【数据挖掘重要笔记day15】pandas知识的复习+pandas的拼接操作+合并
文章目录
- pandas知识的复习
- 枚举
- DataFrame的获取方式
- NaN
- 多层级索引
- 行列堆变换
- 聚合
- 属性
- 内容概览
- pandas的拼接操作
- 0. 回顾numpy的级联
- 使用Pandas连接MySQL获取数据
- 1. 使用pd.concat()级联
- 1) 简单级联
- 2) 不匹配级联
- 使用concat()模拟联合查询
- 3) 使用append()函数添加
- 2. 使用pd.merge()合并
- 将id设置为行号
- 重新设置行索引
- 指定关联列
- 关联列是行索引
- 5) 内合并与外合并
- 6) 列冲突的解决
本文所用数据 链接:https://pan.baidu.com/s/1eIebO6zS4r2VE190FCqUuQ 提取码:2zhi
pandas知识的复习
Pandas继承了numpy Series:绝对一维的 DataFrame:绝对二维
枚举
连续的,半闭区间,切片 关联:离散的,闭区间,获取
DataFrame的获取方式
[]只能获取列索引 显示索引:.loc[y,x] 隐式索引:.iloc[y,x]
从其它地方获取数据:Excel、csv、txt、sql、html… pd.read_csv()
NaN
pd.isnull() pd.notnull() dropna(axis=0) fillna()
多层级索引
Excel读取,在我们制作透视表
行列堆变换
stack()列转行 unstack()行转列
聚合
std()样本标准差 var()样本方差 pd中,所有的聚合运算都是忽略NaN
属性
df.columns df.index df.values df.dtypes df.info()
如果有遗忘的,欢迎移步专栏 【数据挖掘专栏】
内容概览
pandas的拼接操作
pandas 和 mysql 非常的相似,
mysql可以对数据进行统计
pandas主要作用就是对数据进行一个统计
pandas 也有类似于 left join 的操作 select union select
#相当于Mysql中的联表查询,联合查询
pd.concat(), pd.append() pd.merge()
0. 回顾numpy的级联
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
nd1 = np.random.randint(0,10,(5,4))
nd2 = np.random.randint(0,10,(5,4))
#(select * from nd1) union (select * from nd2)
np.concatenate([nd1,nd2],axis=0)

使用Pandas连接MySQL获取数据
conn = create_engine("mysql+pymysql://root:123456@localhost:3306/demo?charset=utf8")
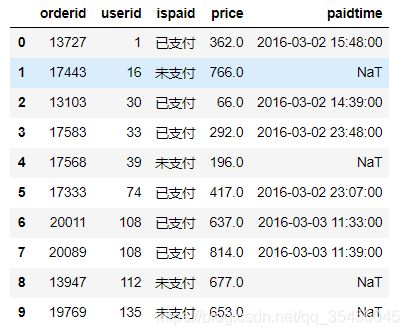
sql1 = "select * from order_info order by userid limit 10;"
order_info = pd.read_sql(sql1,conn)
order_info
#筛选id
uid = order_info[order_info.paidtime.notnull()].userid
uid = tuple(uid.tolist() + [2])
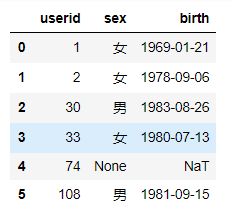
sql2 = f"select * from user_info where userid in {uid};"
user_info = pd.read_sql(sql2,conn)
user_info
1. 使用pd.concat()级联
pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
1) 简单级联
和np.concatenate一样,优先增加行数(默认axis=0)
import warnings
warnings.filterwarnings('ignore')
order_info.columns
![]()
user_info.columns
![]()
#concat的值必须是一个序列类型
#'inner' 内连接 'outer'外连接
#相同的列名会保留
all_data = pd.concat([user_info,order_info],axis=0,join='outer')
all_data.loc[4]

可以通过设置axis来改变级联方向
注意index在级联时可以重复
也可以选择忽略ignore_index,重新索引
pd.concat([user_info,order_info],axis=0,join='inner',ignore_index=True)

