关于Python爬虫之获取海量表情包+存入数据库+搭建网站通过关键字查询表情包
目标:获取海量表情包,存入数据库,然后搭建简单网站通过输入关键字获取对应的的表情包
这里我们的首先要爬取表情包的网站是这个网站:
http://www.doutula.com/photo/list/?page=0
我们先来分析一下这个网页的源代码:

源码里面可以发现我们需要的内容然后去用正则表达式获取,然后存入数据库
同时在源码最上面可以看见网页是utf-8编码的。
============================================================
注意,这里我们先说下navicat for MySQL:关于软件下载和MySQL安装之前博客说过了。
先是新建一个叫doutula的数据库
=============================================
然后在该数据库中新建一个表
===========================================
然后再在表中添加相应的id和name和imageUrl

这里要勾选上自动递增,我之前没勾选上的时候,会报错'id' doesn't have a default value
===============================================================
然后新建一个用户:

=======================
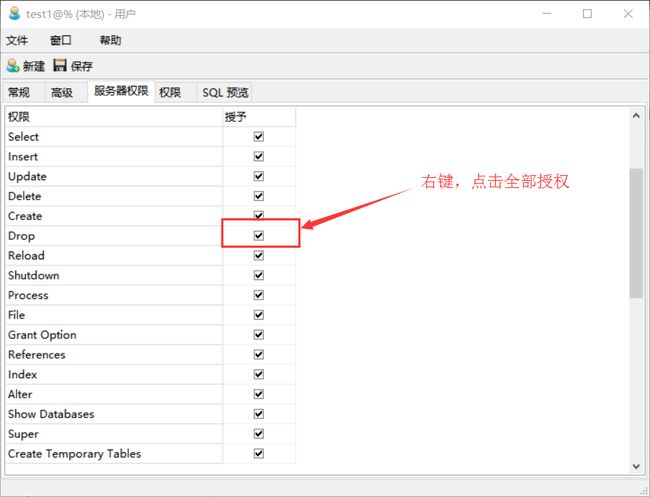
修改权限:
==============================
然后看代码吧:
#写在前面:python3.5 、win10 、navicat for MySQL、MySQL
#之前都是用的urllib.request里面的Request、urlopen方法去获取一个一个网页上的内容,今天换着用用requests模块
import requests,re,pymysql
# 这里导入的pymysql模块,如果没有安装的用pip install pymysql安装一下
#这里就是连接数据库的一个操作
db = pymysql.connect(
host = '127.0.0.1', #主机,一般没有服务器就填本机吧
port = 3306, #端口,navicat创建数据库的时候端口就是默认是3306
user = 'test1', #这里是用户名,也是之前创建的
password = '5531663', # 密码
db = 'doutula', # 这里就是你在navicat新建的数据库名
charset = 'utf8' # 写入数据库的数据都是utf8编码的,千万注意不能写为utf-8
)
cursor = db.cursor() #创建一个游标,通过游标去操作一些MySQL的语句
#下面是爬取一个网页的内容
def getImage(i):
urlBasic = 'http://www.doutula.com/photo/list/?page=' # 发现网页大概都长这模样,只是后面的数字不同
url = urlBasic + '%s'%i #得到完整的网页url
res = requests.get(url) #得到一个
html = res.text
imageListRe = 'data-original="(.*?)"\s*alt="(.*?)"' # 分析网页后写的正则表达式
imageList = re.findall(imageListRe,html) # 获取name和imageUrl
#print(imageList)
for i in imageList:
cursor.execute("insert into image(`name`,`imageUrl`) values('{}','{}')".format(i[1],i[0]))
db.commit()
for i in range(1138): # 这里查看网页后发现一共就1137页
print('正在爬取第{}页的数据'.format(i))
getImage(i)
db.close() # 不要忘记了关闭数据库连接==========================================
然后这边看一下导入数据库后的结果:

----------------------------------------------------
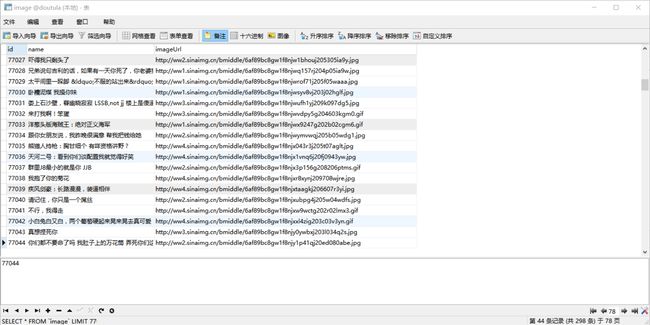
一共是八万条数据。。。
==============================================
然后就是网站方面了,写一个简单的网站,实现输入关键字得到对应的图片:
上代码:
# 我们所要达到的效果就是输入关键字然后就页面上显示相关的图片,图片我们并没有下载到本地,是直接从数据库里面调用的,所以这里也要连接数据库
from flask import Flask
from flask import render_template
from flask import request
import pymysql
app = Flask(__name__) # 关于flask的操作之前博客提到过
# 连接数据库
db = pymysql.connect(
host='127.0.0.1',
port=3306,
user='test1',
password='5531663',
db='doutula',
charset='utf8',
cursorclass=pymysql.cursors.DictCursor,#这里默认从数据库中查到的数据返回回来是列表形式,这里改为了dict形式
)
cursor = db.cursor()
@app.route('/')
def index():
return render_template('index.html') # render_template模板能返回一个网页,而网页得存在新创建的templates文件夹里面才可以
@app.route('/search')
def search():
kw = request.args.get('kw')
count = request.args.get('count')
cursor.execute("select * from image where `name` like '%{}%' ".format(kw))
# 这里是一个模糊匹配,就是匹配和你输入的关键字类似的name,关键字是要用'%{}%'代替,用format传入
data = cursor.fetchmany(int(count)) # 这里fetchmany就是匹配count条数据库中的数据
return render_template('index.html',images = data)
app.run(debug = True)
然后里面的index.html如下:
斗图网站
{% for i in images %}
 {% endfor %}
# {{}}是放变量 {%%}是放方法
{% endfor %}
# {{}}是放变量 {%%}是放方法
所形成的效果如下:

==========================================
然后我们试着搜索一下关键字:‘骚’
完成。效果还不错。。。。。。。。。。。。。。。。。。。。。
以上,如有不足,欢迎指出。Thanks~!
===========================
最后补充一下:
这样运行后只能在本机上访问,
如果改为:
app.run(host = '0.0.0.0' ,port = 5000, debug = 'True')
这样就可以使得同一个局域网内的电脑、手机都可以访问了,但是要现获得本机IP地址,
命令行里面输入ipconfig查看本机ip地址,然后在浏览器里面输入 IP地址:5000便可正常访问了
2017.11.19 19:56.................................
=======================================