Scrapy爬虫(五):有限爬取深度实例
Scrapy爬虫(五):有限爬取深度实例
- Scrapy爬虫五有限爬取深度实例
- 豆瓣乐评分析
- 爬虫爬取策略
- 创建项目
- 运行爬虫
该章节将实现爬取豆瓣某个音乐下所有乐评的scrapy爬虫。
豆瓣乐评分析
豆瓣音乐是国内音乐资料及评论网站,现在我们有个需求就是爬取豆瓣音乐下所有的音乐评论(乐评),但是乐评属于音乐介绍下的子菜单,那么如何来爬取这些乐评呢?咱们先不急,先看看豆瓣乐评的结构。
以周杰伦的叶惠美为例https://music.douban.com/subject/1406522/

这个是页面上面的部分,鼠标往下滚动可以看到乐评
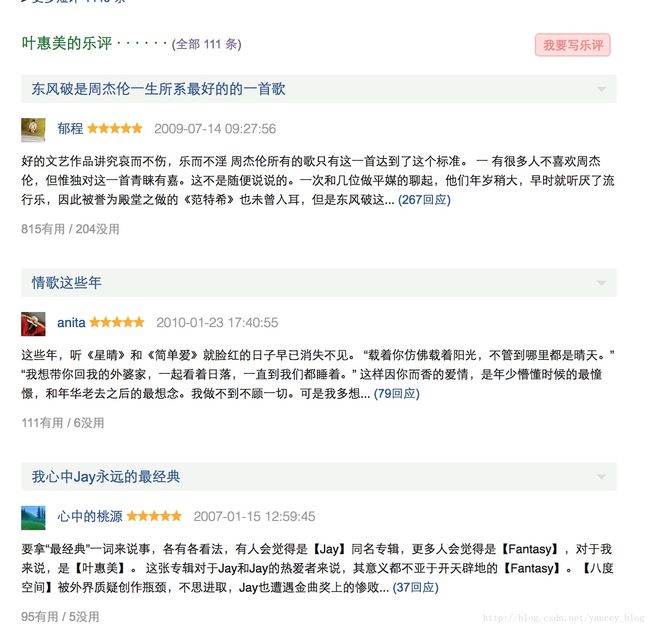
可以看到叶惠美下有111条长评论,那么,我们现在如何在只知道叶惠美这首歌url的情况下,爬取下面所有的乐评呢,下面我会回答这个问题。
爬虫爬取策略
我了解到有这么几种策略,具体的可以参看wawlian的博客
1.深度优先遍历策略
2.宽度优先遍历策略
3.反向链接数策略
4.Partial PageRank策略
5.OPIC策略策略
6.大站优先策略
本处爬取乐评可以采用深度优先遍历的策略,因为按我们正则表达式捕获同规则下的url,音乐页面还有其他音乐的链接,那么爬虫就会跑偏,爬取乐评的时候可能会先去爬取其他音乐的乐评。如果为爬虫设置深度,爬虫将不会爬取更深的url,当爬完乐评后会返回到下一个音乐url,继续爬取。
scrapy中,我们在settings.py设置深度使用DEPTH_LIMIT,例如:DEPTH_LIMIT = 5,该深度是相对于初始请求url的深度。
经分析,可以得出豆瓣音乐乐评相对于起始音乐url的深度为4,那么我们在settings.py设置DEPTH_LIMIT = 4
创建项目
使用命令scrapy startproject douban
MACBOOK:~ yancey$ scrapy startproject douban
New Scrapy project 'douban', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/yancey/douban
You can start your first spider with:
cd douban
scrapy genspider example example.com使用pycharm打开douban项目
在settings.py中设置DEPTH_LIMIT = 4
BOT_NAME = 'douban'
SPIDER_MODULES = ['douban.spiders']
NEWSPIDER_MODULE = 'douban.spiders'
DEPTH_LIMIT = 4
DOWNLOAD_DELAY = 2
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36'
ROBOTSTXT_OBEY = True豆瓣有反爬虫机制,因此设置延时DOWNLOAD_DELAY,及用户代理USER_AGENT也是必要的,在google浏览器输入chrome://version/可以得到用户代理USER_AGENT。
- 修改items.py
from scrapy import Item, Field
# 音乐
class MusicItem(Item):
music_name = Field()
music_alias = Field()
music_singer = Field()
music_time = Field()
music_rating = Field()
music_votes = Field()
music_tags = Field()
music_url = Field()
# 乐评
class MusicReviewItem(Item):
review_title = Field()
review_content = Field()
review_author = Field()
review_music = Field()
review_time = Field()
review_url = Field()- 新写一个爬虫
# coding:utf-8
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from douban.items import MusicItem, MusicReviewItem
from scrapy import log
import re
class ReviewSpider(CrawlSpider):
name = 'review'
allowed_domains = ['music.douban.com']
start_urls = ['https://music.douban.com/subject/1406522/']
rules = (
Rule(LinkExtractor(allow=r"/subject/\d+/reviews$")),
Rule(LinkExtractor(allow=r"/subject/\d+/reviews\?sort=time$")),
Rule(LinkExtractor(allow=r"/subject/\d+/reviews\?sort=time\&start=\d+$")),
Rule(LinkExtractor(allow=r"/review/\d+/$"), callback="parse_review", follow=True),
)
def parse_review(self, response):
try:
item = MusicReviewItem()
item['review_title'] = "".join(response.xpath('//*[@property="v:summary"]/text()').extract())
