Python爬虫初级(十三)—— 水木社区论坛爬取实战
上一篇文章:Python爬虫初级(十二)—— 新闻消息抓取实战
实战阶段一:分析首页大板块 URL
我们首先打开待爬取页面 —— 水木社区的首页:http://www.newsmth.net/nForum/#!mainpage,进入后页面如下:
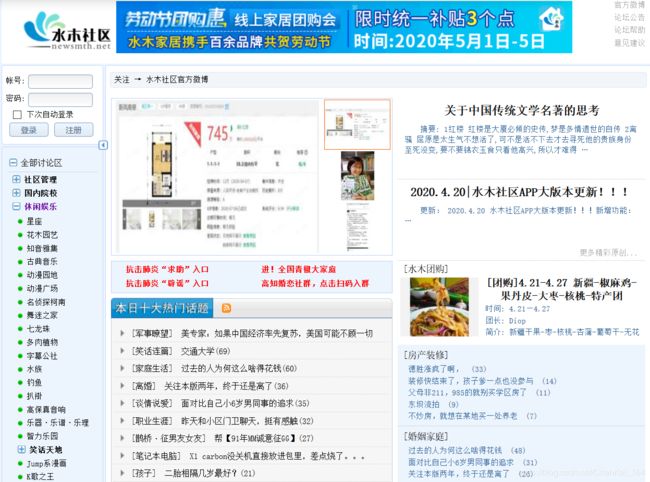 我们看到左边有很多讨论区板块,我们点进去试试:
我们看到左边有很多讨论区板块,我们点进去试试:
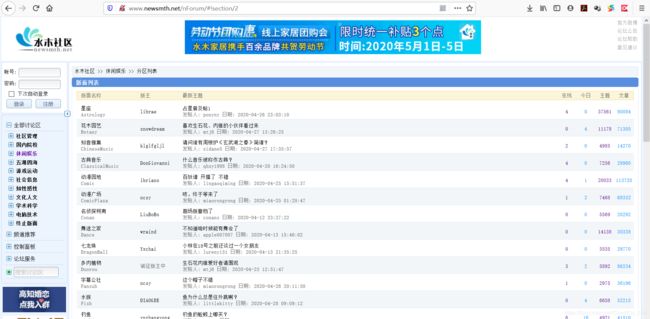
我们现在就已经点进去了休闲娱乐讨论区,在这个讨论区中我们可以看到最上面的链接:http://www.newsmth.net/nForum/#!section/2,那这个链接就很有灵魂了,我们很容易就能猜到只要我们修改不同的 section,我们就可以进入不同的讨论区,我们进入讨论区后可以看到有不同的板块:

实战阶段二:获取子板块 URL
我们希望获取到这些板块的链接和标题,但点进去之后发现这些板块并不像它的上一级打开一样有 section 给我们选择,它是一个个的板块名称的英文,有人或许会想我们可以直接把这些对应的名称输入字典翻译过来再输回来不就可以了吗,但事实上每一个英文单词可能有不同的表达,而且就算我们能够确定他们的表达,我们还得建一个字典爬虫,这多麻烦啊。
