eclipse 搭建Scala开发环境、spark基本框架、spark工作原理以及DAG、Stage、宽窄依赖
目录
- 搭建spark开发环境
- Spark框架
- Spark工作原理
- DAG、Stage、宽窄依赖
1. 搭建spark开发环境
首先, 安装好 jdk1.8 的版本,以及安装 eclipse(OXYGNEN.2);
然后,下载和安装Scala IDE插件,具体步骤如下:
第一步,运行软件,点击右上角的IDE选择器,如图:
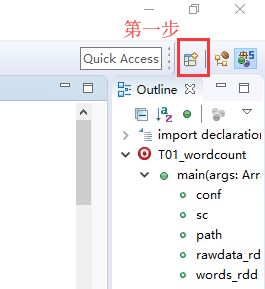
第二步,选择Scala IDE,如图:
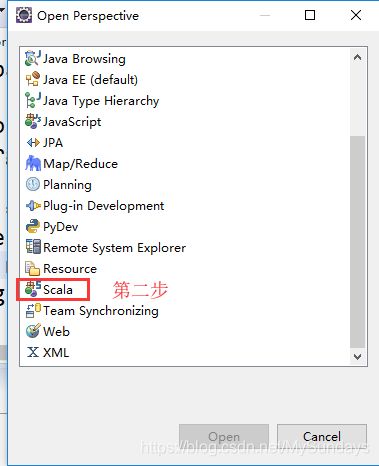
第三步,打开 Scala IDE,创建一个名称为 GXSF_01 的 Scala 工程
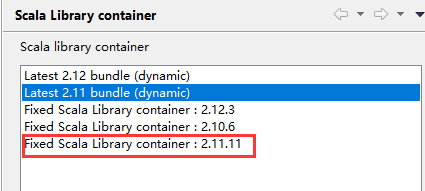
第四步,把Scala库容器改为2.11.11版本,具体操作为:选中【Scala Library container[2.12.11]】 ,鼠标右击,选中【properties】 , 把【Scala Library container :2.12.11]】改为【Scala Library container :2.11.11 】,如图:
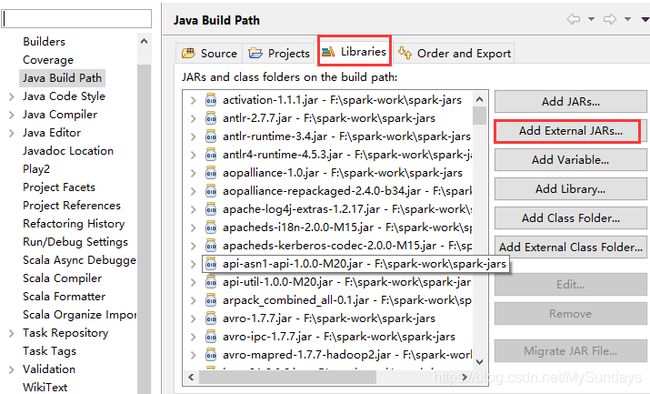
第五步,构建配置环境,鼠标单击Scala项目,右击【build path】 , , 添加 spark的jars包(放在spark-jars文件里)
第六步,在GXSF_01的Scala工程里新建一个名为T01_wordcount 的Scala Object 类,实现单词的统计。实例结果如下图:
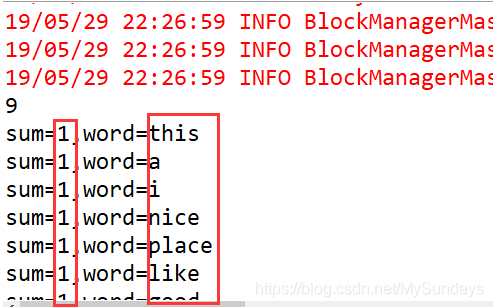
代码为:
def main(args: Array[String]): Unit = {
// 1.sc
var conf = new SparkConf()
.setMaster("local[*]").setAppName("")
var sc = new SparkContext(conf)
sc.setLogLevel("WARN")
// 2. sc.textFile
var path = "C:\\Users\\xiaoxiannv\\Desktop\\data.txt"
var rawdata_rdd = sc.textFile(path, 2)
var words_rdd = rawdata_rdd
.flatMap(_.split("\\W+"))
.map(x=>(x,1))
.reduceByKey(_+_).map(_.swap).sortByKey(false) // 下划线代表一个字符
println(words_rdd.count)
words_rdd.foreach{line => //(word,10)
println("sum="+line._1+",word="+line._2)
}
//print(rawdata_rdd.foreach(println))
//RDD.map word ->(w,1)
//RDD.reduce ->w-> sum 1
print("end .......")
