scrapy爬虫实战
scrapy爬虫实战
- Scrapy 简介
-
- 主要特性
- 示例代码
- 安装scrapy,并创建项目
- 运行单个脚本
-
- 代码示例
-
- 配置
-
- item
- setting
- 爬虫脚本
- 代码解析
-
- xpath基本语法:
- 路径表达式示例:
- 通配符和多路径:
- 函数:
- 示例:
- 批量运行
- 附录1,持久化存入数据库
- 附录2,如何在本地启动数据库
Scrapy 简介
Scrapy 是一个强大的开源网络爬虫框架,用于从网站上提取数据。它以可扩展性和灵活性为特点,被广泛应用于数据挖掘、信息处理和历史数据抓取等领域。官网链接(外)
主要特性
-
模块化结构:Scrapy 的设计采用了模块化结构,包括引擎、调度器、下载器、爬虫和管道等组件。这使得用户能够根据需要选择性地使用或扩展不同的功能。
-
选择器:Scrapy 提供了灵活强大的选择器,可以通过 CSS 或 XPath 表达式轻松地提取网页中的数据。
-
中间件支持:用户可以通过中间件自定义处理请求和响应,例如修改请求头、实现代理、或者处理异常情况。
-
自动限速:Scrapy 具备自动限速功能,避免对目标网站造成过大的负担,同时支持自定义的下载延迟。
-
并发控制:支持异步处理和并发请求,提高爬取效率。
-
扩展性:Scrapy 提供了丰富的扩展接口,用户可以通过编写扩展插件实现定制化的功能。
-
数据存储:通过管道(Pipeline)机制,Scrapy 支持将抓取到的数据存储到多种格式,如 JSON、CSV、数据库等。
-
用户友好的命令行工具:Scrapy 提供了一套直观易用的命令行工具,方便用户创建、运行和管理爬虫项目。
示例代码
import scrapy
class MySpider(scrapy.Spider):
name = 'my_spider' # 爬虫名字,后续是根据这个名字运行相关代码,而不是类名
start_urls = ['http://example.com'] # 爬虫的入口网站
def parse(self, response):
# 使用选择器提取数据
title = response.css('h1::text').get()
body = response.css('p::text').get()
# 返回抓取到的数据
yield {
'title': title,
'body': body,
}
这是一个简单的爬虫示例,通过定义爬虫类、指定起始 URL 和解析方法,用户可以快速创建一个基本的爬虫。
以上是 Scrapy 的简要介绍,它的灵活性和强大功能使其成为网络爬虫领域的瑞士军刀。
安装scrapy,并创建项目
使用python包管理工具pip安装scrapy
pip install scrapy
安装完成后使用scrapy创建项目
scrapy startproject sw
创建完成后,我的目录格式如下:
sw/
│
├── sw/
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders/
│ └── __init__.py
│
├── scrapy.cfg
└── README.md
解释一下各个目录和文件的作用:
-
sw/sw/: 项目的 Python 模块,包含了爬虫项目的主要代码。
- init.py: 空文件,用于指示该目录是一个 Python 包。
- items.py: 定义用于存储爬取数据的数据模型。
- middlewares.py: 包含自定义中间件的文件,用于处理请求和响应。
- pipelines.py: 包含自定义管道的文件,用于处理抓取到的数据的存储和处理。
- settings.py: 包含项目的设置和配置信息。
(如果要链接数据库,记得在这个文件里填写相应信息) - spiders/: 存放爬虫代码的目录。
- init.py: 空文件,用于指示该目录是一个 Python 包。
-
scrapy.cfg: Scrapy 项目的配置文件,包含有关项目的元数据和设置。
-
README.md: 项目的说明文档,可以包含有关项目的描述、使用说明等信息。
这是一个标准的 Scrapy 项目结构,您可以根据实际需求和项目规模进行调整和扩展。
运行单个脚本
代码示例
配置
先配置相关信息
item
item.py中的内容如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class SwItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
title = scrapy.Field()
time = scrapy.Field()
content = scrapy.Field()
scrapy_time = scrapy.Field()
trans_title = scrapy.Field()
trans_content = scrapy.Field()
org = scrapy.Field()
trans_org = scrapy.Field()
setting
setting.py中的内容如下:
# Scrapy settings for sw project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "sw"
SPIDER_MODULES = ["sw.spiders"]
NEWSPIDER_MODULE = "sw.spiders"
DOWNLOAD_DELAY = 3
RANDOMIZE_DOWNLOAD_DELAY = True
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
COOKIES_ENABLED = True
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "sw (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "sw.middlewares.SwSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "sw.middlewares.SwDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# "sw.pipelines.SwPipeline": 300,
#}
# ITEM_PIPELINES = {
# "sw.pipelines.SwPipeline": 300,
# }
# 数据库的相关配置
# DB_SETTINGS = {
# 'host': '127.0.0.1',
# 'port': 3306,
# 'user': 'root',
# 'password': '123456',
# 'db': 'scrapy_news_2024_01_08',
# 'charset': 'utf8mb4',
# }
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
# REDIRECT_ENABLED = False
爬虫脚本
过程非常简单,只需要在spiders/目录下,创建自己的代码即可。示例代码p3_new_39.py (tips: 直接把这个代码放到spiders/目录下,在控制台中输入scrapy crawl p3_new_39 -o p3_new_39.csv即可运行!-o 后面接的是输出文件。) 如下:
"""
Created on 2024/01/06 14:00 by Fxy
"""
import scrapy
from sw.items import SwItem
import time
from datetime import datetime
class SWSpider(scrapy.Spider):
'''
scrapy变量
'''
# 爬虫名称(自己定义)
name = "p3_new_39"
# 允许爬取的域名
allowed_domains = ["www.meduniwien.ac.at"]
# 爬虫的起始链接
start_urls = ["https://www.meduniwien.ac.at/web/en/about-us/news/"]
# 创建一个VidoItem实例
item = SwItem()
'''
自定义变量
'''
# 机构名称
org = "奥地利维也纳医科大学病毒学中心"
# 机构英文名称
org_e = "Med Univ Vienna, Ctr Virol"
# 日期格式
site_date_format = '%Y-%m-%d %H:%M' # 网页的日期格式
date_format = '%d.%m.%Y %H:%M:%S' # 目标日期格式
# 网站语言格式
language_type = "zh2zh" # 中文到中文的语言代码, 调用翻译接口时,使用
#爬虫的主入口,这里是获取所有的归档文章链接
def parse(self,response):
achieve_links = response.xpath('//*[@id="c4345"]//div[@class="news-teaser__caption"]/h2/a/@href').extract()
