【大数据分析与挖掘技术】概述
目录
一、数据挖掘简介
(一)数据挖掘对象
(二)数据挖掘流程
(三)数据挖掘的分析方法
(四)经典算法
二、Mahout
(一)Mahout简介
(二)主要特性
(三)Mahout安装与配置
一、数据挖掘简介
需要是发明之母。近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。获取的信息和知识可以广泛用于各种应用,包括商务管理,生产控制,市场分析,工程设计和科学探索等。数据挖掘是人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术等,高度自动化地分析企业的数据,作出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,作出正确的决策。

数据挖掘也称为知识发现,是目前数据科学领域的热点研究课题。数据挖掘,就是从海量数据中发现隐含的、不平凡的、具有价值的规律或模式。在人工智能、机器学习、模式识别、数据库管理和图像处理等专业领域,数据挖掘技术都是必不可少的技术支持。
基于对数据的分析,可以对数据之间的关联进行抽取和调整,构建合理的模型来提供决策支持。相比其他领域,数据挖掘在商业上的应用更易于理解,通过企业大量的数据,获取其内含的规律,从而将其模型化并应用于实际场景,使企业获得更高的利润和关注度。
(一)数据挖掘对象
数据的类型可以是结构化的、半结构化的,甚至是异构型的。发现知识的方法可以是数学的、非数学的,也可以是归纳的。最终被发现了的知识可以用于信息管理、查询优化、决策支持及数据自身的维护等。
数据挖掘的对象可以是任何类型的数据源。可以是关系数据库,此类包含结构化数据的数据源;也可以是数据仓库、文本、多媒体数据、空间数据、时序数据、Web数据,此类包含半结构化数据甚至异构性数据的数据源。
发现知识的方法可以是数字的、非数字的,也可以是归纳的。最终被发现的知识可以用于信息管理、查询优化、决策支持及数据自身的维护等。
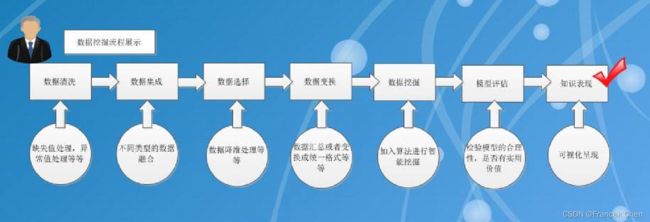
(二)数据挖掘流程
在实施数据挖掘之前,先制定采取什么样的步骤,每一步都做什么,达到什么样的目标是必要的,有了好的计划才能保证数据挖掘有条不紊地实施并取得成功。很多软件供应商和数据挖掘顾问公司投提供了一些数据挖掘过程模型,来指导他们的用户一步步地进行数据挖掘工作。比如,SPSS公司的5A和SAS公司的SEMMA。
数据挖掘过程模型步骤主要包括定义问题、建立数据挖掘库、分析数据、准备数据、建立模型、评价模型和实施。下面让我们来具体看一下每个步骤的具体内容:
1、定义问题
在开始知识发现之前最先的也是最重要的要求就是了解数据和业务问题。必须要对目标有一个清晰明确的定义,即决定到底想干什么。比如,想提高电子信箱的利用率时,想做的可能是“提高用户使用率”,也可能是“提高一次用户使用的价值”,要解决这两个问题而建立的模型几乎是完全不同的,必须做出决定。
2、建立数据挖掘库
建立数据挖掘库包括以下几个步骤:数据收集,数据描述,选择,数据质量评估和数据清理,合并与整合,构建元数据,加载数据挖掘库,维护数据挖掘库。
3、分析数据
分析的目的是找到对预测输出影响最大的数据字段,和决定是否需要定义导出字段。如果数据集包含成百上千的字段,那么浏览分析这些数据将是一件非常耗时和累人的事情,这时需要选择一个具有好的界面和功能强大的工具软件来协助你完成这些事情。
4、准备数据
这是建立模型之前的最后一步数据准备工作。可以把此步骤分为四个部分:选择变量,选择记录,创建新变量,转换变量。
5、建立模型
建立模型是一个反复的过程。需要仔细考察不同的模型以判断哪个模型对面对的商业问题最有用。先用一部分数据建立模型,然后再用剩下的数据来测试和验证这个得到的模型。有时还有第三个数据集,称为验证集,因为测试集可能受模型的特性的影响,这时需要一个独立的数据集来验证模型的准确性。训练和测试数据挖掘模型需要把数据至少分成两个部分,一个用于模型训练,另一个用于模型测试。
6、评价模型
模型建立好之后,必须评价得到的结果、解释模型的价值。从测试集中得到的准确率只对用于建立模型的数据有意义。在实际应用中,需要进一步了解错误的类型和由此带来的相关费用的多少。经验证明,有效的模型并不一定是正确的模型。造成这一点的直接原因就是模型建立中隐含的各种假定,因此,直接在现实世界中测试模型很重要。先在小范围内应用,取得测试数据,觉得满意之后再向大范围推广。
7、实施
