演示HTML地址
演示HTML页面地址:https://python123.io/ws/demo.html
文件名称:demo.html
产生步骤
步骤1:建立一个Scrapy爬虫工程
生成工程目录代码(CMD):
scrapy startproject python123demo生成的工程目录
python123demo/ →外层目录
scrapy.cfg →部署Scrapy爬虫的配置文件
python123demo/ →Scrapy框架的用户自定义python代码
_init_.py → 初始化脚本
items.py → Items代码模块(继承类)
middlewares.py →Middlewares代码模板(继承类)
pipelines.py →Pipelines代码模板(继承类)
settings.py →Scrapy爬虫的配置文件
spiders/ →Spiders代码模板目录(继承类)
_init_.py → 初始文件,无需修改
_pycache_/ →缓存目录,无需修改
步骤2:在工程中产生一个Scrapy爬虫
cmd命令生成爬虫:
cd .\python123demo\
scrapy genspider demo python123.io
//python123.io为要爬取的域名会在spider文件中生成demo.py文件
demo.py文件代码分析:
import scrapy
class DemoSpider(scrapy.Spider): //继承scrapy.Spider类的子类
name = 'demo' //爬虫名字叫demo
allowed_domains = ['python123.io'] //爬取网站的时候只能爬取这个域名以下的相关链接
start_urls = ['http://python123.io/'] //以列表形式包含的一个或者多个url,scrapy所要爬取页面的初始页面
def parse(self, response): //解析页面的空方法
passparse()用于处理响应,解析内容形成字典,发现新的URL爬取请求
步骤3:配置产生的spider爬虫
修改爬虫代码:
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
start_urls = ['https://python123.io/ws/demo.html']
def parse(self, response):
fname=response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
self.log('Saved file %s.' %fname)
我们在demo.py目录下用cmd命令执行文件
scrapy crawl demo如果缺少包执行失败我们可以进入CMD命令安装pywin32包
pip install pywin32执行结果如下,会生成一个html文件
命令行如下:
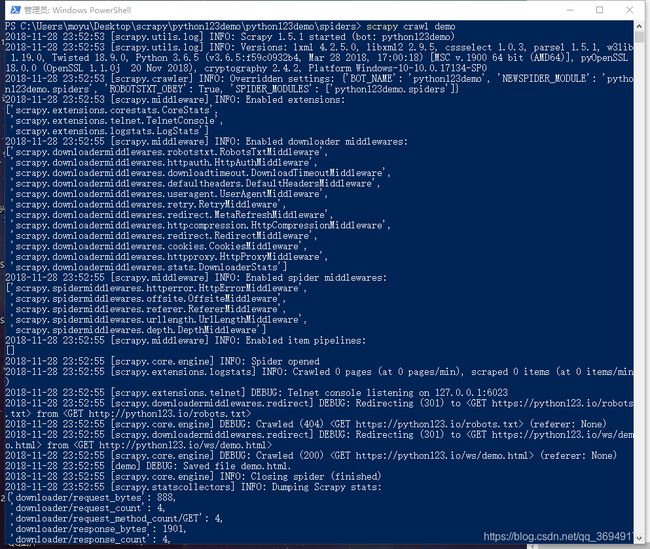
生成的文件如下

上面是简化版代码,完整版本代码如下:
import scrapy
class DemoSpider(scrapy.Spider):
name="demo1"
def start_requests(self):
urls=[
'http://moyu.studiosworks.cn/'
]
for url in urls:
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
fname='1'
with open(fname,'wb') as f:
f.write(response.body)
self.log('Saved file %s.' % fname)
yield关键字
yield←→生成器
*生成器是一个不断产生值的函数
*包含yield语句的函数是一个生成器
*生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值。
生成器解释实例:
def gen(n):
for i in range(n):
yield i**2 //每调用一次产生一个值,再次调用产生第二个值...(只占用一个值的空间)
for i in gen(5):
print(i,'',end='') //遍历数组
上述普通写法:
def square(n):
ls=[i**2 for i in range(n)] //存储n个值
return ls
for i in square(5):
print(i,"",end="") //遍历数组
为什么要有生成器?
生成器相比一次列出所有内容的优势
1、更节省存储空间
2、响应更迅速
3、使用更灵活