爬虫分享(三):多线程爬取英雄联盟皮肤图片
爬虫分享(三):多线程爬取皮肤
1.获取英雄数据
首先进入LOL官网打开游戏资料
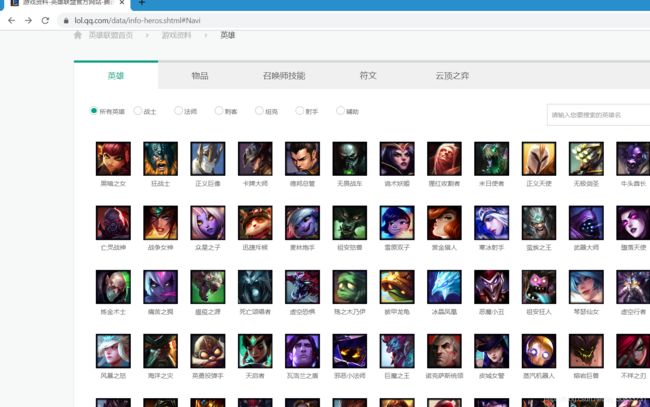
我们先尝试用该url构建一个请求
import requests
url = 'https://lol.qq.com/data/info-heros.shtml#Navi'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
r = requests.get(url,headers=headers)
r.encoding = r.apparent_encoding
with open ('./html.txt','w',encoding='utf-8') as f:
f.write(r.text)
打开txt文件搜索“安妮”却找不到信息,这是因为这些英雄的名称和图片都是通过JS渲染出来的,按F12打开开发工具,在Network栏中点击XHR,可以发现有一个hero-list.js
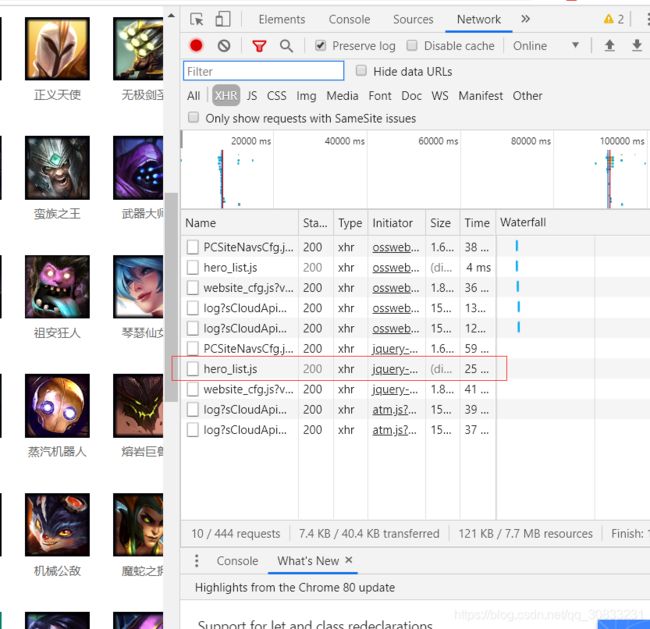
点击发现里面就是英雄的数据了,包括英雄的ID和名字等。
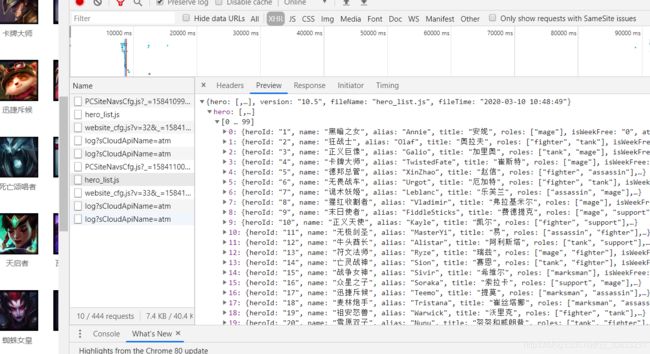
接下来,我们只需要对hero_list.js对应的url请求,直接上代码
import requests
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
r = requests.get(url,headers=headers)
r.encoding = r.apparent_encoding
print(r.text)
由此,我们便成功获取了英雄数据
2.获取皮肤信息
我们在对网页进行分析,打开安妮的页面,可以在开发者工具中发现一个1.js,依据上部分的经验,我们可以猜测1.js中包含了安妮的皮肤信息,果不其然,打开它之后就可以看到皮肤有关信息
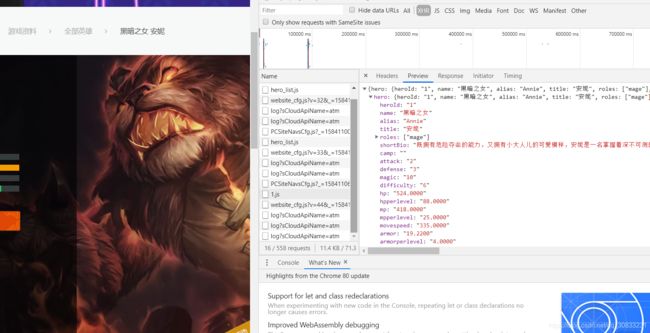
到此,我们便可以通过对信息的分析获取皮肤的名称和地址,再加入多线程,我们便可以很轻松地将这些皮肤图片保存到本地,完整代码如下:
# -*- ecoding: utf-8 -*-
# @ModuleName: lol
# @Function:
# @Author: shenfugui
# @Email: [email protected]
# @Time: 3/13/2020 9:34 PM
import requests
import json
import time
import os
import threading
from queue import Queue
def get_heros(headers, q, threads):
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
data = json.loads(r.text)
for hero in data['hero']:
id = hero['heroId']
q.put(id)
for i in range(10):
t = threading.Thread(target=get_imgs, args=(headers, q))
t.start()
threads.append(t)
q.join()
for i in range(10):
q.put(None)
for thread in threads:
thread.join()
print('finished')
def get_imgs(headers, q):
while True:
id = q.get()
if id is None:
break
try:
url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(id)
r = requests.get(url, headers=headers,timeout=10)
r.encoding = r.apparent_encoding
data = json.loads(r.text)
for skin in data['skins']:
hero_name = './' + skin['heroName']
skin_url = skin['mainImg']
skin_name = skin['name'].replace('/', '')
if not os.path.exists(hero_name):
os.mkdir(hero_name)
pic = requests.get(skin_url, headers=headers)
with open(hero_name + '/' + skin_name + '.jpg', 'wb') as f:
f.write(pic.content)
print('%s 下载成功' % (skin_name))
except requests.exceptions.ConnectionError:
time.sleep(5)
except requests.exceptions.MissingSchema:
pass
except requests.exceptions.InvalidSchema:
pass
q.task_done()
def main():
start = time.time()
q = Queue()
threads = []
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'Connection': 'close'}
get_heros(headers, q, threads)
end = time.time()
print('共用时%s s' % (end - start))
if __name__ == '__main__':
main()
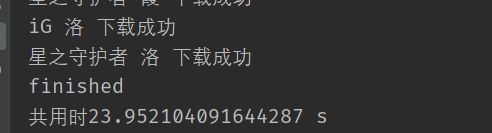
运行之后的效果图:
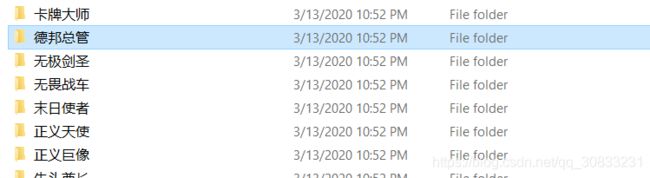
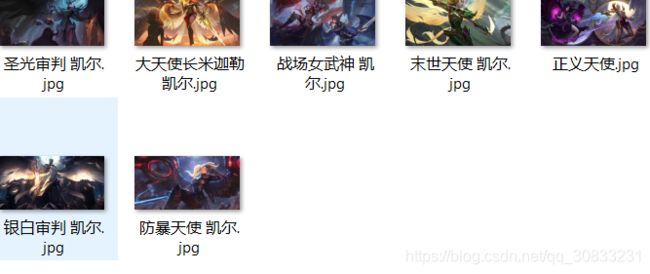
共用时24秒,效果还不错。