print("achieve_links",achieve_links)
for achieve_link in achieve_links:
if "http" in achieve_link:
continue
full_achieve_link = "https://www.meduniwien.ac.at" + achieve_link
print("full_achieve_link", full_achieve_link)
# 进入每个归档链接
yield scrapy.Request(full_achieve_link, callback=self.parse_item, dont_filter=True)
#翻页逻辑
xpath_expression = f'//*[@id="c4345"]//ul[@class="pagination"]/li[@class="next"]/a/@href'
next_page = response.xpath(xpath_expression).extract_first()
print("next_page = ", next_page)
# 翻页操作
if next_page != None:
print(next_page)
print('next page')
full_next_page = "https://www.meduniwien.ac.at" + next_page
print("full_next_page",full_next_page)
yield scrapy.Request(full_next_page, callback=self.parse, dont_filter=True)
#获取每个文章的内容,并存入item
def parse_item(self,response):
source_url = response.url
print("source_url:", source_url)
title_o = response.xpath('//*[@id="main"]/header/div/div[2]/div[1]/h1/text()').extract_first().strip()
# title_t = my_tools.get_trans(title_o, "de2zh") *[@id="c4342"]/div/div/div[2]/span
print("title_o:", title_o) #//*[@id="c4342"]/div/div/div[2]/span
year_string = response.xpath('//div[@class="news-detail__meta"]/span/@data-year').extract_first().strip()
month_string = response.xpath('//div[@class="news-detail__meta"]/span/@data-month').extract_first().strip()
day_string = response.xpath('//div[@class="news-detail__meta"]/span/@data-day').extract_first().strip()
hour_string = response.xpath('//div[@class="news-detail__meta"]/span/@data-hour').extract_first().strip()
minute_string = response.xpath('//div[@class="news-detail__meta"]/span/@data-minute').extract_first().strip()
publish_time = f'{year_string}-{month_string}-{day_string} {hour_string}:{minute_string}'
print("publish_time:", publish_time)
date_object = datetime.strptime(publish_time, self.site_date_format) # 先读取成网页的日期格式
date_object = date_object.strftime(self.date_format) # 转换成目标的日期字符串
publish_time = datetime.strptime(date_object, self.date_format) # 从符合格式的字符串,转换成日期
content_o = [content.strip() for content in response.xpath('//div[@class="content__block"]//text()').extract()]
content_o = ' '.join(content_o) # 这个content_o提取出来是一个字符串数组,所以要拼接成字符串
# content_t = my_tools.get_trans(content_o, "de2zh")
print("source_url:", source_url)
print("title_o:", title_o)
# print("title_t:", title_t)
print("publish_time:", publish_time) #15.01.2008
print("content_o:", content_o)
# print("content_t:", content_t)
print("-" * 50)
page_data = {
'source_url': source_url,
'title_o': title_o,
# 'title_t' : title_t,
'publish_time': publish_time,
'content_o': content_o,
# 'content_t': content_t,
'org' : self.org,
'org_e' : self.org_e,
}
self.item['url'] = page_data['source_url']
self.item['title'] = page_data['title_o']
# self.item['title_t'] = page_data['title_t']
self.item['time'] = page_data['publish_time']
self.item['content'] = page_data['content_o']
# self.item['content_t'] = page_data['content_t']
# 获取当前时间
current_time = datetime.now()
# 格式化成字符串
formatted_time = current_time.strftime(self.date_format)
# 将字符串转换为 datetime 对象
datetime_object = datetime.strptime(formatted_time, self.date_format)
self.item['scrapy_time'] = datetime_object
self.item['org'] = page_data['org']
self.item['trans_org'] = page_data['org_e']
yield self.item
在控制台中输入scrapy crawl p3_new_39 -o p3_new_39.csv即可运行!-o 后面接的是输出文件。
代码解析
接下来我们来分析,上面p3_new_39.py代码中的response.xpath()中的参数如何确定。
1、首先进入网页: https://www.meduniwien.ac.at/web/en/about-us/news/(外):
2、确定自己要爬取的数据,这里我假定为每一条新闻。

3、打开浏览器的调试工具(默认f12)找到跳转的链接。

4、右键元素,复制xpath即可。
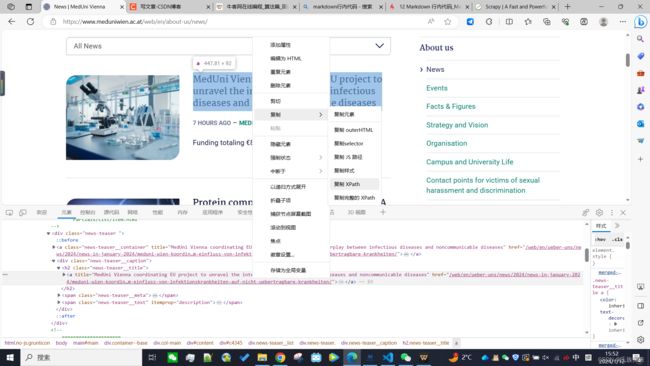
我的复制结果如下://*[@id="c4345"]/div/div[1]/div/h2/a
xpath基本语法:
XPath(XML Path Language)是一种用于在 XML 文档中定位和选择节点的查询语言。它不仅可以用于 XML,还可以用于 HTML 和其他标记语言。以下是XPath的主要语法和一些常见用法:
-
节点选择:
/: 从根节点开始选择。//: 选择节点,不考虑它们的位置。.: 选取当前节点。..: 选取当前节点的父节点。
-
节点名称:
elementName: 选取所有名称为elementName的节点。*: 选取所有子节点。
-
谓语:
[condition]: 通过添加条件筛选节点。- 例如:
//div[@class='example']选取所有 class 属性为 ‘example’ 的 div 节点。
- 例如:
路径表达式示例:
/bookstore/book[1]: 选取第一个/bookstore/book[last()]: 选取最后一个/bookstore/book[position()<3]: 选取前两个//title[@lang='en']: 选取所有带有 lang 属性为 ‘en’ 的</code> 元素。</li> <li><code>//title[@lang='en']/text()</code>: 选取所有带有 lang 属性为 ‘en’ 的 <code><title></code> 元素的文本内容。</li> <li><code>//title[not(@lang='en')]/text()</code>: 选取所有 lang 属性<mark>不</mark>为 ‘en’ 的 <code><title></code> 元素的文本内容。</li> <li><code>//title[@lang='en' or @lang='zh']/text()</code>: 选取所有带有 lang 属性为 ‘en’ <mark>或</mark> ‘zh’ 的 <code><title></code> 元素的文本内容。</li> <li><code>//title[contains(@lang, 'en')]/text()</code> 选取所有带有 lang 属性<mark>包含</mark> 'en’子串 的 <code><title></code> 元素的文本内容。</li> </ul> <h4>通配符和多路径:</h4> <ul> <li><code>*</code>: 通配符,匹配任何元素节点。</li> <li><code>@*</code>: 匹配任何属性节点。</li> <li><code>//book/title | //book/price</code>: 选取所有 <code><book></code> 元素的 <code><title></code> 和 <code><price></code> 子元素。</li> </ul> <h4>函数:</h4> <p>XPath 还支持一些内置函数,例如:</p> <ul> <li><code>text()</code>: 获取节点的文本内容。</li> <li><code>contains(str1, str2)</code>: 判断一个字符串是否包含另一个字符串。</li> </ul> <h4>示例:</h4> <p>考虑以下 XML 结构:</p> <pre><code class="prism language-xml"><span class="token tag"><span class="token tag"><span class="token punctuation"><</span>bookstore</span><span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span>book</span><span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span>title</span> <span class="token attr-name">lang</span><span class="token attr-value"><span class="token punctuation attr-equals">=</span><span class="token punctuation">"</span>en<span class="token punctuation">"</span></span><span class="token punctuation">></span></span>Introduction to XPath<span class="token tag"><span class="token tag"><span class="token punctuation"></</span>title</span><span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span>price</span><span class="token punctuation">></span></span>29.95<span class="token tag"><span class="token tag"><span class="token punctuation"></</span>price</span><span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"></</span>book</span><span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span>book</span><span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span>title</span> <span class="token attr-name">lang</span><span class="token attr-value"><span class="token punctuation attr-equals">=</span><span class="token punctuation">"</span>fr<span class="token punctuation">"</span></span><span class="token punctuation">></span></span>XPath et ses applications<span class="token tag"><span class="token tag"><span class="token punctuation"></</span>title</span><span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span>price</span><span class="token punctuation">></span></span>39.99<span class="token tag"><span class="token tag"><span class="token punctuation"></</span>price</span><span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"></</span>book</span><span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"></</span>bookstore</span><span class="token punctuation">></span></span> </code></pre> <p>使用 XPath 可以选择如下:</p> <ul> <li><code>/bookstore/book</code>: 选取所有 <code><book></code> 元素。</li> <li><code>/bookstore/book/title[@lang='en']</code>: 选取所有带有 lang 属性为 ‘en’ 的 <code><title></code> 元素。</li> </ul> <p>这是XPath的基本语法和用法示例,它允许您灵活而精确地定位和提取 XML 或 HTML 文档中的数据。</p> <h2>批量运行</h2> <p>在<code>sw</code>项目目录下可以创建一个mian.py</p> <pre><code class="prism language-python"><span class="token keyword">from</span> scrapy<span class="token punctuation">.</span>crawler <span class="token keyword">import</span> CrawlerProcess <span class="token keyword">from</span> scrapy<span class="token punctuation">.</span>utils<span class="token punctuation">.