基于上一次运行成功查看输出文件没有结果的经历,这一次仔细理解了pso的MapReduce代码,发现自己之前的输入数据并不符合代码要求的格式,于是加以修改了。
根据此代码,输入数据应该是如下字段:
粒子编号、位置向量1、粒子速度1、个人最优位置1、全局最优位置1、位置向量2、粒子速度2、个人最优位置2、全局最优位置2、个人最优值、全局最优值
注意:这里由于代码中维度设为2,,所以位置向量、粒子速度、个人最优位置、全局最优位置都不是单纯的标量,而是要用二维形式表示,如位置向量position要用(x1,x2)来表示。
因此,上面的如“位置向量1”后面的1仅仅代表位置向量的第1维度值而已。
不难理解,若种群所处空间维度为n,位置向量position就得用(x1,x2,...,xn)来表示,其他三者也是一样的。
个人最优值和全局最优值是根据适应度函数计算得出,设为标量。
另外,我了解到,种群维度的选择其实是与目标适应度函数的维度相关联的。代码中用到的是Ackley 函数,有关介绍可参考这里https://wenku.baidu.com/view/9e0e6838650e52ea55189870.html
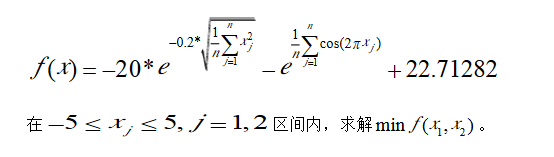
这个函数的维度就是二维,因而代码中种群所处空间维度设为2。
psodata.txt(自己编造的数据)
1 11 3 4 5 4 3 2 7 3 1 2 2 3 4 8 5 3 1 1 8 1 3 22 17 8 1 13 6 26 2 9 1 4 6 7 24 2 5 22 2 5 11 1 5 2 33 3 9 4 6 7 12 17 1 6 33 3 2 12 15 3 9 11 10 1 7 19 4 23 45 9 9 12 2 8 1 8 15 13 4 25 4 3 12 7 6 1 9 2 9 14 8 15 3 11 10 8 1 10 2 7 8 11 13 9 6 26 4 1 11 16 3 4 42 15 22 32 15 19 1 12 23 3 1 19 4 26 7 17 11 1 13 3 23 22 2 5 3 9 21 13 1 14 9 7 3 25 19 16 12 6 19 1 15 7 6 12 22 15 17 10 8 7 1 16 32 33 13 9 14 16 3 12 14 1 17 33 3 2 12 15 3 9 11 10 1 18 19 4 23 45 9 9 41 2 8 1 19 15 13 3 25 4 3 21 7 6 1 20 12 9 4 15 8 13 11 13 18 1
为了简练,下面是只将迭代次数设为3的jar包运行过程,发现最后得到的输出文件只有一个part-r-00000(观察得知,是第0次运行成功得到的结果,第1次运行失败了,第三次虽然也运行成功了,但是map输入记录却是0)。
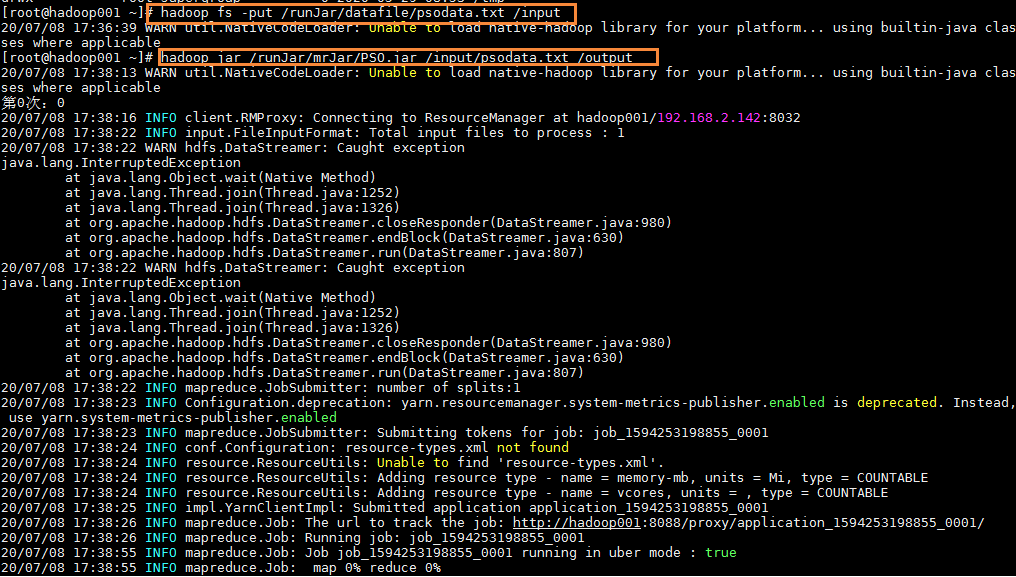
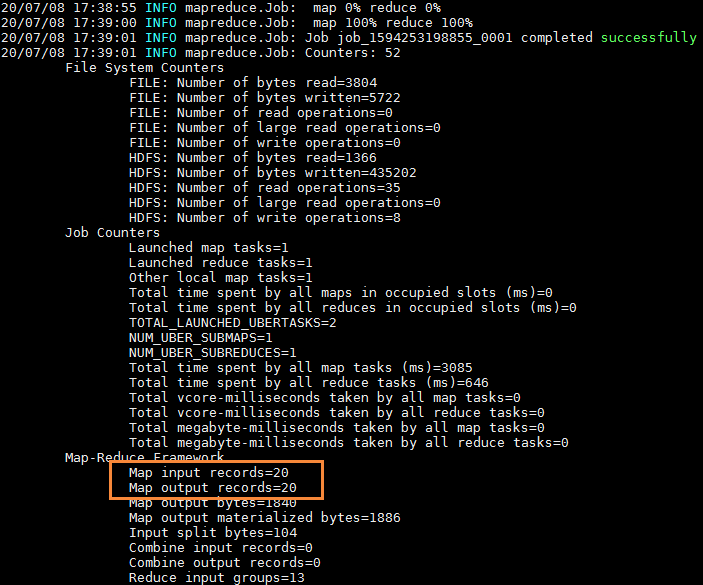