模型建立并经验证之后,可以有两种主要的使用方法。第一种是提供给分析人员做参考;另一种是把此模型应用到不同的数据集上。
(三)数据挖掘的分析方法
1、分类分析:分类是指按照某种分类模型将具有相同特征的数据对象划分为同一类。
2、聚类分析:聚类分析是一种创建数据对象集合的方法,这种数据集合也称为簇(Cluster),聚类分析力求使得同簇成员尽可能相似,异簇成员尽可能相异。
3、关联分析:关联分析是指找出多个事物之间具有的规律性(关联),这一概念最早是由Rakesh Apwal等人提出的。
4、时序模式分析:时序模式分析反映的是属性在时间上的特征,属性在时间维度上如何变化,时序模式分析试图在这些历史数据中找到重复概率较高的模式,从而可以利用已知的数据预测未来的值,主要应用在产品生命周期预测,寻求客户等方面。
5、偏差分析:偏差分析是指关注数据库中的异常点,因为对管理者来说,这些异常点往往是更需要给予关注的。
(四)经典算法
目前,数据挖掘的算法主要包括神经网络法、决策树法、遗传算法、粗糙集法、模糊集法、关联规则法等。
1、神经网络法
神经网络法是模拟生物神经系统的结构和功能,是一种通过训练来学习的非线性预测模型,它将每一个连接看作一个处理单元,试图模拟人脑神经元的功能,可完成分类、聚类、特征挖掘等多种数据挖掘任务。神经网络的学习方法主要表现在权值的修改上。其优点是具有抗干扰、非线性学习、联想记忆功能,对复杂情况能得到精确的预测结果;缺点首先是不适合处理高维变量,不能观察中间的学习过程,具有“黑箱”性,输出结果也难以解释;其次是需较长的学习时间。神经网络法主要应用于数据挖掘的聚类技术中。
2、决策树法
决策树是根据对目标变量产生效用的不同而建构分类的规则,通过一系列的规则对数据进行分类的过程,其表现形式是类似于树形结构的流程图。最典型的算法是J.R.Quinlan于1986年提出的ID3算法,之后在ID3算法的基础上又提出了极其流行的C4.5算法。采用决策树法的优点是决策制定的过程是可见的,不需要长时间构造过程、描述简单,易于理解,分类速度快;缺点是很难基于多个变量组合发现规则。决策树法擅长处理非数值型数据,而且特别适合大规模的数据处理。决策树提供了一种展示类似在什么条件下会得到什么值这类规则的方法。比如,在贷款申请中,要对申请的风险大小做出判断。
3、遗传算法
遗传算法模拟了自然选择和遗传中发生的繁殖、交配和基因突变现象,是一种采用遗传结合、遗传交叉变异及自然选择等操作来生成实现规则的、基于进化理论的机器学习方法。它的基本观点是“适者生存”原理,具有隐含并行性、易于和其他模型结合等性质。主要的优点是可以处理许多数据类型,同时可以并行处理各种数据;缺点是需要的参数太多,编码困难,一般计算量比较大。遗传算法常用于优化神经元网络,能够解决其他技术难以解决的问题。
4、粗糙集法
粗糙集法也称粗糙集理论,是由波兰数学家Z Pawlak在20世纪80年代初提出的,是一种新的处理含糊、不精确、不完备问题的数学工具,可以处理数据约简、数据相关性发现、数据意义的评估等问题。其优点是算法简单,在其处理过程中可以不需要关于数据的先验知识,可以自动找出问题的内在规律;缺点是难以直接处理连续的属性,须先进行属性的离散化。因此,连续属性的离散化问题是制约粗糙集理论实用化的难点。粗糙集理论主要应用于近似推理、数字逻辑分析和化简、建立预测模型等问题。
5、模糊集法
模糊集法是利用模糊集合理论对问题进行模糊评判、模糊决策、模糊模式识别和模糊聚类分析。模糊集合理论是用隶属度来描述模糊事物的属性。系统的复杂性越高,模糊性就越强。
6、关联规则法
关联规则反映了事物之间的相互依赖性或关联性。其最著名的算法是R.Agrawal等人提出的Apriori算法。其算法的思想是:首先找出频繁性至少和预定意义的最小支持度一样的所有频集,然后由频集产生强关联规则。最小支持度和最小可信度是为了发现有意义的关联规则给定的2个阈值。在这个意义上,数据挖掘的目的就是从源数据库中挖掘出满足最小支持度和最小可信度的关联规则。
二、Mahout
(一)Mahout简介
Mahout是Apache公司的开源机器学习软件库,其实现了机器学习领域的诸多经典算法,例如,推荐算法、聚类算法和分类算法。Mahout可以让开发人员更方便快捷地创建智能应用程序,另外,Mahout通过应用Hadoop库可以有效利用分布式系统进行大数据分析,大大减少了大数据背景下数据分析的难度。

目前Mahout着力与三个领域——推荐(协同过滤)、聚类、分类算法的实现上,尽管理论上它可以实现机器学习中的所有技术!