我们先试着查看一下这篇网页的 notwork,打开 network 再点击刷新,我们筛选 XML 类型的数据:
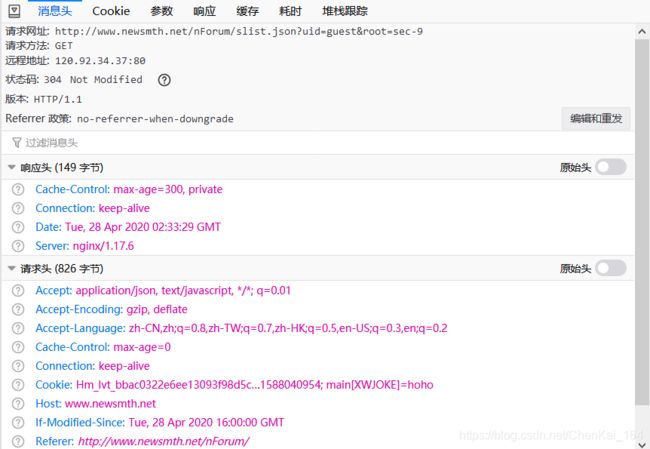
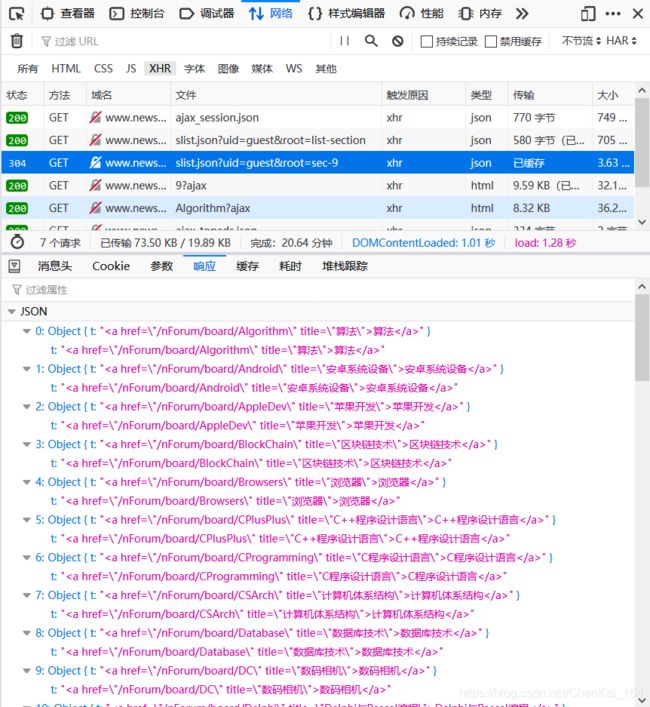 事实上 XML 的数据并不多,我们只需要都看一看他们的响应值就可以找到这样一个汇总了所有条目信息的数据,我们点开这条 XML 的消息头:
事实上 XML 的数据并不多,我们只需要都看一看他们的响应值就可以找到这样一个汇总了所有条目信息的数据,我们点开这条 XML 的消息头:
将对应的请求网址输入 POSTMAN 工具,点击 send 后得到对应的消息头:
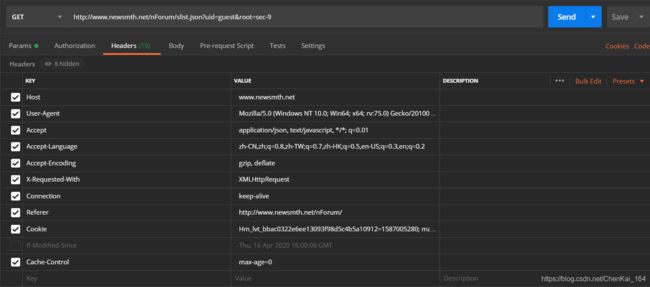
点击最右侧的 code,此时它就会把我们所需的 headers 返回给我们:
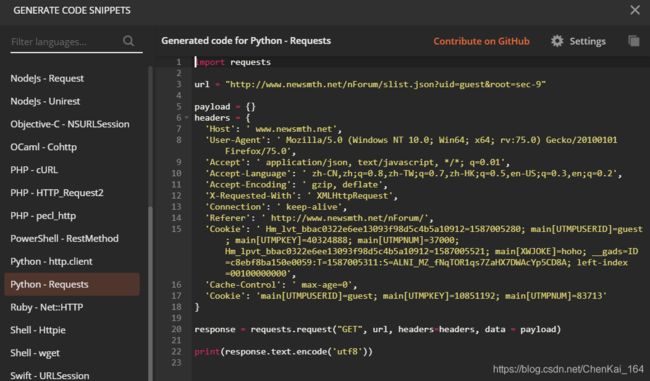
我们直接复制 headers 部分,然后就按套路就能得到响应了(如果连套路都不会的话大家赶紧复习一下前面的内容:requests 实战,最好把前前后后的知识都补一遍!
