Python爬虫初级(十四)—— Scrapy爬虫基础
Scrapy库不是一个简单的函数,而是一个爬虫框架。爬虫框架就是实现爬虫功能的一个软件结构和功能组件集合爬虫框架就是一个半成品,能够帮助用户实现专业网络爬虫。
Scrapy爬虫框架结构
“5+2”结构:
- Engine模块
- Spider模块
- Downloader模块
- ItemPipelines模块
- Scheduler模块
另外在Engine和Spider模块之间,以及Engine和Downloader模块之间包含了两个MiddleWare模块这个结构就称为Scrapy爬虫框架。在Scrapy框架中,数据包括用户提交的网络爬虫请求,以及从网络上提取地相关内容,在这些结构之间进行流动,形成数据流。
Scrapy框架主要包含三条主要的数据流路径:
-
第一条从Spiders经过Engine到达Scheduler,Engine从Spiders处获得用户的请求(Requests),可以简单地认为是一个URL,请求到达Engine后,Engine将其分配给Scheduler模块,而Scheduler模块负责对爬取请求进行调度。
-
Scrapy的第二条数据流路径是从Scheduler模块通过Engine模块到达Downloader模块,并且最终返回Spider模块。首先Engine模块从Scheduler模块获取下一个要爬取的网络请求,这一个网络请求是真实的要到网络上进行爬取的请求,Engine获得这个请求后通过中间键发送给Downloader模块,Downloader模块和获取请求之后真实地连接互联网并且爬取相关网页,爬取到网页后Downloader模块形成响应(Response),将所有内容封装为Response后打包通过Engine中间键发送给Spiders。在这条路径中一个真实地爬取URL的请求经过Scheduler,Downloader最终返回了相关内容返回Spiders。
-
第三条数据流路径是从 Spiders模块经过Engine模块到达ItemPipelines模块以及Scheduler模块。首先Spiders处理从Downloader获得的响应(从网络中爬取的相关内容),得到两个数据类型,一个数据类型叫爬取项(Scrapy Item),另一个数据类型是新的爬取请求。也就是我们从网络上获得一个网页之后,如果网页中有我们感兴趣的链接,我们可以在Spiders中增加相关的功能,对新的链接发起再次的爬取。Spiders生成了这两个数据类型之后,将它们发送给Engine模块,Engine随后将Item发送给ItemPipelines,将Requests发送给Requests进行调度,从而为后期的数据处理以及再获取网络爬虫请求提供了相应的数据来源。
在这条路径中,Engine控制着各个模块的数据流,并且它不断地从Scheduler获取真正要爬取的请求并发送给Downloader。这个框架的入口是Spiders,出口是ItemPipelines。在这个“5+2”结构中,Engine,Scheduler和Downloader都已有实现,用户不需要去编写他们,他们会按照既定的功能 完成相关的任务。用户需要编写的是Spiders模块和Item Pipelines模块,其中Spiders模块向整个Scrapy模块提供访问URL链接,同时解析从网络上获得的页面内容,ItemPipeline模块负责对提取的信息进行后处理。由于在这个框架下,用户只需要编写部分代码,因此这个过程也被称为配置,用户只需要在这个框架下进行简单的配置即可完成爬取需求。
Downloader Middleware目的是实施Engine、Scheduler、Downloader之间进行用户可配置的控制,功能是修改、丢弃、新增请求或响应。Spider Middleware目的是对请求和爬取项进行再处理,功能是修改、丢弃、新增请求或爬取项。
Requests库和Scrapy爬虫的比较
相同点:
- 两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
- 两者可用性都好,文档丰富,入门简单
- 两者都没有处理js、提交表单、用对验证码功能(可扩展)
不同点:
| requests | Scrapy |
|---|---|
| 页面级爬虫 | 网站级爬虫 |
| 功能库 | 框架 |
| 并发性考虑不足,性能较差 | 并发性好,性能较高 |
| 重点在于页面下载 | 重点在于爬虫结构 |
| 定制灵活 | 一般定制灵活,深度定制困难 |
| 上手简单 | 入门稍难 |
具体选择:
- 非常小的请求:Requests库
- 不太小的请求:Scrapy框架
- 定制成都很高的请求,自搭框架:Requests库
Scarpy爬虫的常用命令
- Scrapy命令行的启用——直接在命令行输入:scrapy -h
- 命令格式:scarpy
[options] [args],Scrapy的命令在command体现
常用命令如下:
| 命令 | 说明 | 格式 |
|---|---|---|
| startproject | 创建一个工程 | scrapy startproject |
| genspider | 创建一个爬虫 | scrapy genspider [options] |
| settings | 获得爬虫配置信息 | scrapy settings [options] |
| crawl | 运行一个爬虫 | scrapy crawl |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动URL调试命令行 | scrapy shell [url] |
为什么Scrapy采用命令行创建和运行爬虫?
