Node.js基本使用和语法
Node.js语法
1.1Node.js基本语法
1.1.1HelloWorld,最简单搭建一个服务器
//require表示引包,引包就是引用自己的一个特殊功能
var http = require("http");
//创建服务器,参数是一个回调函数,表示如果有请求进来,要做什么
var server = http.createServer(function(req,res){
//req表示请求,request; res表示响应,response
//设置HTTP头部,状态码是200,文件类型是html,字符集是utf8
res.writeHead(200,{"Content-type":"text/html;charset=UTF-8"});
res.end("哈哈哈哈,我买了五个iPhone" + (1+2+3) + "s");
});
//运行服务器,监听3000端口(端口号可以任改,此时的是‘127.0.0.1’)
server.listen(3000,"127.0.0.1");注意:res.end()的内容必须为字符串
1.1.2运行Node.js
1.运行
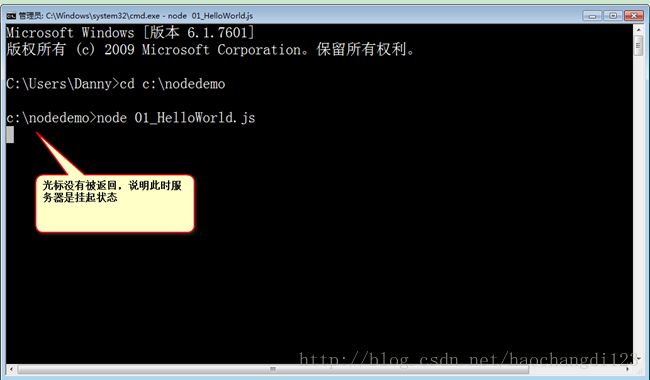
Node.js是服务器的程序,写的js语句,都将运行在服务器上。返回给客户的,都是已经处理好的纯html。
node [name].js
表示运行你自己的文件,[name]就是你实际的文件名字,再打开浏览器
2.修改
如果想修改程序,必须中断当前运行的服务器,重新node一次,刷新,才行。
ctrl+c,就可以打断挂起的服务器程序。此时按上箭头,能够快速调用最近的node命令。
3.总结
你会发现,我们本地写一个js,打死都不能直接拖入浏览器运行,但是有了node,我们任何一个js文件,都可以通过node来运行。也就是说,node就是一个js的执行环境。
我们现在,要跑起来一个服务器,这个服务器的脚本,要以.js存储。是一个js文件。用node命令运行这个js文件罢了。
1.1.3简单的案例演示
//require表示引包,引包就是引用自己的一个特殊功能
var http = require("http");
var fs = require("fs");
//创建服务器,参数是一个回调函数,表示如果有请求进来,要做什么
var server = http.createServer(function(req,res){
if(req.url == "/fang"){
fs.readFile("./test/xixi.html",function(err,data){
//req表示请求,request; res表示响应,response
//设置HTTP头部,状态码是200,文件类型是html,字符集是utf8
res.writeHead(200,{"Content-type":"text/html;charset=UTF-8"});
res.end(data);
});
}else if(req.url == "/yuan"){
fs.readFile("./test/haha.html",function(err,data){
//req表示请求,request; res表示响应,response
//设置HTTP头部,状态码是200,文件类型是html,字符集是utf8
res.writeHead(200,{"Content-type":"text/html;charset=UTF-8"});
res.end(data);
});
}else if(req.url == "/0.jpg"){
fs.readFile("./test/0.jpg",function(err,data){
//req表示请求,request; res表示响应,response
//设置HTTP头部,状态码是200,文件类型是html,字符集是utf8
res.writeHead(200,{"Content-type":"image/jpg"});
res.end(data);
});
}else if(req.url == "/bbbbbb.css"){
fs.readFile("./test/aaaaaa.css",function(err,data){
//req表示请求,request; res表示响应,response
//设置HTTP头部,状态码是200,文件类型是html,字符集是utf8
res.writeHead(200,{"Content-type":"text/css"});
res.end(data);
});
}else{
res.writeHead(404,{"Content-type":"text/html;charset=UTF-8"});
res.end("嘻嘻,没有这个页面呦");
}
});
//运行服务器,监听3000端口(端口号可以任改)
server.listen(3000,"127.0.0.1");Node.js没有根目录的概念,因为它根本没有任何的web容器!
让node.js提供一个静态服务,都非常难!