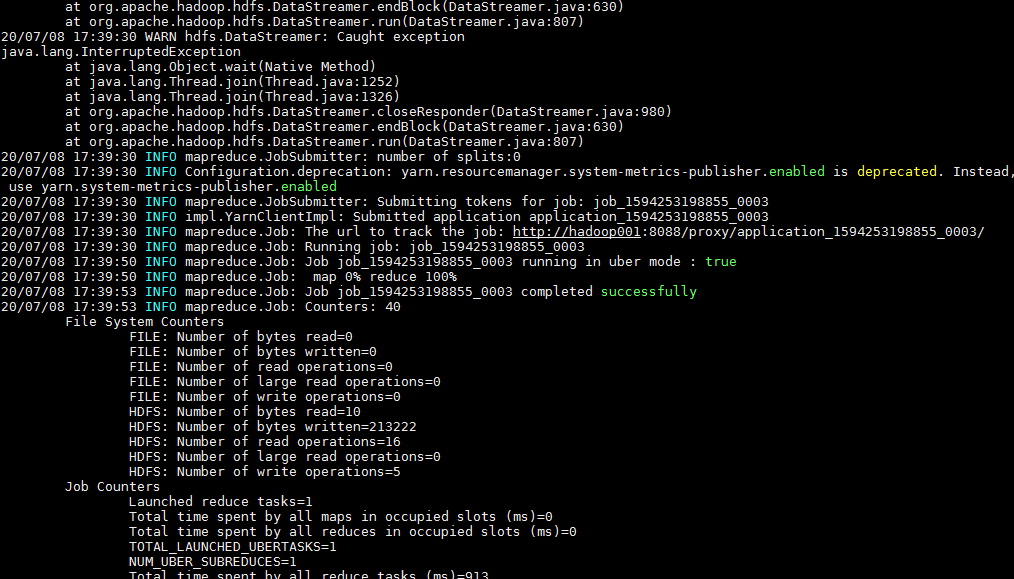
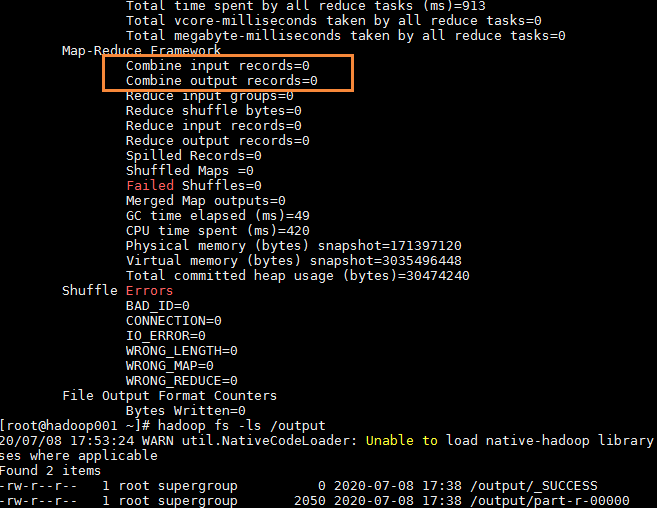
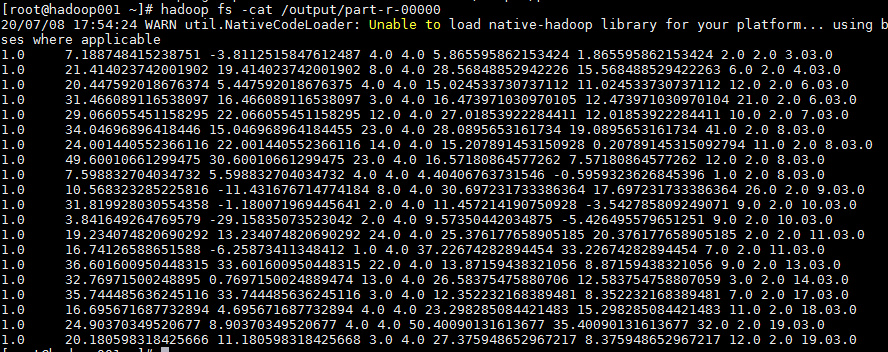
观察上面唯一一次成功得到的数据,还是满足预期的。字段含义分别是:
1(单纯设为的1)、位置向量1、粒子速度1、个人最优位置1、全局最优位置1、位置向量2、粒子速度2、个人最优位置2、全局最优位置2、个人最优值、全局最优值
种群中各个粒子状态栏中记录的全局最优位置和全局最优值是一致的,只是个人最优值有所差异,可大致判断代码执行的逻辑基本正确。
至于为什么只得到一个输出文件,接下来打算仔细分析一下。
先从作业日志着手好了

上面的解决办法查了一下https://blog.csdn.net/lisongjia123/article/details/78639058/
又运行了一遍,第1次还是失败

日志显示错误是这样
2020-07-08 22:25:53,159 INFO [uber-SubtaskRunner] org.apache.hadoop.mapred.LocalContainerLauncher: removed attempt attempt_1594271377493_0003_m_000000_1000 from the futures to keep track of
2020-07-08 22:25:53,166 INFO [uber-SubtaskRunner] org.apache.hadoop.mapred.LocalContainerLauncher: mapreduce.cluster.local.dir for uber task: /hadoop/temp/nm-local-dir/usercache/root/appcache/application_1594271377493_0003
2020-07-08 22:25:53,166 ERROR [uber-SubtaskRunner] org.apache.hadoop.mapred.LocalContainerLauncher: CONTAINER_REMOTE_LAUNCH contains a reduce task (attempt_1594271377493_0003_r_000000_1000), but not yet finished with maps
2020-07-08 22:25:53,167 WARN [uber-SubtaskRunner] org.apache.hadoop.mapred.LocalContainerLauncher: Exception running local (uberized) 'child' : java.lang.RuntimeException
at org.apache.hadoop.mapred.LocalContainerLauncher$EventHandler.runSubtask(LocalContainerLauncher.java:458)