}
2. Spark框架
Spark 的基本框架有:Spark Core( RDD - API - 集合 )、Spark SQL( jdbc / sql - 离线处理-历史 )、Spark Streaming( 及时处理 - 事务 )、Spark MLlib( 机器学习 )、Spark GraphX(图计算);
- Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
- Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
3. Spark工作原理
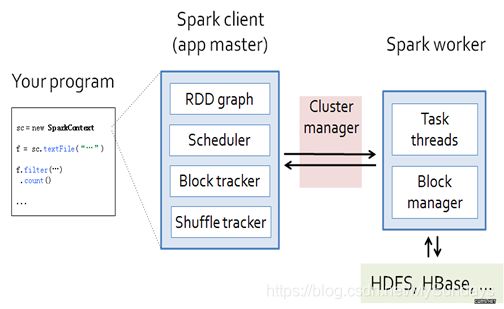
编写程序提交到Master上,
Master是由四大部分组成(RDD Graph,Scheduler,Block Tracker以及Shuffle Tracker)
启动RDD Graph就是DAG,它会提交给Task Scheduler任务调度器等待调度执行
具体执行时,Task Scheduler会把任务提交到Worker节点上
Block Tracker用于记录计算数据在Worker节点上的块信息
Shuffle Blocker用于记录RDD在计算过程中遇到Shuffle过程时会进行物化,Shuffle Tracker用于记录这些物化的RDD的存放信息
4. DAG、Stage、宽窄依赖
Job、stage和task是spark任务执行流程中的三个基本单位。其中job是最大的单位,Job是spark应用的action算子催生的;stage是由job拆分,在单个job内是根据shuffle算子来拆分stage的,单个stage内部可根据操作数据的分区数划分成多个task。
stage的划分
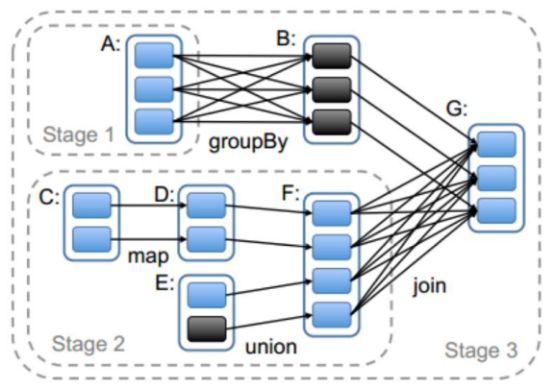
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。
注:stage是由一组并行的task组成
窄依赖
父RDD和子RDD partition之间的关系是一对一的。或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的。不会有shuffle的产生。父RDD的一个分区去到子RDD的一个分区。
宽依赖
父RDD与子RDD partition之间的关系是一对多。会有shuffle的产生。父RDD的一个分区的数据去到子RDD的不同分区里面。
其实区分宽窄依赖主要就是看父RDD的一个Partition的流向,要是流向一个的话就是窄依赖,流向多个的话就是宽依赖。看图理解:

Stage概念
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。?????stage是由一组并行的task组成。
stage切割规则
切割规则:从后往前,遇到宽依赖就切割stage。
stage计算模式
pipeline管道计算模式,pipeline只是一种计算思想,模式。
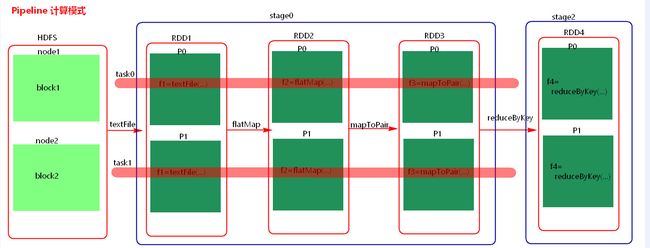
1、Spark的pipeLine的计算模式,相当于执行了一个高阶函数f3(f2(f1(textFile))) !+!+!=3 也就是来一条数据然后计算一条数据,把所有的逻辑走完,然后落地,准确的说一个task处理遗传分区的数据 因为跨过了不同的逻辑的分区。而MapReduce是 1+1=2,2+1=3的模式,也就是计算完落地,然后在计算,然后再落地到磁盘或内存,最后数据是落在计算节点上,按reduce的hash分区落地。所以这也是比Mapreduce快的原因,完全基于内存计算。
2、管道中的数据何时落地:shuffle write的时候,对RDD进行持久化的时候。
3.Stage的task并行度是由stage的最后一个RDD的分区数来决定的 。一般来说,一个partiotion对应一个task,但最后reduce的时候可以手动改变reduce的个数,也就是分区数,即改变了并行度。例如reduceByKey(XXX,3),GroupByKey(4),union由的分区数由前面的相加。
4.、如何提高stage的并行度:reduceBykey(xxx,numpartiotion),join(xxx,numpartiotion)