- 命令行(不是图形界面)更容易自动化,适合脚本控制(只有用户才会关注图形界面)
Scrapy爬虫第一个实例
首先我们有Scrapy爬虫的产生步骤:
- 建立一个Scrapy爬虫工程
- 在工程中产生一个Scrapy爬虫
- 配置产生的spider爬虫
- 运行爬虫,获取网页
建立一个Scrapy爬虫工程
演示HTML页面地址:http://python123.io/ws/demo.html
文件名称:demo.html
我们建立工程的所有的操作如下:
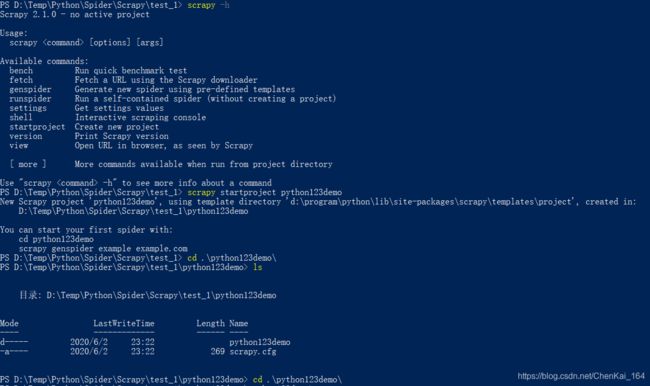
我们可以看到整个文件的架构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mecdepS2-1591115592493)(./Pic/Spider/Scrapy_Start.jpg)]
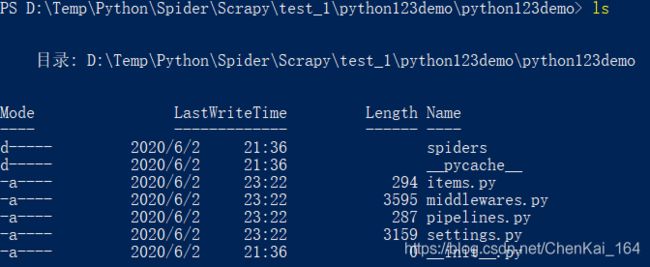
在生成的工程目录spider/下,含有Spiders代码模板目录(继承类),内部含有两个文件:
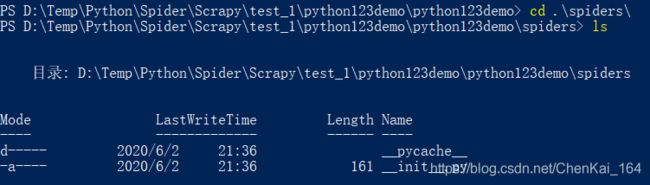
其中 _init_.py是初始文件,无需修改;而__pycache__是我们熟悉的缓存目录,也无需修改
在工程中产生一个Scrapy爬虫
我们在工作目录下先输入scrapy genspider demo python123.io命令,然后将会在python123demo文件夹下的spiders文件夹中产生一个新的文件:demo.py,具体操作如下:

这条命令的作用仅是生成demo.py,demo.py文件内容如下:
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['python123.io']
start_urls = ['http://python123.io/']
def parse(self, response):
pass
这个类函数DemoSpider必须是继承scrapy.Spider,name指的是这个爬虫的名字,allowed_domains是用户提交给命令行的域名,也就是爬虫在爬取网站时,只能爬取该域名下的链接,start_urls就是scrapy爬取框架爬取的初始页面。parse函数是解析页面的空的类的方法,用于处理响应,可以解析从网络中爬取内容,形成字典类型,同时从网页中发现新的要爬取的内容,生成url。
配置产生的spider爬虫
我们对parse的要求是将返回的html存成文件,下面直接看这部分代码:
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
# allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response):
# 从响应的url中提取名字作为本地文件名
fname = response.url.split('/')[-1]