也就是说,node.js中,如果看见一个网址是
127.0.0.1:3000/fang别再去想,一定有一个文件夹,叫做fang了。可能/fang的物理文件,是同目录的test.html
URL和真实物理文件,是没有关系的。URL是通过了Node的顶层路由设计,呈递某一个静态文件的。
例如上面的例子就是访问127.0.0.1:3000/fang时去读”./test/haha.html”文件。当然我们也可以去读别的文件夹中的文件。
1.1.4 HTTP模块
Node.js中,将很多的功能,划分为了一个个mudule,大陆的书翻译为模块;台湾的书,翻译为模组。
这是因为,有一些程序需要使用fs功能(文件读取功能),有一些不用的,所以为了效率,你用啥,你就require啥。
//这个案例简单讲解http模块
//引用模块
var http = require("http");
//创建一个服务器,回调函数表示接收到请求之后做的事情
var server = http.createServer(function(req,res){
//req参数表示请求,res表示响应
console.log("服务器接收到了请求" + req.url);
res.end();
});
//监听端口
server.listen(3000,"127.0.0.1");
设置一个响应头:
res.writeHead(200,{"Content-Type":"text/plain;charset=UTF8"});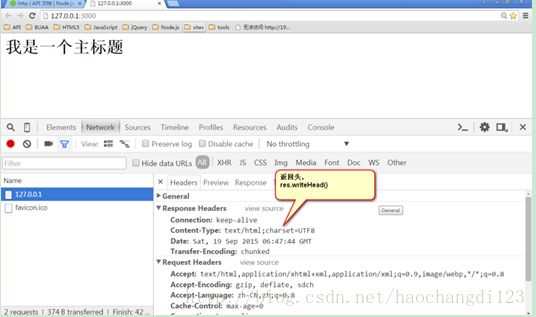
01—案例3
1.1.5 URL模块
我们现在来看一下req里面能够使用的东西。
最关键的就是req.url属性,表示用户的请求URL地址。所有的路由设计,都是通过req.url来实现的。
我们比较关心的不是拿到URL,而是识别这个URL。
识别URL,用到url模块
API :http://nodejs.cn/api/url.html#url_url_parse_urlstring_parsequerystring_slashesdenotehost
var http = require("http");
//引入url模块
var URL = require("url");
var server = http.createServer(function(req,res){
//不处理小图标(浏览器地址旁边的小图标)
if(req.url == "/favicon.ico"){
return;
}
//url.parse()可以将一个完整的URL地址,分为很多部分:
//host、port、pathname、path、query
var pathname = URL.parse(req.url).pathname;
//url.parse()如果第二个参数是true,那么就可以将所有的查询变为对象
//就可以直接打点得到这个参数
var query = URL.parse(req.url,true).query;
var url = URL.parse(req.url,true)
console.log(url);
res.end();
});
server.listen(3000,"127.0.0.1");假设我们访问http://127.0.0.1:3000/hcd?name=1
则console.log(url)为:
Url {
protocol: null,
slashes: null,
auth: null,
host: null,
port: null,
hostname: null,
hash: null,
search: '',
query: {},
pathname: '/hcd?name=1',
path: '/hcd?name=1',
href: '/hcd?name=1'
}01—案例3
1.1.5.2URL模块的简单案例
将表单提交后,获取提交的数据
Form.html:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Documenttitle>
head>
<body>
<form action="http://127.0.0.1:3000/" method="GET">
<input type="text" name="name" /> <br />
<input type="text" name="age" /> <br />
<input type="radio" name="sex" value="男"/> 男
<input type="radio" name="sex" value="女"/> 女
<br />
<input type="submit">
form>
body>
html>注意input的name属性,URL.parse(req.url,true).query对象就是通过name属性找属性值的。
Node.js:
var http = require("http");
var URL = require("url");
var server = http.createServer(function(req,res){
console.log(URL.parse(req.url,true))
//得到查询部分,由于写了true,那么就是一个对象,query是提交的数据集合的对象
var queryObj = URL.parse(req.url,true).query;
var name = queryObj.name;
var age = queryObj.age;
var sex = queryObj.sex;
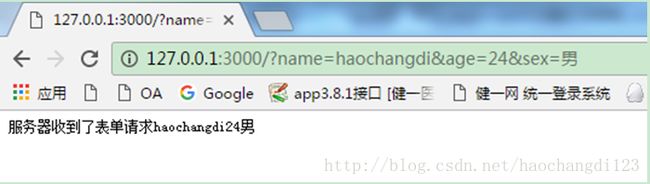
res.end("服务器收到了表单请求" + name + age + sex);
});
server.listen(3000,"127.0.0.1");运行代码:

运行结果:
首先我们来看这时的URL对象:
Url {
protocol: null,
slashes: null,
auth: null,
host: null,
port: null,