下面是这个部分的代码:
import requests
import re
from bs4 import BeautifulSoup
from lxml import etree
url = "http://www.newsmth.net/nForum/slist.json?uid=guest&root=sec-9"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0',
'Host': 'www.newsmth.net',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate',
'X-Requested-With': 'XMLHttpRequest',
'Connection': 'keep-alive',
'Referer': 'http://www.newsmth.net/nForum/',
'Cookie': 'Hm_lvt_bbac0322e6ee13093f98d5c4b5a10912=1587005280; main[UTMPUSERID]=guest; main[UTMPKEY]=40324888; main[UTMPNUM]=37000; Hm_lpvt_bbac0322e6ee13093f98d5c4b5a10912=1587005521; main[XWJOKE]=hoho; __gads=ID=c8ebf8ba150e0059:T=1587005311:S=ALNI_MZ_fNqTOR1qs7ZaHX7DWAcYp5CD8A; left-index=00100000000',
'Cache-Control': 'max-age=0',
'Cookie': 'main[UTMPUSERID]=guest; main[UTMPKEY]=10851192; main[UTMPNUM]=83713'
}
def get_text(url):
try:
res = requests.get(url, headers=headers)
res.raise_for_status
res.encoding = res.apparent_encoding
text = res.text
return text
except:
return ""
text = get_text(url)
text = text.replace("[", "")
text = text.replace("]", "")
text_split = text.split(",")
href_list = []
title_list = []
for i in range(len(text_split)):
str_i = text_split[i]
pat1 = re.compile(r'a href=\\"(.*?)" title=')
pat2 = re.compile(r'title=\\"(.*?)\\">')
href_ = re.findall(pat1, str_i)
title_ = re.findall(pat2, str_i)
if (len(href_)) > 0 & (len(title_) > 0):
href_list.append(href_[0])
title_list.append(title_[0])
print(href_list,"\n",title_list)
href_list = ["http://www.newsmth.net" + href.replace("\\", "") for href in href_list]
href_list
大家最好都手敲一遍,事实上这段代码大家完全不用看我的,自己都可以敲出来,这是最终得到的结果,URL 和标题信息都有了:
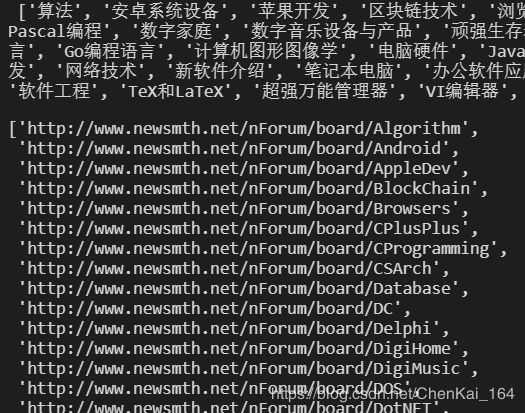
我们上面得到的标题,可以作为我们建立新文件夹的依据,我们得到的 URL,我们可以进一步分析得到文章的条件,然后按照套路抓取到所有的文章。接下来我们就看看怎么通过这些 URL 得到对应的文章:
实战阶段三:获取子版块下所有文章
我们任意点进去一个子版块,以 AppleDev 子版块为例,依然是点开 network 刷新,得到一些 ajax 信息, ajax 在我们前面的 Ajax 详解
已经有讲过了,我们仍然按照套路抓取链接得到内容,然后由正则表达式匹配文章链接,文章链接的形式我们可以任意点开一篇文章观察到,或者也可以直接通过返回的信息得到,下面是抓取的代码:
res_ = requests.get("http://www.newsmth.net/nForum/board/AppleDev?ajax", headers=headers)
res_.encoding = res_.apparent_encoding
text = res_.text
pat3 = re.compile(r'(/nForum/article/AppleDev/\d+)')
href_text = re.findall(pat3, text)
total_href_text = ["http://www.newsmth.net"+ href for href in href_text]
print(total_href_text)
我们将得到的链接内容进行截图:
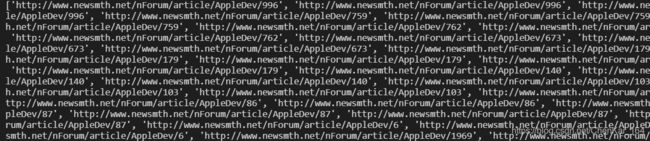
不出意料,我们点进去任何一个链接看到的文章都正是我们想要得到的内容!