或者使用多层索引 keys
concat([x,y],keys=['x','y'])
keys_data = pd.concat([user_info,order_info],axis=0,join='outer',keys=['user_info','order_info'])
keys_data.loc['user_info',0]

2) 不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有3种连接方式:
- 外连接:补NaN(默认模式)
pd.concat([user_info,order_info],axis=0,join='outer',ignore_index=True)
- 内连接:只连接匹配的项
#axis=1代表使用行号进行关联
pd.concat([user_info,order_info],axis=1,join='inner',ignore_index=True)
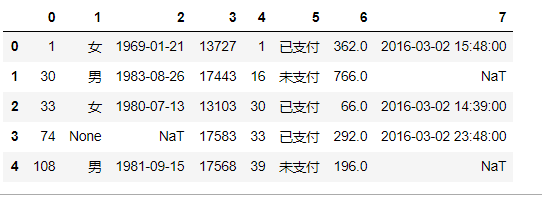
使用concat()模拟联合查询
(select * from user_info limit 10) union (select userid,orderid,paidtime from order_info limit 10) ;
- 要求联合查询的字段数量要相同
- 数据类型可以不相同
- 两边的字段名称可以不相同
- 字段名称显示问题以左边的表为基准
#user_info中的数据符合union的条件
#我们只需要在order_info中挑选3列数据既可
union_right = order_info.loc[:,['userid','orderid','paidtime']]
#把列名称修改成一致的
union_right.columns = user_info.columns
pd.concat([user_info,union_right],ignore_index=True,join='outer',axis=0)
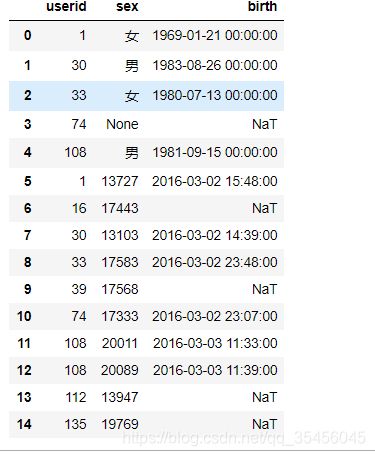
3) 使用append()函数添加
由于在后面级联的使用非常普遍,因此有一个函数append专门用于在后面添加
append 和 concat 相似
user_info.append(union_right,ignore_index=True)

2. 使用pd.merge()合并
merge与concat的区别在于,merge需要依据某一共同的行或列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
注意每一列元素的顺序不要求一致
user_info
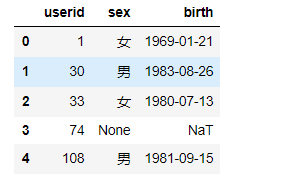
order_info

