))
params.append(item.get('fav_nums', 0))
params.append(item.get('tags', ''))
params.append(item.get('content', ''))
params.append(item.get('create_date', '1999-09-09'))
cursor.execute(insert_sql, tuple(params))
def handle_error(self, failure, item, spider):
print(failure)
记得配置给settings