神经网络 和 NLP —— RNN
前段时间一口气读完了 NN4NLP,很是畅快,非常喜欢作者行文讲解的口吻和逻辑。大概两周读完,每页都有收获,读完后反而担心有所疏漏,知识太多留不住,索性从头来一遍,把学习过程的知识点和思考记录下来,也算精简版供自己今后查阅。
感兴趣的,可以一起学习讨论,真的很推荐这本书。
大致介绍下该书。NN4NLP 由 Goldberg 撰写,是 CMU CS11-747 课程的教材,配合公开课食用更佳,公开课链接。本书并非系统介绍 NN 和 NLP,而是聚焦 NN 在 NLP 领域的具体应用,所以分成了四大部分:NN 中前馈神经网络的入门,前馈神经网络在 NLP 中的应用,RNN 等特殊结构在 NLP 中的应用,部分前沿方向介绍。
因此,本博客也打算分成多篇进行总结,其他篇章请自行搜索本博客。
特殊结构的神经网络
RNN
前面提到,CBOW 可以将任意长度的序列编码为固定尺寸的向量,但忽视了序列中的顺序信息。
卷积网络也可以将任意长度的序列编码为固定尺寸的向量,并且实现了对顺序信息的一些捕捉,但捕捉到的顺序信息仍陷于局部 pattern,而且忽视了在序列中彼此分布较远的 pattern 的顺序信息。
RNN 可以将任意长度的序列编码为固定尺寸的向量,同时可以捕获序列中的结构特性。尤其是 RNN 中门限结构的网络,如 LSTM 和 GRU 等,更善于捕捉序列中的统计规律。这些结构可以称得上是深度学习对统计自然语言处理的最大贡献。
RNN 基础
基本概念
RNN 提供了不依赖于马尔科夫假设就实现以整个历史 x_{1:i} 为条件的框架。RNN 可以看做一个输入为任意多个 d_in 维向量构成的有序序列,输出为一个 d_out 维向量的函数,即 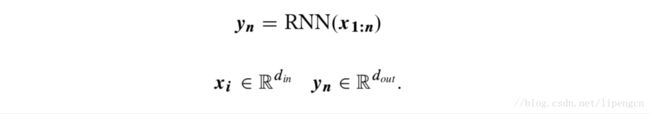
这实际上也可以写作下列形式 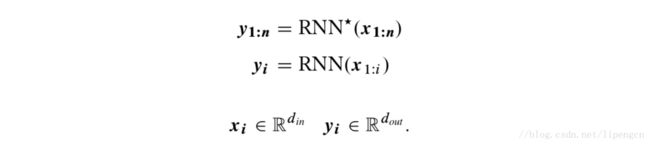
通常 y_n 被用作后续的预测任务。
通过定义函数 R 和 O,用 s 表示状态,就可以把上述 RNN 表示为递归形式,即 
这里函数 O 是为了统一后续不同 RNN 结构叙述方式而给出的,实际上,对于 Simple-RNN 和 GRU 结构来说,O 是一个恒等映射,对于 LSTM 结构来说,O 从状态 s 里选取一个固定的子集。
因此,RNN 可以绘成如下形式 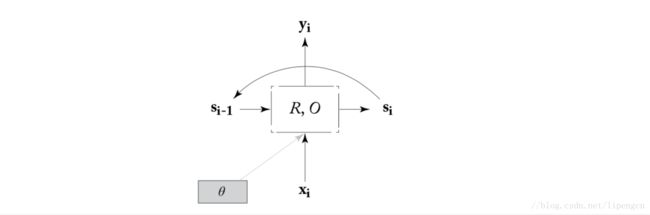
这个结构遵循了上述递归形式的定义,而且适用于无限长序列。但实际中显然处理的是有限长度的序列,因而多把递归形式展开,如下 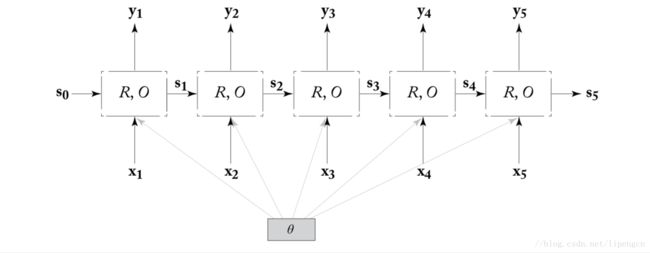
图中参数 θ 表现出了所有 time steps 共享相同的参数。不同的 R 和 O 形式会产生不同的网络结构,从而展现出不同的特性,但 RNN 的基本概念是不变的都是如上所述的。后面我们会具体介绍几种 R 和 O 的实例产生的不同 RNN 实例 —— Simple-RNN、LSTM 和 GRU。
从时序角度看,下图更易于理解 RNN 的内部拓扑结构: 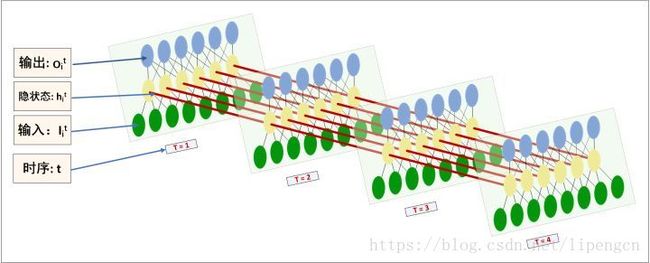
training
网络训练的任务就是设定 R 和 O 使得状态能表达我们关注的任务中的有用信息。