at org.apache.hadoop.mapred.LocalContainerLauncher$EventHandler.runTask(LocalContainerLauncher.java:350)
at org.apache.hadoop.mapred.LocalContainerLauncher$EventHandler.access$200(LocalContainerLauncher.java:211)
at org.apache.hadoop.mapred.LocalContainerLauncher$EventHandler$1.run(LocalContainerLauncher.java:254)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2020-07-08 22:25:53,167 ERROR [uber-SubtaskRunner] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Status update was called with illegal TaskAttemptId: attempt_1594271377493_0003_r_000000_1000
2020-07-08 22:25:53,168 WARN [uber-SubtaskRunner] org.apache.hadoop.mapred.Task: Parent died. Exiting attempt_1594271377493_0003_r_000000_1000
2020-07-08 22:25:53,169 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1594271377493_0003_m_000000_1000 transitioned from state RUNNING to FAILED, event type is TA_CONTAINER_COMPLETED and nodeId=hadoop001:55834
2020-07-08 22:25:53,171 INFO [uber-EventHandler] org.apache.hadoop.mapred.LocalContainerLauncher: Processing the event EventType: CONTAINER_COMPLETED for container container_1594271377493_0003_02_000001 taskAttempt attempt_1594271377493_0003_m_000000_1000
2020-07-08 22:25:53,173 INFO [uber-SubtaskRunner] org.apache.hadoop.util.ExitUtil: Exiting with status 66: ExitException
