Intel汇编程序设计-整数算术指令(中)
7.3 移位和循环移位的应用
7.3.1 多双字移位
要对扩展精度整数(长整数)进行移位操作,可把它划分为字节数组、字数组或双字数组,然后再对该数组进行移位操作。在内存中存储数字时通常采用的方式是最低字节在最低的地址位置上(小尾顺序)。下面的步骤以一个双字节数组为例,说明了如何把这样的一个数组右移移位:
ArraySize = 3
.data
array DWORD ArraySize DUP(?)
1.把ESI的值设置为array的偏移。
2.把最高位置[ESI+8]处的双字右移一位,最低位复制到进位标志中。
3.把[ESI+4]处的值右移一位,最高位自动以进位标志的值填充,最低位复制到进位标志中。
4.把[ESI+0]处的双字右移一位,其最高位自动以进位标志填充,其最低位复制到进位标志中。
下图显示了数组的内容及使用ESI间接引用的表示:

实现程序MultiShf.asm的代码如下,程序中使用的是RCR指令,也可以使用SHRD指令:
.data
ArraySize = 3
array DWORD ArraySize DUP(99999999h) ;1001 1001...
.code
mov esi ,0
shr array[esi + 8]
rcr array[esi + 4]
rcr array[esi],1
...蛋疼,上面的那个我的卡了好几分钟才明白,我靠,一开始理解错了。
7.3.2 二进制乘法
IA-32的二进制乘法指令(MUL和IMUL)相对于其他机器指令来说是比较缓慢的。汇编语言程序员通常会寻找更好的进行二进制乘法的方法,有时候移移位操作的优越性是显而易见的。我们已经知道,在乘数是2的次幂的情况下,用SHL指令进行无符号数的乘法是相当高效的。无符号整数左移n位就相当于乘以2的n次幂。
例如,为了计算EAX乘以32 ,就可以把36分解成(2的5cifang+2的2次方)
,然后用乘法分配率进行运算:
EAX * 32 = EAX * (32 + 4)
= (EAX * 32) + (EAX * 4)
下图描述了123*32的乘法过程,积为4428:

乘数36的位2和位5是1,这些恰好是例子中的移位次数。
.code
mov eax , 123
mov ebx , eax
shl eax , 5
shl ebx , 2
add eax , ebx
7.3.3 显示二进制数的数据位
一类常见的编程任务是要求把二进制整数转换成ASCII二进制字符串以进行显示。SHL指令这时就很有用了,因为SHL指令在每次操作数左移的时候,都会把最高位复制到进位标志中,下面的BinToAsc过程是一个简单的实现。
;---------------------------------------------------------------
BinToAsc PROC
;
;Converts 32-bit binary integer to ASCII binary.
;Receives:EAX = binary integer,ESIpoints to buffer
;Returns: buffer filled with ASCII binary digits
;---------------------------------------------------------------
push ecx
push esi
mov ecx ,32 ;EAX中数据位的数目
L1: shl eax ,1 ;左移高位至进位标志中
mov BYTE PRT[esi] ,’0’ ;选择0作为默认数字
jnc L2 ;如果无进位,跳转到L2
mov BYTE PTR[esi] ,’1’;否则1送缓冲区
L2: inc esi ;下一个缓冲区位置
loop L1 ;继续循环,另外一位左移
pop esi
pop ecx
ret
BinToAsc ENDP
7.4 乘法和除法指令
MUL和IMUL指令分别进行有符号整数和无符号整数的乘法操作。DIV指令进行无符号整数的除法操作,IDIV进行有符号整数的除法操作。
7.4.1 MUL指令
MUL(无符号乘法)指令有三种格式:第一种将8位操作数与AL相乘;第二种将16位的操作数与AX相乘;第三种将32位的操作数与EAX相乘。乘数和被乘数大小必须相同,乘积的尺寸是乘数/被乘数大小的两倍。三种格式都既接受寄存器操作数,也接收内存操作数,但是不接受立即数操作数。
MUL r/m8
MUL r/m16
MUL r/m32
指令中唯一的一个操作数是乘数。表7.2根据乘数大小的不同列出了被乘数和乘积,由于目的操作数(乘积)是乘数/被乘数大小的两倍,因此不会发生溢出。如果积的高半部分不为0,就设置进位和溢出标志。由于进位标志通常用于服务号算术运算符,因此我们主要关注该标志。例如当AX与16位操作数相乘的时候,积存储在DX:AX中。如果DX不为0,则进位标志置位。