</span>project <span class="token keyword">import</span> get_project_settings settings <span class="token operator">=</span> get_project_settings<span class="token punctuation">(</span><span class="token punctuation">)</span> crawler <span class="token operator">=</span> CrawlerProcess<span class="token punctuation">(</span>settings<span class="token punctuation">)</span> bot_list <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token string">"p3_new_39"</span><span class="token punctuation">]</span> <span class="token comment"># 把要运行的通通放进去</span> <span class="token keyword">for</span> bot <span class="token keyword">in</span> bot_list<span class="token punctuation">:</span> crawler<span class="token punctuation">.</span>crawl<span class="token punctuation">(</span>bot<span class="token punctuation">)</span> crawler<span class="token punctuation">.</span>start<span class="token punctuation">(</span><span class="token punctuation">)</span> </code></pre> <h2>附录1,持久化存入数据库</h2> <p>scrapy有个非常好的特点,就是支持自动存入数据库。我们只要将代码写好,然后每次scrapy都会自动调用该代码,不需要自己显示的调用,非常省心。我的<code>piplines.py</code>代码如下:</p> <pre><code class="prism language-python"><span class="token comment"># Define your item pipelines here</span> <span class="token comment">#</span> <span class="token comment"># Don't forget to add your pipeline to the ITEM_PIPELINES setting</span> <span class="token comment"># See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html</span> <span class="token comment"># useful for handling different item types with a single interface</span> <span class="token keyword">from</span> itemadapter <span class="token keyword">import</span> ItemAdapter <span class="token keyword">import</span> pymysql <span class="token keyword">class</span> <span class="token class-name">SwPipeline</span><span class="token punctuation">:</span> <span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> db_settings<span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>db_settings <span class="token operator">=</span> db_settings <span class="token decorator annotation punctuation">@classmethod</span> <span class="token keyword">def</span> <span class="token function">from_crawler</span><span class="token punctuation">(</span>cls<span class="token punctuation">,</span> crawler<span class="token punctuation">)</span><span class="token punctuation">:</span> db_settings <span class="token operator">=</span> crawler<span class="token punctuation">.</span>settings<span class="token punctuation">.</span>get<span class="token punctuation">(</span><span class="token string">"DB_SETTINGS"</span><span class="token punctuation">)</span> <span class="token keyword">return</span> cls<span class="token punctuation">(</span>db_settings<span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">open_spider</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> spider<span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>connection <span class="token operator">=</span> pymysql<span class="token punctuation">.</span>connect<span class="token punctuation">(</span><span class="token operator">**</span>self<span class="token punctuation">.</span>db_settings<span class="token punctuation">)</span> self<span class="token punctuation">.</span>cursor <span class="token operator">=</span> self<span class="token punctuation">.</span>connection<span class="token punctuation">.</span>cursor<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">close_spider</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> spider<span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>connection<span class="token punctuation">.</span>close<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">process_item</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> item<span class="token punctuation">,</span> spider<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># Assuming your item keys match the column names in your database table</span> keys <span class="token operator">=</span> <span class="token string">', '</span><span class="token punctuation">.</span>join<span class="token punctuation">(</span>item<span class="token punctuation">.</span>keys<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> values <span class="token operator">=</span> <span class="token string">', '</span><span class="token punctuation">.