2020-07-08 22:25:53,174 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: TaskAttempt: [attempt_1594271377493_0003_r_000000_1000] using containerId: [container_1594271377493_0003_02_000001 on NM: [hadoop001:55834]
2020-07-08 22:25:53,174 INFO [AsyncDispatcher event handler] org.apache.hadoop.mapreduce.v2.app.job.impl.TaskAttemptImpl: attempt_1594271377493_000
上网百度时,stackflow里面有个回答说是建议调大mapred.reduce.slowstart.completed.maps(在mapred-site.xml中),默认的值是0.05(5%),建议调到0.80(80%)提高吞吐量:https://stackoverflow.com/questions/21509272/must-hadoop-finish-maps-before-reduce

这是设置方法https://blog.csdn.net/chybin500/article/details/80417534?utm_source=blogxgwz5
网上相同问题https://blog.csdn.net/a822631129/article/details/50116705给出的解释是绿色字体这样,但没告诉解决办法!?这个监控很重要到底啥意思呢?

“错误很明显,磁盘空间不足,但郁闷的是,进各节点查看,磁盘空间使用不到40%,还有很多空间。
郁闷很长时间才发现,原来有个map任务运行时输出比较多,运行出错前,硬盘空间一路飙升,直到100%不够时报错。随后任务执行失败,释放空间,把任务分配给其它节点。正因为空间被释放,因此虽然报空间不足的错误,但查看当时磁盘还有很多剩余空间。
这个问题告诉我们,运行过程中的监控很重要。”
我感觉先还是要解决reduce任务有,但map还未完成的问题。。。。
可找的经验好少啊
Hadoop history配置https://www.cnblogs.com/MrFee/p/jobhistory.html,配置好后点击这里的history就不会页面错误了,而是会显示错误日志。

第二次迭代还是会出现问题,如下
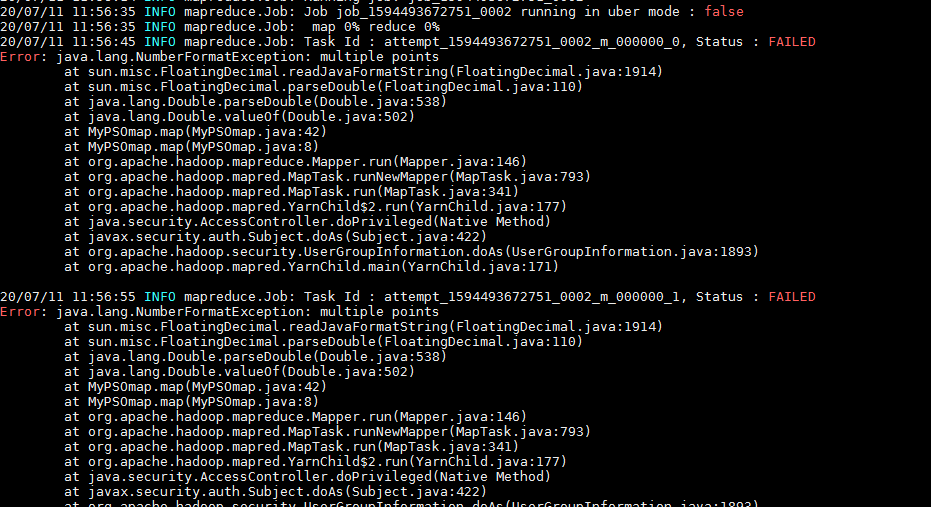
网上查原因都是讲的多线程不安全问题,但我的问题又不完全和他们相同
直到。。。一个人说了句“在多线程环境下,一定要注意共享变量的线程安全问题,如无特殊必要,建议不要随便定义静态公共变量,如果非要定义,建议考虑好多线程的问题!”
我抱着试试看的态度把代码中定义的静态变量全删除了static,然后重新导出jar包放到hadoop上运行,终于不再是只有第一次迭代成功之后错误的状态了,后面的迭代也能正常进行了!