实战阶段四:编写结构化代码
我们现在直接开始编写结构化的代码:
首先导入我们所需要的包:
import requests
import re
from bs4 import BeautifulSoup
from lxml import etree
from selenium import webdriver
有人可能会好奇,为什么还要导入 selenium 包,事实上在爬取文章内容的时候,我试图分析了一波网页源代码和 Network 的 response,似乎并没有好的方法获得文章内容,于是我果断放弃,选择了相对低效的 selenium,至于问为什么低效,是因为我的代码中每一次都需要打开 passage 的网页才能抓取,当然现在有不需要打开网页的 selenium 方法,别问,问就是懒。
下面我们写一个很常用很老套的函数,从 URL 获得文章的 Text:
def getText(url):
try:
res = requests.get(url)
res.raise_for_status
res.encoding = res.apparent_encoding
return res.text
except:
return ""
这几行代码如果大家看了前几期文章,现在倒着都能默出来了吧,如果没有的话赶紧去看看前面所有爬虫系列的文章噢~
然后我们定义一个函数,获取所有的 Section 的 URL:
def getSectionURL():
url_list = []
base_url = r"http://www.newsmth.net/nForum/#!section/"
for i in range(10):
url_list.append(base_url+str(i))
return url_list
下面这堆代码的用途是获得 Section 的名称,大家可以用这个名称在爬取完文章后建立文件夹保存文章:
def getSectionList():
sectionTitleURL = "http://www.newsmth.net/nForum/slist.json?uid=guest&root=list-section"
text = getText(sectionTitleURL)
textList = text.split(",")
textList = [i for i in textList if i.endswith('"')]
for i in range(len(textList)):
textList[i] = re.findall(r'\\">(.*?)', textList[i])
textList = [i[0] for i in textList if len(i)>0]
return textList
下面这段代码用于爬取大板块下面的所有子版块的链接和标题:
def getSubSectionList(section_num):
url = "http://www.newsmth.net/nForum/section/" + str(section_num) + "?ajax"
text = getText(url)
soup = BeautifulSoup(text, "html")
hrefList = soup.select("td a")
hrefList = [str(href) for href in hrefList]
hrefList = [href for href in hrefList if href.startswith(r')]
pat1 = re.compile(r'')
pat2 = re.compile(r'">(.*?)')
HrefList = []
TitleList = []
for i in range(len(hrefList)):
href = re.findall(pat1, hrefList[i])
href = "http://www.newsmth.net" + href[0]
title = re.findall(pat2, hrefList[i])
HrefList.append(href)
TitleList.append(title[0])
return HrefList, TitleList
下面这行代码用于从上面获得的 SubSectionURL 中获得所有文章的 URL 链接:
def getPassageURL(SubSectionURL):
TextURL = SubSectionURL + "?ajax"
text = getText(TextURL)
title = re.findall(r"nForum/board/(.*)\?ajax", TextURL)[0]
pat = re.compile(r'href="/nForum/article/' + re.escape(title) + r'/(\d{2,10})')
article_num = re.findall(pat, text)
href_list = [r"http://www.newsmth.net/nForum/#!article/" + title + "/" + href for href in article_num]
return href_list
下面这行代码用于从上面的文章 URL 中解析出文章内容,评论区内容被截掉了,大家可根据需要修改代码:
def getPassageFromURL(PassageURL_List):
text_List = []
i=0
for url in PassageURL_List:
driver = webdriver.Firefox()
driver.get(url)
page = driver.page_source
soup = BeautifulSoup(page)
content = soup.select("td[class~=a-content]")
passage = re.findall(r'(.*?) ', str(content[0]))
print(passage)
text_List.append(passage)
driver.close()
return text_List
大功告成!大家试着运行一下代码看看能不能跑通吧~