计算机体系结构
一. 高级语言是如何被计算机执行的?
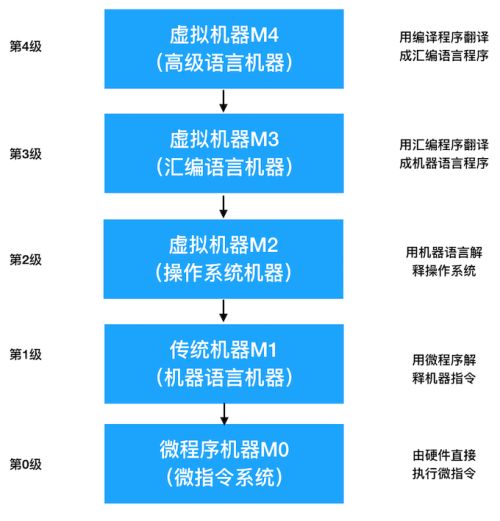
- 最初的计算机并没有微指令系统。由于M0、M1都是实际存在的,为了区分,这里分为微程序机器、传统机器;
- 将高级语言翻译成机器语言的程序叫做翻译程序,翻译程序分为编译程序与解释程序两种类型:
- 编译程序:一次性将高级语言全部翻译成机器语言;
- 解释程序:翻译一句执行一句,重新执行需要再次翻译。
二. 计算机体系结构
计算机体系结构是对计算机组成的一种抽象性描述,表明计算机应包含哪些部分,如指令集、数据类型、存储器寻址技术、I/O机理等。不同厂家的具体实现不尽相同,但是对高级语言的开发者来说,这些都是透明的,即底层实现不同不会影响到上层应用。
三. 计算机的基本组成
指令由操作码和地址码(操作数的地址)组成,用二进制表示(冯诺依曼体系结构特征之一)。
3.1 计算机硬件框图

- M⋅M:Main Memory,主存储器,也就是常说的内存,与CPU直接交换信息。此外还有辅存,如硬盘、U盘等;
- ALU:Arithmetic Logic Unit, 算数逻辑运算单元;
- CU:Contro Unit,控制单元,解释存储器中的指令,并发出各种命令执行指令。
3.2 细化的计算机组成框图
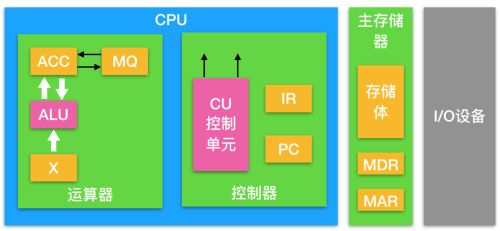
3.2.1 运算器
运算器内部包含三个寄存器和一个算数逻辑运算电路ALU。现代计算机处理器内部往往设有通用寄存器组,如ARM Cortex-A8处理器,有40个32bit的寄存器,包括32个通用寄存器,7个状态寄存器,1个PC(程序计数器)。
- ACC:Accumulator,累加器;
- MQ:Multiple-Quotient register,乘商寄存器;
- X:操作数寄存器;
3.2.2 控制器
控制器是神经中枢,指挥计算机各部件有条不紊的运行。程序运行时,控制器首先通过AB(Address Bus,地址总线)向主存发送指令读取命令,然后主存将指令存进MDR(Memory Data Register,存储器数据寄存器),再通过数据总线传输至IR(Instruction Register,指令寄存器,存放当前指令),控制器解析出该指令对应的操作码与地址码(析指),并根据地址码取出操作数,最后执行指令。
- PC:Program Counter,程序计数器,存放欲执行的指令,具备自动+1的功能,与MAR(Memory Address Register,存储器地址寄存器)有一条直接通路。
- IR:其内容来自主存的MDR,IR中的操作码(OP)被送至CU用来解析指令,地址码(AR)被送至主存的MAR用来读取操作数。
3.2.3 主存储器
主存储器也称主存或内存,由存储体、MAR、MDR、各种逻辑部件和逻辑电路等组成。存储体由许多存储单元组成,每个存储单元又包含很多存储元件。每个存储元件可以存储一位二进制数0或1,所以存储单位根据所包含存储元件个数的不同可以分为8位、16位、32位等,也就是存储字长分别为8位、16位、32位等。
每个存储单元都有自己的地址,主存的工作方式就是按照存储单元的地址实现对存储字各位的读写,而MAR、MDR则用来实现按地址访问。