从上面的展开图可以看出,RNN 实际就是一个非常深的神经网络,或者说有着有点复杂的节点的很大的计算图,这里面参数在多层间共享,额外的输入加到了各个层。所以训练 RNN 网络,要做的事也没什么区别,就是针对输入序列建造展开的计算图,为展开图添加一个损失节点,然后根据这个损失利用反向传布算法计算梯度。这个过程在 RNN 文献中通常称为 backpropagation through time(BPTT)。
当然,还是那句话,RNN 不是孤立使用的,输出要 feed 进后面的网络。
举例:
step1,raw text。
step2,tokenize
step3,dictionarize。
step4,padding every sentence to fixed length。
step5,mapping token to an embeddings,矩阵的列代表一个词向量,矩阵的列数固定为 padded sentence length。
step6,feed into RNNs as input,假设一个RNN的 time_step length 确定为 l ,则 padded sentence length 固定为 l。一次RNNs的run只处理一条sentence。每个sentence的每个token的embedding对应了每个时序 t 的输入 I_i^t 。一次RNNs的run,连续地将整个sentence处理完。
step7,get output。
常见使用模式
(1)Acceptor
此时,直接基于输出向量 y_n 进行预测,RNN 被当成一个 acceptor 进行训练。如下图 
(2)Encoder
此时,也是基于输出向量 y_n 进行预测,但预测模块不仅利用 y_n 还利用其它特征。
(3)Transducer
此时,RNN 对每个输入产生一个输出,从而为每个输出产生一个局部损失,最后结合所有局部损失构成展开序列的损失,如下图 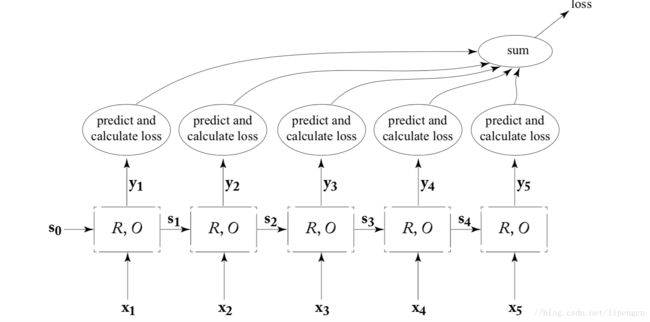
RNN 的 Transducer 用法很自然地用在语言模型中,使得不必再进行马尔科夫假设,就可以以整个预测历史为条件,即词序列 x_{1:i} 被用来与预测第 i+1 个词的分布。
RNN 的 Transducer 特殊形式有 RNN generator 以及相关的 conditioned-generation 和有 attention 结构的 conditioned-generation,这些后面再讲。
双向 RNN
RNN 允许关注任意远的过去序列,从而放宽了马尔科夫假设。biRNN 允许关注任意远的过去序列和未来序列,从而放宽了固定尺寸窗口的假设。
biRNN 通过在每个序列位置 i 设定两个不同的状态 s_i^f 和 s_i^b 来实现上述想法。前向状态 s_i^f 基于 x_{1:i},后向状态基于 x_{n:i},这两个状态分别由不同的 RNN 产生。状态 s_i 就组合 s_i^f 和 s_i^b。输出 y_i 即两个输出 y_i^f=O(s_i^f) 和 y_i^b=O(s_i^b) 的 串联。也就是说,biRNN 对第 i 个词的编码实际是两个 RNN 结果的串联,一个从序列的开头读,一个从序列的末尾读。如下图示例 
biRNN 对标注任务非常有效,当然作为普通的特征抽取模块也很有用。
多层 RNN