content = "".join(
response.xpath('//*[@id="link-report"]/div[@property="v:description"]/text()').extract())
item['review_content'] = content.lstrip().rstrip().replace("\n", " ")
item['review_author'] = "".join(response.xpath('//*[@property = "v:reviewer"]/text()').extract())
item['review_music'] = "".join(response.xpath('//*[@class="main-hd"]/a[2]/text()').extract())
item['review_time'] = "".join(response.xpath('//*[@class="main-hd"]/p/text()').extract())
item['review_url'] = response.url
yield item
except Exception as error:
log(error)
- 新建run.py
# coding:utf-8
from scrapy import cmdline
cmdline.execute("scrapy crawl review -o review.json".split())scrapy crawl review -o review.json 命令意思是,运行review爬虫并且将结果输出到revie.json文件中
运行爬虫
在pycharm中运行run.py,结果如下:
... ...
2016-12-27 11:15:52 [scrapy] DEBUG: Scraped from <200 https://music.douban.com/review/7948957/>
{'review_author': '真实的螃蟹',
'review_content': '作为90后,第一次听Jay的歌就是从这一张专辑开始,那时候都是听盗版磁带。',
'review_music': '叶惠美',
'review_time': '',
'review_title': '从叶惠美开始',
'review_url': 'https://music.douban.com/review/7948957/'}
2016-12-27 11:15:52 [scrapy] DEBUG: Scraped from <200 https://music.douban.com/review/7844264/>
{'review_author': 'Flowertree',
'review_content': '从上周清明放假开始,上海的雨就一直恹恹地下个不停,像在情局里走不出的娇弱女生。',
'review_music': '叶惠美',
'review_time': '',
'review_title': '是雨天。',
'review_url': 'https://music.douban.com/review/7844264/'}
2016-12-27 11:15:52 [scrapy] INFO: Closing spider (finished)
2016-12-27 11:15:52 [scrapy] INFO: Stored json feed (111 items) in: review.json
2016-12-27 11:15:52 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 55633,
'downloader/request_count': 126,
'downloader/request_method_count/GET': 126,
'downloader/response_bytes': 1111810,
'downloader/response_count': 126,
'downloader/response_status_count/200': 123,
'downloader/response_status_count/301': 3,
'dupefilter/filtered': 220,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2016, 12, 27, 3, 15, 52, 612227),
'item_scraped_count': 111,
'log_count/DEBUG': 544,
'log_count/INFO': 8,
'request_depth_max': 4,
'response_received_count': 123,
'scheduler/dequeued': 123,
'scheduler/dequeued/memory': 123,
'scheduler/enqueued': 123,
'scheduler/enqueued/memory': 123,
'start_time': datetime.datetime(2016, 12, 27, 3, 15, 44, 243222)}
2016-12-27 11:15:52 [scrapy] INFO: Spider closed (finished)
Process finished with exit code 0运行结果中 ‘item_scraped_count’: 111 可以知道已经将111条乐评全部爬下来了,也可以打开review.json文件,也是111条item。
github地址
- 专题概要
- 爬虫简介
- scrapy架构及原理
- imdb.cn爬虫实例
- 有限爬取深度实例
- 多个爬虫组合实例
- 爬虫数据存储实例
- 中间件的使用实例
- scrapy的调试技巧
- 爬虫总结以及扩展