(二)主要特性
虽然在开源领域中相对较为年轻,但 Mahout 已经提供了大量功能,特别是在集群和 CF 方面。
Mahout 的主要特性包括:
(1)Taste CF。Taste 是 Sean Owen 在 SourceForge 上发起的一个针对 CF 的开源项目,并在 2008 年被赠予 Mahout。
(2)一些支持 Map-Reduce 的集群实现包括 k-Means、模糊 k-Means、Canopy、Dirichlet 和 Mean-Shift。
(3)Distributed Naive Bayes 和 Complementary Naive Bayes 分类实现。
(4)针对进化编程的分布式适用性功能。
(5)Matrix 和矢量库。
(三)Mahout安装与配置
Mahout 上所有的机器学习算法是基于Java实现的,Mahout并没有提供用户接口与预装服务器或安装程序,这使得开发者拥有更加灵活自由的配置框架。为了让使用本书的读者能够方便地运行后文的例程,需要进行一些必要的系统搭建和安装工作。
(1)安装JDK+IDEA集成开发环境;
(2)安装配置maven;
(3)安装配置Mahout;
(4)安装配置Hadoop伪分布式环境。
下面我们将对安装过程进行简要的介绍。
第一步,在Linux环境下进行Mahout程序编写首先要要进行Java环境的搭建,在这里使用Oracle 版本的JDK1.8开发工具,基于Java8的新特性可以使Java代码更加简洁和高效。JDK在不断地更新,到目前为止,最新版本是Java SE9(JDK1.9.0)。以IntelliJ IDEA为例介绍Mahout 开发环境的配置,当然也可以使用Eclipse或Netbeans等进行操作,配置方式也略有差异。 IntelliJ IDEA在智能代码助手、代码自动提示、重构、J2EE支持、Ant、 JUnit、 Cvs整合、代码审查、创新的GUI设计等方面的性能十分优异。它是JetBrains公司的产品,下面介绍Linux环境下JDK的配置以及可视化Java开发环境配置。
首先,查看和卸载Linux自带的OpenJDK,打开控制台窗口,使用命令“java-version”可以查看当前系统上JDK版本,如果显示下面的结果或类似结果:
openjdk version"1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0131-b12)
OpenJDK 64-Bit Server VM(build 25.131-b12, mixed mode)出现以上提示,则表明系统已经安装了OpenJDK,需要先卸载它然后再安装SUN公司的JDK,使用如下命令可以删除OpenJDK:
yum -y remove java java-1.8.0-openjdk-headless.x86_64若再次查询Java版本显示如下:
bash:java:command not found.…表明系统自带的OpenJDK已经卸载,下面开始安装Sun的JDK,首先需到Oracle官网下载适合系统版本的JDK,通过下面的命令安装Sun JDK(默认安装在/usr/java目录下):
rpm -ivh jdk-8u77-linux-x64.rpm然后,在/etc/profile文件末尾添加 Java环境变量:
vim /etc/profile
export JAVA_HOME=/usr/java/1.8.0_151
export CLASSPATH=.:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=.:$PATH:$JAVA_HOME/bin 执行下面命令使修改生效:
source /etc/profile 然后通过 java-version 命令查看,若显示如下结果:
java version "1.8.0_151"
Java (TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot (TM) 64-Bit Server VM (build 25.151-b12, mixed mode) 表明JDK 已经配置完毕,然后安装可视化编程工具就可以很轻松的在Linux 上进行Java编程了。在这里我们使用IDEA集成开发环境,它可以很方便地进行组件安装,而且集成maven依赖,可以很快从现有的maven模型中创建一个新的项目。IDEA的安装过程非常简单,到 jetbrains 网站下载对应版本的文件,然后将其解压。再进入到解压后文件夹的bin目录下执行命令:
./idea.sh 执行命令后会自动安装可视化界面,选择需要的组件即可。
完成前两步后,还需要配置一些环境,以便运行Mahout 代码。首先,在本地安装一个伪分布式Hadoop,并下载最新的Mahout。最新版的Mahout可到Apache的官网上进行下载,下载后解压配置环境变量即可。
开发Mahout程序步骤如下:
(1)使用 IDEA 新建 maven 标准 Java 程序;
(2)进入File→Project Structure→Project Settings→Libraries,单击加号→Java;
(3)选中自己安装的 Mahout 文件夹,全部导入即可;
(4)导入后,就可以在 Java 代码中使用 Mahout 类库中的类了。
有关Mahout的机器学习的三大领域将在后面的博客中介绍……