python实现搜索引擎——搜索引擎架构(一)
python实现搜索引擎——搜索引擎架构(一)
一、实验介绍
1.1 实验知识点
- 介绍本课程实现的搜索引擎的架构设计
- 介绍搜索引擎所必要的组件
- 对课程项目进行开发环境的部署和配置
- 创建项目及必要的代码目录
1.2 实验环境
- Python3.6
- Xfce 终端
二、开发准备
2.1 实现的搜索引擎的架构设计
如何构建一个搜索引擎,从专业名称来看,叫做信息检索,在《信息检索导论》一书中,这个概念定义如下:
信息检索是从大规模非结构化数据(通常是文本)的集合(通常保存在计算机上)中找出满足用户信息需求的资料(通常是文档)的过程。
由于我们的目标文档全是技术博客,所以我们构建的搜索引擎是针对技术博客领域的垂直搜索引擎:
根据上面图示可以很清晰地看出一个搜索系统的必要模块组件,下面我将以一个信息检索小例子来带大家根据上图走一遍流程。
数据文档暂且不必从网络上爬取,让我们根据以下的三篇文档来了解下文档检索的一些概念:
- 文档1:举杯邀明月,对影成三人。
- 文档2:君不见黄河之水天上来,奔流到海不复回。
- 文档3:明月几时有,把酒问青天。不知天上宫阙,今夕是何年。
这三句诗大家自然是耳熟能详,假设我们需要从这些文档中搜索出明月和天上,因为这仅仅是三条简单的诗词文档并且我们非常熟悉,所以可以很迅速的得出文档三包含这两个关键词,从第一行看到最后一行,从第一句看到最后一句,我们就能得出答案,这种方法被称之为线性扫描法。
但是这种线性扫描法局限性太多,让我们看看一种更好的方案,词项-文档(term-doc)的关联矩阵:
| 词汇 | 文档1 | 文档2 | 文档3 |
|---|---|---|---|
| 明月 | 1 | 0 | 1 |
| 天上 | 0 | 1 | 1 |
词项—文档关联矩阵,其中每行表示一个词,每列表示一个文档,当词 t 在文档 d 中存在时,矩阵元素 (t,d) 的值为1,否则为0,这样就得到一个布尔值构成的词项-文档关联矩阵,在该模型下,每篇文档就可以被看成是一系列词的集合。
有了词项-文档关联矩阵,就可以很轻松地使用布尔检索模型进行查询。
有了词项-文档关联矩阵,就可以很轻松地使用布尔检索模型进行查询。
观察上面的词项-文档关联矩阵,可以看到:
- 明月词汇:(1,0,1)
- 天上词汇:(0,1,1)
然后对这两个查询词进行基于位的与操作,明月 AND 天上 => (1,0,1) AND (0,1,1) = (0,0,1),显而易见,文档三就是我们要的结果。
当文档数量增大,词项-文档(term-doc)的关联矩阵高度稀疏,矩阵中的大部分元素为0,此时只记录原始矩阵中1的位置的表示方法比词项-文档(term-doc)矩阵效果更好。
沿着这个方向思考解决方案,引出的就是信息检索中的一个核心概念——倒排索引(inverted index)。
2.2 搜索引擎必要的组件
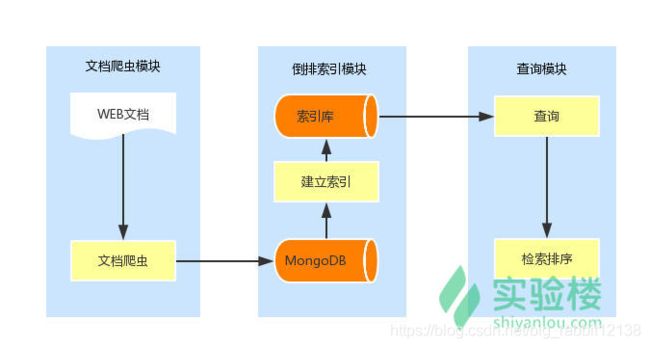
2.2.1 文档爬虫
互联网上文档数据数不胜数并且种类繁多,每日还以非常快的速度在增加,我们需要一个手段来实现对目标文档数据(技术类型文档)进行收集。
基于爬虫的自动化收集是非常好的一个文档收集方式,实验二详细介绍了什么是爬虫,怎么编写爬虫以及如何构造一个爬虫系统。
文档爬虫的目的在于为搜索引擎提供检索对象文档,文档数据越丰富,用户查询结果就提供更多的可能,帮助用户找到理想的搜索结果。
2.2 建立索引
传统的线性扫描在数据庞大的情况下是不适用的,一种非线性的扫描方式就是给文档建立索引,这样做有以下好处:
在大量数据文档下也能进行查找
更加灵活的匹配方式
可以对结果排序
具体实现将在实验三进行详解。
2.3 网页排名
在文档集规模很大的情况下,满足布尔查询结果的文档可能有很多,大量满足搜索条件的文档可能并不都是搜索者想要的,因此需要一个对文档进行评分以及排序的机制,为此,我们的搜索引擎需要对每个匹配的文档进行分数计算,从而根据网页排名进行排序展示,给与用户更加友好的结果展示。
具体实现将在实验六进行详解。
三、实验步骤
3.1 对课程项目进行介绍
本课程的目的是和大家一起构建一个基于技术博客的垂直搜索引擎,
- 使用Python3.6进行开发,
- 使用vim对代码进行编写,
- 数据库使用的是MongoDB。
这门课程的整体架构如下图(注1):

3.2 创建项目必要的代码目录
基于技术博客的垂直搜索引擎的项目架构我们已经了解完毕,接下来就是进行项目编码,首先我们得取个名字,我将其命名为:monkey。
本次实验的项目目录在 /home/shiyanlou/Code/monkey 目录下,本项目是使用pipenv进行包管理。
初始化环境:
cd ~/Code/monkey
#升级pipenv
pip install pipenv -U
#执行后会为monkey创建特定的环境,项目根目录会生成Pipfile和Pipfile.lock文件 (实验环境中默认已经安装)
pipenv install
#安装pip==18.0 (实验环境中默认已经安装)
pipenv run pip install pip==18.0
#创建代码目录
mkdir monkey
#创建说明文档目录
mkdir docs
#创建测试文件夹
mkdir tests
#创建README.md
#Linux touch命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
touch README.md
目前,最外一层项目目录结构如下:
.
├── Pipfile
├── Pipfile.lock
├── README.md
├── docs
├── monkey
└── tests
此时,项目的基本环境已经搭建完毕,利用 pipenv 可以很方便地对包以及项目环境进行管理:
# 进入项目 monkey 的虚拟环境,在 monkey 虚拟环境中默认使用的就是 Python3.6
pipenv shell
看到以下类似的输出即可理解为项目环境搭建成功:

四、实验总结
本次实验我们先介绍了搜索引擎的架构设计以及其中一些组件的作用,还画出了项目的整体结构以及完成了项目的准备工作,其中用到的包管理工具 pipenv,如果诸位不熟悉的话可以先谷歌了解一下。
接下来我们将进入到编码阶段,只要你有Python的语法基础,做后面的实验应该没有太大问题,各位请加油。
参考链接
文中一些参考文档和资源链接:
- pipenv.
- 注 1:图设计参考processon的模板
- pipevn快速入门
- ruia官方文档(第二节要用)