RNN 可以按层堆叠形成一个网。如下图是一个三层深的 RNN 结构, 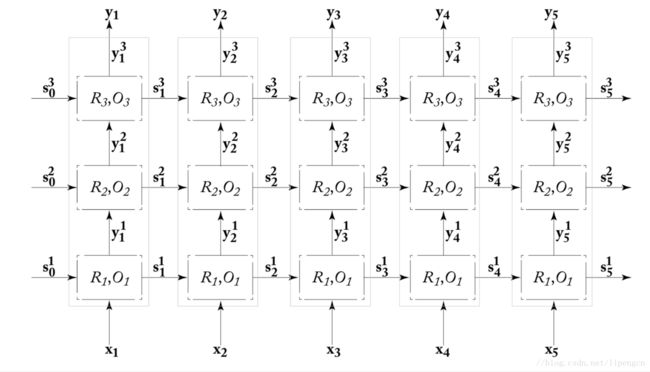
这种堆叠结构通常称为 deep RNN。虽然理论还没说明深层网络能提供什么更有力的增益,但实践证明 DRNN 比浅层 RNN 在一些任务上表现更好。
用 RNN 来表示栈
RNN 实例
下面具体介绍几种 R 和 O 的实例产生的不同 RNN 实例 —— Simple-RNN、LSTM 和 GRU。
Simple-RNN
特殊情况,R 为加和函数,O 为恒等映射,即 
实际 RNN 被简化成了 CBOW,但也丧失了顺序信息。
最简单的对顺序信息敏感的 RNN 结构为 Simple-RNN,或称 Elman 网络,即 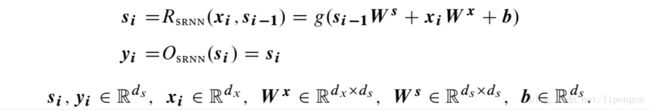
S-RNN 只是稍微比 CBOW 复杂了点,主要区别在于非线性激活函数 g。但这个区别却很关键,使得网络能捕获顺序信息。
S-RNN 对序列标注和语言模型任务都表现不错。
LSTM
门限结构:由于梯度消失问题,S-RNN 很难高效训练。在反向传播过程中,前面环节的误差信号/梯度小时的很快,无法到达更前面的输入信号,使得 S-RNN 难以捕获广范围的依赖。LSTM 和 GRU 等门限结构就是设计来解决这个缺陷的。
S-RNN 结构中每层都复用相同的矩阵 W,这将导致梯度计算包含多次的矩阵 W 的乘积运算,这很容易导致梯度值小时或者爆炸,门限机制解决这个问题的主要方法就是避免单个矩阵的重复乘积计算。
把 RNN 看做一个通用的计算设备,其中状态 s_i 代表一个有限的记忆。函数 R 的作用就是读取输入 x_i+1 和目前状态 s_i,然后将处理结果保存为新的状态 s_i+1。从这个角度看,S-RNN 显然没有提供控制记忆的方式,每次计算都是读取整个记忆然后写入整个记忆。门限结构提供的就是控制记忆存取的机制。
门限机制,即通过门限向量,控制对当前记忆状态 s_i 的读取,且是动态的,即可以被当前记忆状态和输入所控制,且其行为是可以学习的。
Long short-term memory (LSTM) 结构是 Hochreiter and Schmidhuber 2017 设计来解决梯度消失问题的,首创地引入了门限机制。
LSTM 结构将状态向量 s_i 切分成两部分,一部分作为 memory cell,一部分作为 working memory,前者设计来保存记忆、误差梯度、通过时间,受可微门组件控制,即仿真逻辑门的平滑的数学函数。LSTM 结构可以定义为 
时间 j 时的状态由两部分组成,c_j 时记忆部分,h_j 是隐状态部分。三个门限向量由输入和上一个隐状态确定。计算完更新候选 z 后,更新记忆 c,门限 f 控制保留多少上次记忆,门限 i 控制需要采用多少所提的更新。最后,隐状态部分 h_j,也是输出 y_j,由输出门限从记忆部分 c_j 中获取。
门限机制保证了和记忆部分 c_j 相关的梯度,即使经过很长的时间跨度,也保持较高的值,避免了梯度消失。
当训练 LSTM 网络时,Jozefowics2015 强烈推荐总是将遗忘门的 bias 部分初始化接近1。
GRU
虽然 LSTM 结构效果很好,但结构过于复杂,难以分析计算代价高。
Gated recurrent unit (GRU) 是 Cho2014 作为 LSTM 替代者提出的。