在执行完MUL指令后要检查进位标志的一个理由:有时我们需要知道乘积的高半部分是否可被安全的忽略。
MUL指令的例子
下面的语句把AL和BL相乘,积在AX中,进位标志清零(CF=0),因为AH(乘积的高半部分)等于0:
mov al ,5h
mov bl ,10h
mul bl ;AX =50h ,CF = 0
下面的语句将16位数2000h和100h相乘,CF=1,因为乘积的高半部分DX不等于0;
.data
val1 WORD 2000h
val2 WORD 0100h
.code
mov ax ,val1 ;AX = 2000h
mul val2 ;DX:AX = 00200000h ,CF = 1
下面的语句将32位数12345h和1000h相乘得到一个64位的积,由EDX=0知CF=0;
mov eax ,12345h
mov ebx ,1000h ;EDX:EAX = 000012345000h ,CF = 0
mul ebx
7.4.2 IMUL指令
IMUL(有符号乘法)指令执行有符号整数的乘法运算,保留了成绩的符号位。IMUL指令在IA-32指令集中由三种格式:单操作数、双操作数和三操作数。在单操作数格式中,乘数和被乘数尺寸大小相同,乘积的大小是乘数/被乘数大小的两倍(8086/8088处理器只支持这种格式)。
单操作数格式:单操作数格式把乘积存储在累加器(AX,DX:AX,EDX:EAX)中:
IMUL r/m8
IMUL r/m16
IMUL r/m32
和MUL指令一样,IMUL指令的单操作数格式中乘积的尺寸大小是的溢出不可能发生。如果乘积的高半部分不是低半部分的符号扩展,进位标志和溢出标志位,可以用该特点确定乘积的高半部分是否可以忽略。
双操作数格式:双操作数格式中成绩存储在第一个操作数中,第一个操作数必须是寄存器,第二个操作数可以是寄存器、内存书或立即数,下面是16位操作数的格式:
IMUL r16,r/m16
IMUL r16 ,imm8
IMUL r16 ,imm16
下面是32位操作数的格式,乘数必须是一个32位的寄存器、32位的内存操作数或立即数(8位或者32位):
IMUL r32 ,r/m32
IMUL r32, imm8
IMUL r32 ,imm32
双操作数格式会根据目的操作数的大小剪裁乘积。如果有效位丢失,则溢出标志和进位标志置位。使用双操作数格式时,无比在执行完IMUL操作后检查这些标志的值
三操作数格式:三操作数格式把乘积存储在第一个操作数中,一个16位的寄存器可被一个8位或16位的立即数乘:
IMUL r16 ,r/m16 ,imm8
IMUL r16 ,r/m16 ,imm16
一个32位的寄存器可被一个8位或32位的立即数乘:
IMUL r32 ,r/m32 ,imm8
IMUL r32 ,r/m32 ,imm32
如果有效位丢失,则溢出标志和进位标志置位。使用三操作数格式时,务必在执行完IMUL操作后检查这些标志的值。
无符号乘法:双操作数和三操作数格式的IMUL指令也可用于进行无符号乘法。不过这样做有一个缺陷:进位标志和溢出标志不能用来指示乘积的高半部分是否为0.
7.4.3 乘法操作的基准(性能)测试
比较MUL,IMUL和移位做乘法指令的速度:
INCLUDE Irvine32.inc
.data
LOOP_COUNT = 0FFFFFFFFh
.data
intval DWORD 5
startTime DWORD ?
.code
main PROC
call GetMseconds
mov startTime ,eax
mov eax ,intval
call mult_by_MUL
call GetMseconds
sub eax ,startTime
call WriteDec
main ENDP
mult_by_shifting PROC
;
;EAX乘以36,使用SHL指令,重复LOOP_COUNT次
mov ecx ,LOOP_COUNT
L1: push eax
mov ebx ,eax
shl eax ,5
shl ebx ,2
add eax ,ebx
pop eax
loop L1
ret
mult_by_shifting ENDP
mult_by_MUL PROC
;
;EAX乘以36,使用SHL指令,重复LOOP_COUNT次
mov ecx ,LOOP_COUNT
L1 :
push eax
mov ebx ,36
mul ebx
pop eax
loop L1
ret
mult_by_MUL ENDP
END main
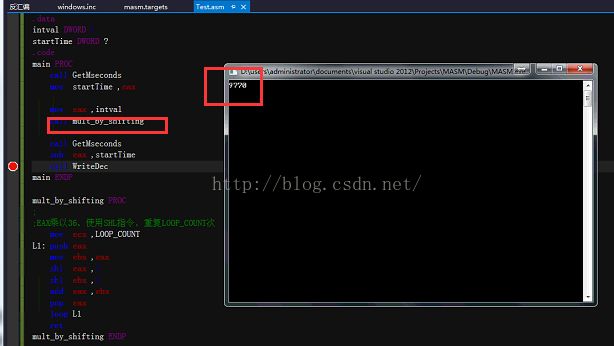
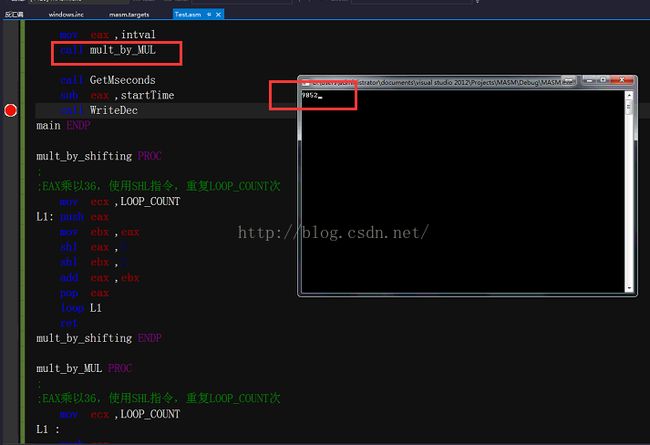
按照书中作者的测试结果是,移位乘法 用时6.078s而mul则用了20.718s,但是我的测试结果是两个差不多,但是这个并不和作者说的事情冲突,因为我目前使用的换将是vs2012+masm vs会对代码进行优化处理。
7.4.4 DIV指令
DIV(无符号除法)指令执行8位、16位和32位无符号整数的除法运算。指令中唯一的一个寄存器或内存操作数是除数,DIV的指令格式是:
DIV r/m8
DIV r/m16
DIV r/m32
下表显示了被除数、除数、商以及余数之间的关系。

