scrapy爬虫实战
1、打开终端,在命令行下切换到要建立项目的文件夹:

使用scrapy startproject [项目名],例如:scrapy startproject qsbk。这时就会在相应文件夹下生成scrapy项目:

然后用pycharm打开。scrapy.cfg是整个项目的配置文件。items.py存储的是所有爬取数据的模型。middlewares.py是中间件。pipelines.py用于处理爬取到的数据。
2、进入项目文件夹,比如:cd qsbk,然后使用scrapy genspider 项目名 域名新建一个爬虫,例如:scrapy genspider qsbk_spider 'qiushibaike.com':

然后就会多出一个文件:
它会自动给你生成这样一个类。
3、将settings.py中的ROBOTSTXT_OBEY设置为False,因为如果为True的话就有可能抓取不到数据。然后加上头部信息:

4、看到QsbkSpiderSpider这个类:
class QsbkSpiderSpider(scrapy.Spider):
name = "qsbk_spider"
allowed_domains = ["qiushibaike.com"]
start_urls = ['http://qiushibaike.com/']
def parse(self, response):
pass它必须继承自scrapy.Spider类,然后实现三个属性:爬虫的名字、允许的域名、开始的url。
5、对要爬取的网站做一个分析:
我们发现它是分页的形式,并且每一页只有一个数字不同:https://www.qiushibaike.com/8hr/page/1/,因此把url替换为这个url。
然后打印一下response:
def parse(self, response):
print('*'*40)
print(response)
print('*'*40)接着使用命令来运行一下:
点击show in Explorer进入到项目当中:



然后在此处打开命令行,输入命令scrapy crawl qsbk_spider,crawl就是爬的意思。如果出现错误,则输入:worlon crawler-env。然后就爬取到了一些信息:

再打印一下它的类型:

然后导入这个类型:from scrapy.http.response.html import HtmlResponse。将鼠标放在这段文字上面按一下Ctrl+B跳到这里:

然后发现它继承自TextResponse,然后再进去看一下:

可以获取它的encoding和文本。然后提取数据的方法有Xpath和CSS:

6、分析如何拿到其中的每一个段子
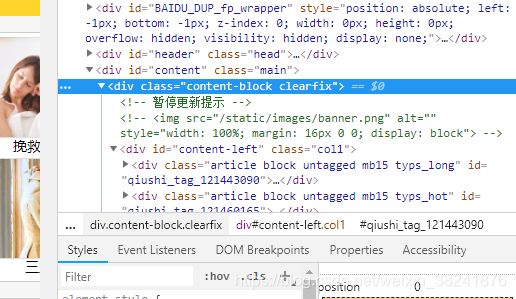
我们发现所有的段子都在这个div下,然后其中的每一个子div就代表一个段子。所以现在只需要获取这个div下的所有直接子div就可以获取所有的段子。然后我们打印一下它的类型:
print('='*40)
print(type(response.xpath('//div[@class="content-block clearfix"]')))
print('=' * 40) 
由于每次都需要再命令行中去执行,因此我们新建一个python文件start.py:
from scrapy import cmdline
cmdline.execute('scrapy crawl qsbk_spider'.split())
# cmdline.execute(['scrapy','crawl','qsbk_spider'])qsbk_spider.py的内容如下:# -*- coding: utf-8 -*-
import scrapy
from scrapy.http.response.html import HtmlResponse
class QsbkSpiderSpider(scrapy.Spider):
name = "qsbk_spider"
allowed_domains = ["qiushibaike.com"]
start_urls = ['https://www.qiushibaike.com/text/page/1/']
def parse(self, response):
duanzidivs = response.xpath('//div[@id="content-left"]/div')
for duanzidiv in duanzidivs:
author = duanzidiv.xpath(".//h2/text()").get().strip()#在当前标签下寻找h2标签,并获取它的文本并用strip()方法去掉前后的空白字符
content = duanzidiv.xpath('.//div[@class="content"]//text()').getall()#因为文本信息在多个标签下面,所以用//表示查找所有的
content = ''.join(content).strip()#由于返回的是一个列表,因此用这种方式将列表中的所有信息连接起来形成一个字符串
print(content)接下来要做到事情就是将数据保存下来,比如json文件或者csv文件,保存的工作就需要交给pipline去处理,在qsbk_spider.py文件中将数据移交给pipline:
duanzi = {'作者':author,'段子':content}
#将字典数据移交给pipline
yield duanzi#把一个普通的函数变成一个生成器,这样一来,在遍历这个生成器的时候就会把数据一个一个的返回然后来到pipline去写存储的代码,这个文件需要写三个方法:
class QsbkPipeline(object):
#当爬虫打开以后就会调用这个函数
def open_spider(self,spider):
pass
#在爬虫运行过程中如果传递了一些item进来就调用这个函数
def process_item(self, item, spider):
return item
#当爬虫完成任务以后无事可干是就执行这个函数
def close_spider(self,spider):
pass最终的pipline如下:
import csv
import json
class QsbkPipeline(object):
def __init__(self):
# self.fp = open('duanzi.csv','w',encoding='utf-8')
self.fp = open('duanzi.json', 'w', encoding='utf-8')
# fieldname = ['作者', '段子']
# self.writer = csv.DictWriter(self.fp, fieldnames=fieldname)
# self.writer.writeheader()
#当爬虫打开以后就会调用这个函数
def open_spider(self,spider):
print('爬虫开始了...')
#在爬虫运行过程中如果传递了一些item进来就调用这个函数
def process_item(self, item, spider):
item_json = json.dumps(item,ensure_ascii=False)
self.fp.write(item_json+'\n')
# self.writer.writerow(item)
return item
#当爬虫完成任务以后无事可干是就执行这个函数
def close_spider(self,spider):
self.fp.close()
print('爬虫结束了...')现在这个pipline还不能运行,如果想让它运行就要来到settings.py下面找到:ITEM_PIPELINES并取消注释:
ITEM_PIPELINES = {
'qsbk.pipelines.QsbkPipeline': 300,
}到目前为止爬取一个页面并经数据保存的代码就结束了,接下来我们再来优化一下,我们知道返回的数据是一个字典,但是scrapy建议我们针对一些这样的item,这些存储项,它已经建立好了这样的存储模型items.py,这个模型里面就有这样一些字段,比如说我们要存储这个段子的作者和内容就把这两个东西写到这里面来,在以后传入数据的时候就不要传入字典了,而是使用这里定义好的item:
class QsbkItem(scrapy.Item):
author = scrapy.Field()
content = scrapy.Field()再回到qsbk_spider.py导入:from qsbk.items import QsbkItem:
def parse(self, response):
duanzidivs = response.xpath('//div[@id="content-left"]/div')
for duanzidiv in duanzidivs:
author = duanzidiv.xpath(".//h2/text()").get().strip()#在当前标签下寻找h2标签,并获取它的文本并用strip()方法去掉前后的空白字符
content = duanzidiv.xpath('.//div[@class="content"]//text()').getall()#因为文本信息在多个标签下面,所以用//表示查找所有的
content = ''.join(content).strip()#由于返回的是一个列表,因此用这种方式将列表中的所有信息连接起来形成一个字符串
item = QsbkItem(author=author,content=content)
#将字典数据移交给pipline
yield item#把一个普通的函数变成一个生成器,这样一来,在遍历这个生成器的时候就会把数据一个一个的返回这样的好处就是可以固定需要传入哪些参数,第二个好处就是不需要字典,只需要用这个类。但现在还是有一个问题,就是在pipline这个地方,它得到的是一个QsbkItem数据类型,而这个数据类型是不能直接被json所dump的,需要先转换为一个字典:
item_json = json.dumps(dict(item),ensure_ascii=False)接下来再对数据存储这块进行优化一下,在存储的时候我们是导入json模块,这样会比较乱,需要先转换为字典才能写进去,其实scrapy为我们提供了一个导出器,一个导出json的东西:
from scrapy.exporters import JsonItemExporter#导入导出json的导出器
class QsbkPipeline(object):
def __init__(self):
self.fp = open('duanzi.json', 'wb')#导出器写入数据的时候是以二进制的方式写入的
self.exporter = JsonItemExporter(self.fp,ensure_ascii=False,encoding='utf-8')
self.exporter.start_exporting()#开始导入
#当爬虫打开以后就会调用这个函数
def open_spider(self,spider):
print('爬虫开始了...')
#在爬虫运行过程中如果传递了一些item进来就调用这个函数
def process_item(self, item, spider):
self.exporter.export_item(item)#直接将item扔进去而不需要转换为字典
return item
#当爬虫完成任务以后无事可干是就执行这个函数
def close_spider(self,spider):
self.exporter.finish_exporting()#完成导入
self.fp.close()
print('爬虫结束了...')运行结果:

发现所有数据是存放在一个列表中的,为了避免这个问题,可以换一种方式,导入JsonLinesItemExporter,而且开始结束都不需要了:
from scrapy.exporters import JsonLinesItemExporter
class QsbkPipeline(object):
def __init__(self):
self.fp = open('duanzi.json', 'wb')#导出器写入数据的时候是以二进制的方式写入的
self.exporter = JsonLinesItemExporter(self.fp,ensure_ascii=False,encoding='utf-8')
#当爬虫打开以后就会调用这个函数
def open_spider(self,spider):
print('爬虫开始了...')
#在爬虫运行过程中如果传递了一些item进来就调用这个函数
def process_item(self, item, spider):
self.exporter.export_item(item)#直接将item扔进去而不需要转换为字典
return item
#当爬虫完成任务以后无事可干是就执行这个函数
def close_spider(self,spider):
self.fp.close()
print('爬虫结束了...')除此以外还有CsvItemExporter、XmlItemExporter等。
到目前为止爬取一个页面就写完了,接下来看一下如何爬取所有页面的数据.
首先我们需要获取下一页的链接:

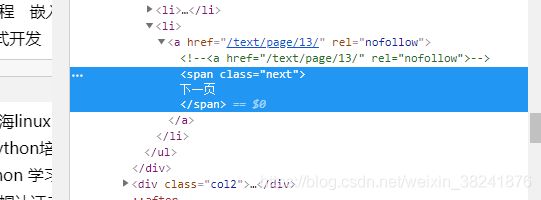
发现它在class="pagination"的ul标签下的最后一个li标签下,但有个问题是如果是到了最后一页,就没有下一页了,因此应该做一个区分,首先应该取到最后一个li标签:
class QsbkSpiderSpider(scrapy.Spider):
name = "qsbk_spider"
allowed_domains = ["qiushibaike.com"]
start_urls = ['https://www.qiushibaike.com/text/page/1/']
def parse(self, response):
duanzidivs = response.xpath('//div[@id="content-left"]/div')
based_domain = 'https://www.qiushibaike.com'
for duanzidiv in duanzidivs:
author = duanzidiv.xpath(".//h2/text()").get().strip()#在当前标签下寻找h2标签,并获取它的文本并用strip()方法去掉前后的空白字符
content = duanzidiv.xpath('.//div[@class="content"]//text()').getall()#因为文本信息在多个标签下面,所以用//表示查找所有的
content = ''.join(content).strip()#由于返回的是一个列表,因此用这种方式将列表中的所有信息连接起来形成一个字符串
item = QsbkItem(author=author,content=content)
#将字典数据移交给pipline
yield item#把一个普通的函数变成一个生成器,这样一来,在遍历这个生成器的时候就会把数据一个一个的返回
next_url = response.xpath('//ul[@class="pagination"]/li[last()]/a/@href').get()#找到下一页的url
if not next_url:
return
else:
yield scrapy.Request(based_domain+next_url,callback=self.parse)#再次执行parse方法为了不让服务器识别这是一个爬虫或者将服务器弄垮了,因此在settings.py中将DOWNLOAD_DELAY = 1。