hostname: null,
hash: null,
search: '?name=haochangdi&age=24&sex=%E7%94%B7',
query: { name: 'haochangdi', age: '24', sex: '男' },
pathname: '/',
path: '/?name=haochangdi&age=24&sex=%E7%94%B7',
href: '/?name=haochangdi&age=24&sex=%E7%94%B7'
}可以看到汉字‘男’被编码了,并且query属性是传递的数据的对象
页面显示:
01—案例6
1.1.6 router
由上面的URL模块我们知道通过req.url可以获得请求的地址,下面我们来做一个路由案例
var http = require("http");
var server = http.createServer(function(req,res){
//得到url
var userurl = req.url;
res.writeHead(200,{"Content-Type":"text/html;charset=UTF8"})
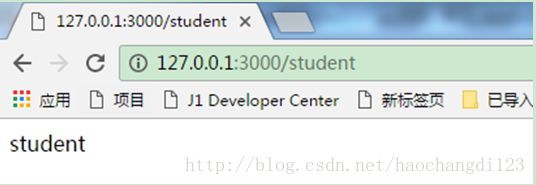
//如果请求的地址为"/student"
if(userurl == "/student"){
res.end("student");
//如果请求的地址为"/teacher"
}else if(userurl == "/teacher"){
res.end("teacher");
//如果请求的地址没有
}else{
res.end("404");
}
});
server.listen(3000,"127.0.0.1");结果为:
访问student:
访问teacher:

访问不存在的地址:

[01—案例7](https://github.com/haochangdi123/cleanUP-Node.js/tree/master/01)1.1.7 fs模块
Nodejs的文件系统
API:
http://www.runoob.com/nodejs/nodejs-fs.html
http://nodejs.cn/api/fs.html#fs_class_fs_stats
0.注意事项:
fs创建或者读取文件时是以cmd中的入口文件为基本的,比如:
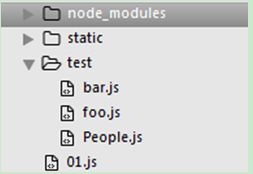
我们在cmd中运行:node 01.js
那么我们任何文件中用到fs时都是以01.js问基准找文件的,比如在bar.js中找foo.js是‘./test/fss.js’
所以我们一般fs时是以——dirname这样的绝对路径的方式找文件的。
1. 创建文件夹
fs. mkdir()创建文件夹
var http = require("http");
var fs = require("fs");
var server = http.createServer(function(req,res){
//不处理小图标
if(req.url == "/favicon.ico"){
return;
}
//在此node.js文件的同级album文件夹下创建一个aaa文件夹
fs.mkdir("./album/aaa");
});
server.listen(3000,"192.168.41.30");01—案例9
2.检测文件状态
fs.stat(path, callback) 查看path路径的文件的状态,callback为查看完后的回调函数
var http = require("http");
var fs = require("fs");
var server = http.createServer(function(req,res){
//不处理小图标
if(req.url == "/favicon.ico"){
return;
}
//stat检测状态
fs.stat("./album/bbb",function(err,data){
//检测这个路径,是不是一个文件夹,返回true或false
console.log(data.isDirectory());
//检测这个路径,是不是一个文件,返回true或false
console.log(data.isFile());
});
});
server.listen(3000,"127.0.0.1");01—案例10
3.读取文件或者文件夹
读取文件:
fs.readFile('/etc/passwd', (err, data) => {
if (err) throw err;
console.log(data);
});读取文件夹:
fs.readdir(‘/etc/hcd’, (err, data) => {
if (err) throw err;
console.log(data);
});
4.更改文件的名字
fs.rename([oldpath],[newpath],callback)
5.简单案例—列举album文件夹中的所有的文件
先看一下文件结构:
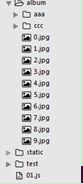
假设我们写node.js的文件就是01.js,而album文件是和01.js平级的。album文件中有aaa,ccc文件夹,还有多张图片文件,我们只将文件夹列举出出来
平时习惯的错误写法:
var http = require("http");
var fs = require("fs");
var server = http.createServer(function(req,res){
//不处理小图标
if(req.url == "/favicon.ico"){
return;
}
//存储所有的文件夹
var wenjianjia = [];
//stat检测状态
fs.readdir("./album",function(err,files){
//files是个文件名的数组,并不是文件的数组,表示./album这个文件夹中的所有东西
//包括文件、文件夹