# 将返回内容保存为文件
with open(fname, "wb") as f:
f.write(response.body)
self.log("Saved file %s." %name)
运行爬虫,获取网页
我们在命令行下执行crawl命令获取网页:
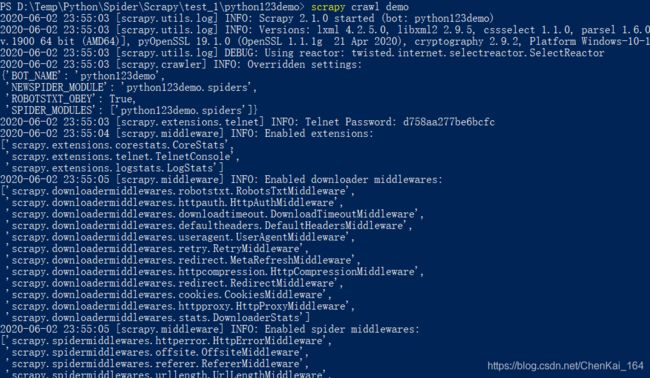
捕获的文件存在python123demo路径下的demo.html文件中
事实上,官方给出的更标准的写法是下面这个:
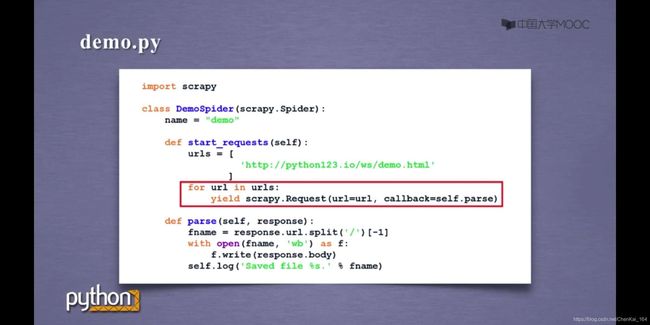
这里主要使用了yield,这个函数当返回的URL列表很大时,能够极大地节省存储空间,若有需要进一步了解yield的用法可自行看文档。
Scrapy爬虫的使用步骤
下面我们对爬虫使用步骤做个总结:
- 创建一个工程和Spider模板
- 编写Item Pipeline
- 编写Spider
- 优化策略配置
Scrapy爬虫的数据类型有:
- Requests类
- Response类
- Item类
Request对象表示一个HTTP请求,由Spider生成,由Downloader执行。具体来说Request类包含六个属性方法:
| 属性或方法 | 说明 |
|---|---|
| .url | Request对应的请求URL地址 |
| .method | 对应的请求方法,‘GET’'POST’等 |
| .headers | 字典类型风格请求头 |
| .body | 请求内容主体,字符串类型 |
| .meta | 用户添加的扩展信息,在Scrapy内部模块间传递信息使用 |
| .copy() | 复制该请求 |
Response对象表示一个HTTP响应,由Downloader生成,由Spider处理。包含了七个主要的属性和方法:
| 属性或方法 | 说明 |
|---|---|
| .url | Response对应的响应URL地址 |
| .status | HTTP状态码,默认是200 |
| .headers | Response对应的头部信息 |
| .body | Response对应的内容信息,字符串类型 |
| .flags | 一组标记 |
| .request | 产生Response类型对应的Request对象 |
| .copy() | 复制该响应 |
Item对象表示一个从HTML页面中提取的信息内容,由Spider生成,由Item Pipeline处理。Item类似字典类型,可以按照字典类型操作
Scrapy爬虫提取信息的方法
Scrapy支持多种HTML信息提取的方法:Beautiful Soup,lxml,re,XPATH Selector,CSS Selector等
本文图片上传有些问题,若想获得更好的观看体验以及了解更完整的爬虫框架,欢迎 访问我的个人博客主页 chenk.tech ~