- inner 内连接,两边的关联字段对等则返回,否则过滤
- left 左外连接,以左表中的关联字段为主,如果右边中的字段不匹配,则填补Null
- right 右外连接,以右表中的关联字段为主,如果左边中的字段不匹配,则填补Null
- outer 全外连接,如果两边的数据不对等,则两边全部填补Null
#how= 'left', 'right', 'outer', 'inner'
#merge会自动寻找同名字段,作为关联
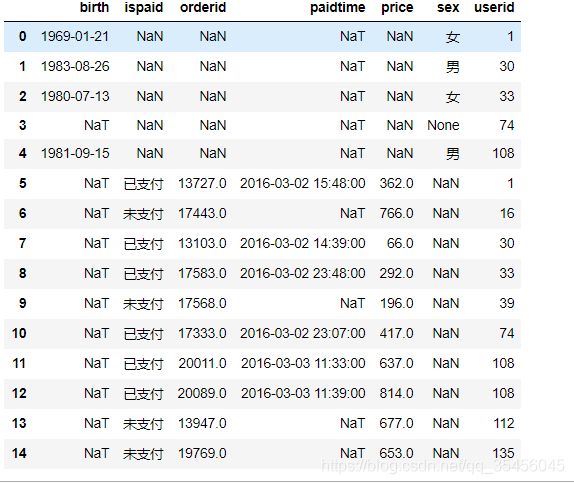
data = pd.merge(user_info, order_info, how='outer')
data
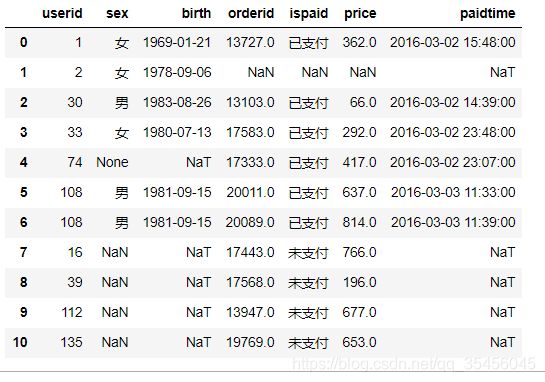
将id设置为行号
set_index()
data.set_index(keys='userid',inplace=True)
重新设置行索引
data.reset_index(inplace=True)
指定关联列
left_on=None
right_on=None
cols = user_info.columns.tolist()
cols[0] = 'uid'
user_info.columns = cols
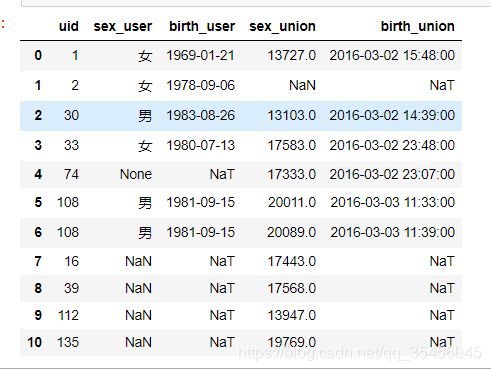
pd.merge(user_info,order_info,left_on='uid',right_on='userid',how='outer')
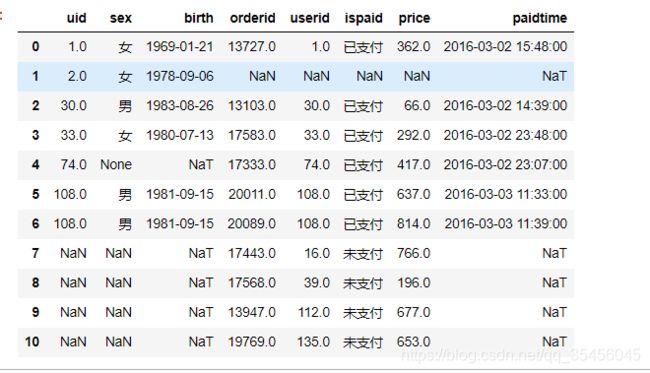
- 使用left_on和right_on指定左右两边的列作为key,当左右两边的key都不想等时使用
关联列是行索引
user_info.set_index('uid',inplace=True)
order_info.set_index('userid',inplace=True)
pd.merge(user_info,order_info,left_index=True,right_index=True,how='outer')
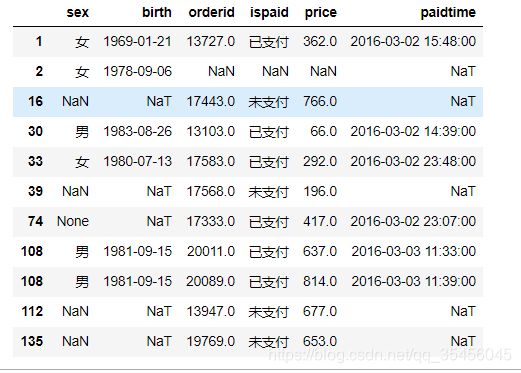
5) 内合并与外合并
- 内合并:只保留两者都有的key(默认模式)
- 外合并 how=‘outer’:补NaN
- 左合并、右合并:how=‘left’,how=‘right’,
6) 列冲突的解决
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名
可以使用suffixes=自己指定后缀
#两张表的字段有大部分是相同的
#select a.userid as auid , b.userid as buid from user_info a join order_info b using(userid);
cols = union_right.columns.tolist()
cols[0] = 'uid'
union_right.columns = cols
union_right.columns,user_info.columns
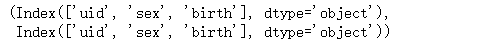
pd.merge(user_info,union_right,left_on='uid',right_on='uid',suffixes=('_user', '_union'),how='outer')