for(var i = 0 ; i < files.length ;i++){
var thefilename = files[i];
//又要进行一次检测
fs.stat("./album/" + thefilename , function(err,stats){
//如果他是一个文件夹,那么输出它:
if(stats.isDirectory()){
wenjianjia.push(thefilename);
}
//看每一次循环出的数组是怎样的,可以不要,直接最后输出
console.log(wenjianjia);
});
}
});
});
server.listen(3000,"127.0.0.1");结果:
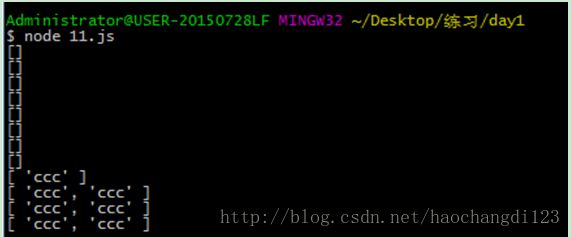
会发现和我们想要的结果是不一样的,这是因为node.js是异步的,单线程非阻塞I/O,导致出错(把每一次遍历的结果都cosole是为了看的更清楚),我们可以利用(function(){})()这样的立即执行函数解决,或者利用ES6的语法,使用let解决
01—案例11
正确的:
var http = require("http");
var fs = require("fs");
var server = http.createServer(function(req,res){
//不处理收藏夹小图标
if(req.url == "/favicon.ico"){
return;
}
//遍历album里面的所有文件、文件夹
fs.readdir("./album/",function(err,files){
//files : ["0.jpg","1.jpg" ……,"aaa","bbb"];
//files是一个存放文件(夹)名的数组
//存放文件夹的数组
var wenjianjia = [];
//迭代器就是强行把异步的函数,变成同步的函数
//1做完了,再做2;2做完了,再做3
(function iterator(i){
//遍历结束
if(i == files.length){
console.log(wenjianjia);
return;
}
fs.stat("./album/" + files[i],function(err,stats){
//检测成功之后做的事情
console.log(stats)
if(stats.isDirectory()){
//如果是文件夹,那么放入数组。不是,什么也不做。
wenjianjia.push(files[i]);
}
iterator(i+1);
});
})(0);
});
res.end();
});
server.listen(3000,"127.0.0.1");结果:

01—案例12
1.1.8 path模块
API http://nodejs.cn/api/path.html#path_path_extname_path
path.extname() 方法返回 path 的扩展名,
即从 path 的最后一部分中的最后一个 .(句号)字符到字符串结束。 如果 path 的最后一部分没有 . 或 path 的文件名(见 path.basename())的第一个字符是 .,则返回一个空字符串。
path.extname('index.html');
// 返回: '.html'path.extname('index.coffee.md');
// 返回: '.md'path.extname('index.');
// 返回: '.'path.extname('index');
// 返回: ''path.extname('.index');
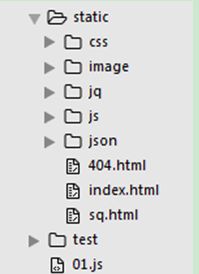
// 返回: ''1.1.9一个比较完整的静态资源案例
文件的目录结构:
var http = require("http");
var url = require("url");
var fs = require("fs");
var path = require("path");
http.createServer(function(req,res){
//得到用户的路径
var pathname = url.parse(req.url).pathname;
//默认首页
if(pathname == "/"){
pathname = "index.html";
}
//拓展名
var extname = path.extname(pathname);
//真的到文件的实际地址去读取这个文件
fs.readFile("./static/" + pathname,function(err,data){
if(err){
//如果此文件不存在,就应该用404返回
fs.readFile("./static/404.html",function(err,data){
res.writeHead(404,{"Content-type":"text/html;charset=UTF8"});
res.end(data);
});
return;
};
//MIME类型,就是
//网页文件: text/html
//jpg文件 : image/jpg
var mime = getMime(extname);
res.writeHead(200,{"Content-type":mime});
res.end(data);
});
}).listen(3000,"127.0.0.1");
function getMime(extname){
switch(extname){
case ".html" :
return "text/html";
break;
case ".jpg" :
return "image/jpg";
break;
case ".css":
return "text/css";
break;
}
}结果就是在读取http://127.0.0.1:3000/路径时回去读取”./static/index.html”
01—案例13
git地址:https://github.com/haochangdi123/cleanUP-Node.js