- MAR:Memory Address Register,存储器地址寄存器,存放待访问的存储单元的地址。其位数对应存储单元的个数,如MAR是32位,则共有2^32=4G个存储单元。
- MDR:Memory Data Register,存储器数据寄存器,存放从存储体读出的数据或准备写入存储体的数据(可以是代码,也可以是指令,反正都是一串二进制数),其位数等于存储字长。
要想实现一个完整的读/写操作,CPU还需要给主存发送各种控制信号,如读命令、写命令、地址译码驱动信号等。
早期的指令字长、数据字长一般和存储字长相等,现代计算机的指令字长、数据字长是可变的,不必等于存储字长,以字节为单位。比如4字节的指令字长就是32bit,2字节的指令字长就是16bit。
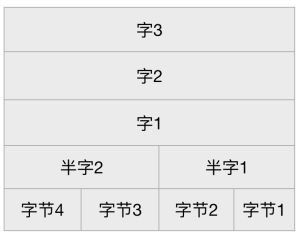
上图为32位架构的ARM存储器组织结构,其基本数据类型有:
- Byte:字节,8位;
- HalfWord:半字,16位(半字必须与2字节边界对齐);
- Word:字,32位(字必须与4字节边界对齐);
- Double World(Cortex-A支持):双字,64位(双字必须与8字节边界对齐)。
四. 计算机硬件的主要技术指标
4.1 机器字长
机器字长是指计算机进行一次整数运算所能处理的二进制数据的位数(整数运算即定点整数运算)。因为计算机中数的表示有定点数和浮点数之分,定点数又有定点整数和定点小数之分,这里所说的整数运算即定点整数运算。机器字长也就是运算器进行定点数运算的字长,即通用寄存器的位数。
主存字长一般等于机器字长,不等的情况下,一般是主存储器字长小于机器字长。例如机器字长是32位,主存储器字长可以是32位,也可以是16位。
Windows 64位操作系统是针对64位机器字长的CPU设计的,目前64位架构实现技术主要有AMD64、Intel EM64T等。
4.2 存储容量
主存容量 = 存储单元数 * 存储字长
比如,MAR是32位,则存储单元个数 = 2^32,若存储字长为8,则存储容量 = 2^32 * 8 (bit),即4G。
4.3 运算速度
单位时间内执行的指令平均条数,单位MIPS(Million Instruction Per Second)。
五. 系统总线
同一时刻只能有一个部件向总线发送信息,但是可以有多个部件接受信息,因为总线是各部件共享的。
5.1 总线分类
5.1.1 片内总线
芯片内部的连线,比如寄存器之间、寄存器与ALU之间的连线。
5.1.2 系统总线
数据总线:双向传输,其条数称为数据总线宽度。数据总线宽度与机器字长、存储字长有关。比如总线宽度是8位,指令字长位16位,那么CPU取出一条指令,就需要访问两次主存。
-
地址总线:单向传输,指出数据总线上的源数据或目的数据所在存储单元的地址。地址总线的宽度与存储单元个数有关,比如32位的地址总线,可编址按字节寻址的存储单元个数为2^32 = 4G。
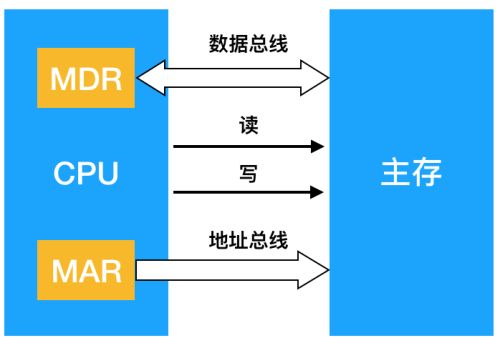 图5.1.2 主存与CPU的联系.png