GRU 虽然基于门限机制,但减少了门限的数量,并取消了切分 memory 的思路,数学表达为 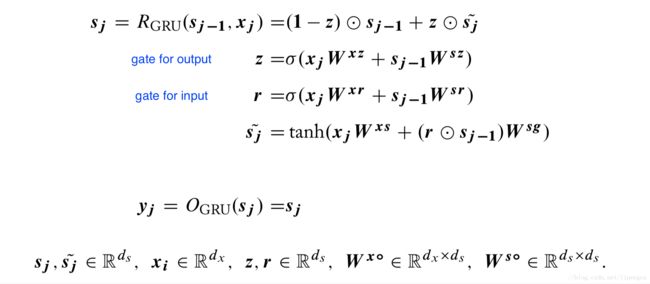
门限 r 用来控制对前一个状态 s_j-1 的读取,并计算出更新候选 s_j^~,更新后的状态 s_j 也是输出 y_j 由控制 s_j-1 和 s_j^~ 输出比例的门限 z 来控制。
目前 GPU 在语言模型和机器翻译任务重表现很好。GRU 和 LSTM 的孰优孰劣尚无定论。
其他变形
(1)无门限结构
基于门限结构的 LSTM 和 GRU 即缓解了 S-RNN 结构的梯度消失问题,也由于 RNN 结构捕捉到了跨越度较高的依赖特性。实际上有些新的无门限结构也能实现相似的优点。
Mikolov2014 提出将状态向量 s_i 切分成两部分,一部分为慢变部分 c_i,一部分为快变部分 h_i,具体可参阅文献,这个结构在语言模型任务上实现了 LSTM 相近的表现。
(2)超越可微门限
学术上还在研究新的结构,来仿真并实现更复杂的计算机制,并允许更精细的控制方式。其中一个案例是可微栈方面的研究。
虽然这方面的研究还不成熟,还没有鲁棒的通用的网络结构,但值得关注下。
Dropout
在 RNN 网络中使用 dropout 有点微妙,因为在不同的时间点上,dropout 掉不同的维度可能会损害 RNN 网络跨时间携带有信息的信号的能力。
Pham2013 和 Zaremba2014 建议只在非迭代连接中运用 dropout,即只用在深层 RNN 的层与层之间,而不用在序列位置之间。
但最近,Gal2015 又建议可以将 dropout 运用在 RNN 网络的任何部分,无论是迭代的还是非迭代的,关键是在所有时间段上保持一致的 dropout mask,即只针对每个序列采样一次 dropout mask,而非针对每个时间点。
目前在 RNN 中运用 dropout 最好的方式是上面提到的 Gal 的这种方式。
RNN 结构在 NLP 中应用
下面提到 RNN 默认为 LSTM 或者 GRU,谁让 S-RNN 通常表现出性能差一些。
作为 Acceptor
最简单应用就是作为一个 acceptor,输入一个序列,输出一个二元或多类的分类向量。
虽然 RNN 具有很强的序列学习能力,但这个能力在很多 NLP 任务重并不需要用,因为在很多任务中词序和句子结构并不太重要,往往基于 BOW 或者 bag-of-ngram 的分类器就能变现不错,甚至超过 RNN acceptor。
就像下面介绍的经典例子,情感分类,基于 RNN acceptor 的方法效果不错,但更简单的方法表现也不差。
(1)句子层面的情感分类
The task is straightforward to model using an RNN-acceptor: after tokenization, the RNN reads in the words of the sentence one at a time. The final RNN state is then fed into an MLP followed by a softmax-layer with two outputs. The network is trained with cross-entropy loss based on the gold sentiment labels.