DIV例子
下面的指令执行8位无符号数的除法(83h/2),上市401,余数是1:
mov ax ,0083h ;被除数
mov bl ,2 ;除数
div bl ;AL = 41h ,AH = 01h
执行16位无符号除法(8003h/100h),商是80h,余数是3。DX中存放的是被除数的高位,因此在执行DIV指令之前DX必须首先清零:
mov dx ,0 ;清除被除数的高位
mov ax ,8003h ;被除数的地位
mov cx ,100h ;除数
div cx ;AX = 0080h ,DX = 003h
执行32位无符号除法,指令使用内存操作数作为除数:
.data
dividend QWORD 0000000800300020h
divisor DWORD 00000100h
.code
mov edx ,DWORD PTR dividend + 4 ;高双子
mov eax ,DWORD PTR dividend ;低双字
div divisor ;EAX = 08003000h ,EDX = 00000020h
7.4.5 有符号整数除法
有符号整数除法和无符号几乎完全相同,唯一不同:在进行除法操作之前,隐含的被除数北徐进行符号扩展。
符号扩展指令(CBW,CWD,CDQ)
有符号除法指令中的被除数在进行除法操作之前通常要进行符号扩展。Intel提供了三条符号扩展指令:CBW CWD CDQ。CBW指令(字节符号扩展至字)扩展AL的符号位值AH中,保留了数字的符号。在下面的例子中(AL中的)9Bh和(AX中的)FF9Bf都等于-101:
.data
byteVal SBYTE -101 ;9Bh
.code
mov al ,byteVal ;AL = 9Bh
cbw ;AX = FF9Bh
同理 CWD(字符号扩展至双字)指令扩展AX的符号位至DX中:
...
CDQ(双子字节扩展至8字节)指令扩展EAX的符号位至EDX中:
...
IDIV指令
IDIV(有符号除法)指令进行有符号整数的除法运算,使用的操作数格式与DIV指令相同。在进行8位除法之前,被除数(AX)必须进行符号扩展,余数的符号和被除数总是相同。
例子:
.data
byteVal SBYTE -48
.code
mov al ,byteVal ;被除数
cbw ;扩展AL至AH
mov bl ,5 ;除数
idiv bl ;AL = -9 ,AH = -3
.data
wordVal SWORD -5000
.code
mov ax ,wordVal ;被除数的低半部分
cwd ;扩展AX值DX
mov bx ,+256 ;除数
idiv bx ;商AX = -19 余数DX = -136
.data
dwordVal SDWORD +50000
.code
mov eax ,dwordVal ;被除数的低半部分
cdq ;扩展EAX至EDX
mov ebx ,-256 ;除数
idiv ebx ;EAX = -195 余数 EDX = +80 (注意此时余数符号)
在执行DIV和IDIV指令后所有的算术状态标志都是不确定的。
除法溢出
在除法操作产生的上太大,目的操作数无法容纳的时候,就会导致除法溢出,这会导致CPU触发一个中断,当前程序将被终止。例如下面:
mov ax ,1000h
mov bl ,10h
div bl ;AL不能容纳100h

7.4.6 算术表达式的实现
var4 = (var1 + var2) * var3
用汇编实现下:
mov eax ,var1
add eax ,var2
mul var3 ;EAX = EAX * var3
jc tooBig ;无符号溢出?
mov var4 ,eax
jmp next
tooBig: ;显示错误信息
然后看下用C++编译之后 vs反汇编会是什么样?