图5.1.2 主存与CPU的联系.png从存储器读一个字的数据时,首先由CPU将其地址经MAR通过地址总线送至主存,然后向主存发读命令。主存接到读命令后,将对应数据读出后,经数据总线送至MDR。向存储器写一个字的数据时,CPU先将目的地址经MDR通过地址总线送至主存,并将数据送至MDR,然后向主存发写命令。主存接到写命令后,便可以将MDR中的数据经数据总线写至目的地址。
控制总线:决策总线使用权,用来发出各种控制信号。I/O设备通过控制总线向CPU发出总线请求,CPU通过控制总线向I/O设备发出读写命令。
通信总线:用于计算机系统之间或计算机系统与其它系统(如控制仪表、移动通讯等)之间通信。
六. 虚拟存储系统

在虚拟存储系统中,程序员的编程地址范围与虚拟存储器的地址空间相对应。例如机器指令地址码是24位,那么虚拟存储器的存储单元(存储字长为8)个数可达2^24 = 16M,这可能比主存实际的存储单元个数多得多。这类指令地址码称为虚拟地址或逻辑地址,主存的实际地址称为物理地址。虚拟地址到物理地址的转换由操作系统负责实现,比如Windows操作系统通过页目和页表来实现虚拟地址到物理地址的转换。若虚拟地址指向的内容在主存,则可被CPU直接使用,否则必须先传到主存,然后才能被CPU访问。
七. 结语
阅读《Android源代码情景分析》Binder进程间通信系统一章,老罗(罗升阳,原书作者)列举Google开发Binder作为IPC框架原因时说:“与传统的进程间通信机制相比,Binder进程间通信机制在进程间传输数据时,只需要执行一次拷贝操作,因此,它不仅提高了效率,而且节省了内存空间”,对“只拷贝一次”有点疑惑:“Pipe不也是只有一次吗?”(犯二了,其实是两次)
以Pipe(无名管道,用于具有亲缘关系的进程间通信,比如父子进程、兄弟进程)为例,进程A向进程B发送数据,需要先将进程A用户空间中的数据拷贝至管道(在内核空间中),然后进程B再从管道中将数据拷贝至自己的用户空间,数据确实拷贝了两次。而Binder机制下,由于虚拟进程地址空间(vm_area_struct)和虚拟内核地址空间(vm_struct)都映射到同一块物理内存空间,当Client端与Server端发送数据时,Client(作为数据发送端)先从自己的进程空间把IPC通信数据copy_from_user拷贝到内核空间,而Server端(作为数据接收端)与内核共享数据,不再需要拷贝数据,而是通过内存地址空间的偏移量,即可获悉内存地址,整个过程只发生一次内存拷贝。效率最高的当属共享内存了,无需任何拷贝即可访问,只是需要结合信号量来进行信息同步。
一不小心就钻了牛角尖,为了搞清为什么32位CPU最大寻址空间是4G和Linux每个进程独占3G用户空间的问题,把计算机组成原理又翻出来挑着看了一遍。
写文章还是挺累的,哪怕只是一篇总结(颈椎完全扛不住)。不过有第一篇,就会有第二篇。以前看过很多文章,都没有总结记录,到最后就只剩下寂寞了。
参考文献
[1] 计算机组成原理 高等教育出版社 2000-7 唐朔飞编著
[2] ARM嵌入式体系结构与接口技术 人民邮电出版社 2013-9 杨胜利 刘洪涛编著
[3] Android源代码情景分析 电子工业出版社 罗升阳编著
[4] Binder系列2—Binder Driver再探 Gityuan