It is often helpful to extend the model in Equation (16.1) by considering two RNNs, one reading the sentence in its given order and the other one reading it in reverse. The end states of
the two RNNs are then concatenated and fed into the MLP for classification: 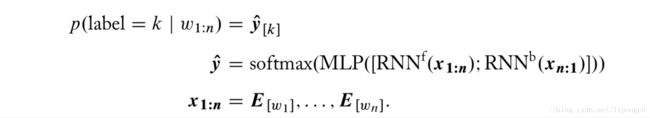
对于较长的句子,可以采用分层结构,即根据标点符号进行切分后,每部分进一个上述 biRNN 网络后,然后再将所有结果向量 feed 进一个单向 RNN,再进入 MLP 得到结果,性能更好。
(2)文档层面的情感分类
可以用与上面类似的分层。
作为 Feature extractor
RNN 主要用处就是作为可训练的灵活的特征提取器使用,可以替换部分更传统的特征提取器。RNN 尤其适合替换基于划窗的特征提取器。
(1)POS 标注
① 骨架采用deep biRNN,对于句子 s=w_{1:n},用特征函数 x_i = δ(s,i) 将其转化为输入向量 x_{1:n},然后输入到 deep biRNN 中,产生输出向量 y_{1:n},每个向量 y_i 再被 feed 进一个 MLP 来预测词 i 对用的 pos 标签。
② 那么怎么将一个词映射到一个输入向量 x_i 呢?一种方法是用词向量矩阵,可以随机初始化也可以直接用预训练好的。但这个方法有覆盖有限的问题,即只能覆盖训练数据中的词或者预训练中的词。另一种方法就是用两个字级别的 RNN 来完成,即对于一个由字c1,c2,…,cm构成的词,先将每个字映射为一个嵌入向量,然后用针对字的一个前向的一个后向的 RNN 来编码词,输出可以直接替换词向量,更好的是用来和词向量拼接。不过这里主要是针对英文设计的,前向的 RNN 主要关注前缀,后向的 RNN 主要关注后缀,都能关注到大小写、连字符、词长等。
③ 模型可以总结为 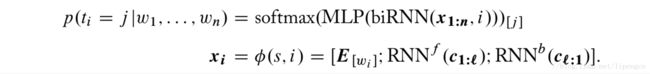
详见 
Plank2016 提出的下面这个模型效果更好。
① 上面提到的词向量构造的方法是基于字进行前向后向 RNN 获得,在 POS 标注和 NER 任务中,实践证明更有效的方式是,采用字级别的 CNN 网络。
② 上面提到的标注预测时是独立于其他标注信息的,也可以引入依赖于前面预测的标注信息。
(2)RNN-CNN 文档分类
上面提到的方法同样适用于文档分类,当然不再是把词向量输入到后续的 biRNN,而是句向量,可以是对每个词基于字级别 RNN 得到,也可以是对每个词用 CNN 得到。
Xiao and Cho 2016 提出另一种方法,为了获得能表征多字构成的单元(不一定是一个完整的词)的向量构成的短序列,针对字运用分层 CNN,然后将获得向量序列 feed 进 biRNN 和后续的分类层。
(3)弧分解的依存分析
基于弧分解的依存分析任务就是,给定一个句子,词序为 w_{1:n} ,对应 POS 序列为 t_{1:n},对每个词对 (w_i,w_j)需要分配一个表征 w_i 为 w_j 的 head 的置信度得分。可以描述为: 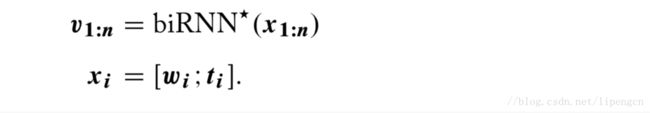
![]()
结构如下: 