</span>join<span class="token punctuation">(</span><span class="token punctuation">[</span><span class="token string">'%s'</span><span class="token punctuation">]</span> <span class="token operator">*</span> <span class="token builtin">len</span><span class="token punctuation">(</span>item<span class="token punctuation">)</span><span class="token punctuation">)</span> query <span class="token operator">=</span> <span class="token string-interpolation"><span class="token string">f"INSERT INTO org_news (</span><span class="token interpolation"><span class="token punctuation">{</span>keys<span class="token punctuation">}</span></span><span class="token string">) VALUES (</span><span class="token interpolation"><span class="token punctuation">{</span>values<span class="token punctuation">}</span></span><span class="token string">)"</span></span> <span class="token comment">#这里记得确认我们item.py中定义的类型名字,是否和数据库中的一样,不一样,这个查询语句需要进行相应的修改,我这里就不一样,所以没法直接运行哦,我懒得改了!!!!哈哈哈</span> <span class="token comment"># Check if the record already exists based on a combination of fields, 如果记录已经存在则取消插入,如果有键的话直接用键就行,我这里没有键</span> unique_fields <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token string">"title_o"</span><span class="token punctuation">,</span> <span class="token string">"source_url"</span><span class="token punctuation">]</span> <span class="token comment"># Replace with the actual field names you want to use</span> check_query <span class="token operator">=</span> <span class="token string-interpolation"><span class="token string">f"SELECT * FROM org_news WHERE </span><span class="token interpolation"><span class="token punctuation">{</span><span class="token string">' AND '</span><span class="token punctuation">.</span>join<span class="token punctuation">(</span><span class="token string-interpolation"><span class="token string">f'</span><span class="token interpolation"><span class="token punctuation">{</span>field<span class="token punctuation">}</span></span><span class="token string"> = %s'</span></span> <span class="token keyword">for</span> field <span class="token keyword">in</span> unique_fields<span class="token punctuation">)</span><span class="token punctuation">}</span></span><span class="token string">"</span></span> check_values <span class="token operator">=</span> <span class="token builtin">tuple</span><span class="token punctuation">(</span>item<span class="token punctuation">.</span>get<span class="token punctuation">(</span>field<span class="token punctuation">)</span> <span class="token keyword">for</span> field <span class="token keyword">in</span> unique_fields<span class="token punctuation">)</span> <span class="token keyword">try</span><span class="token punctuation">:</span> <span class="token comment"># Check if the record already exists</span> self<span class="token punctuation">.</span>cursor<span class="token punctuation">.</span>execute<span class="token punctuation">(</span>check_query<span class="token punctuation">,</span> check_values<span class="token punctuation">)</span> existing_record <span class="token operator">=</span> self<span class="token punctuation">.</span>cursor<span class="token punctuation">.</span>fetchone<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">if</span> existing_record<span class="token punctuation">:</span> spider<span class="token punctuation">.</span>logger<span class="token punctuation">.</span>warning<span class="token punctuation">(</span><span class="token string">"Record already exists. Skipping insertion."</span><span class="token punctuation">)</span> <span class="token keyword">else</span><span class="token punctuation">:</span> <span class="token comment"># If the record doesn't exist, insert it into the database</span> self<span class="token punctuation">.</span>cursor<span class="token punctuation">.</span>execute<span class="token punctuation">(</span>query<span class="token punctuation">,</span> <span class="token builtin">tuple</span><span class="token punctuation">(</span>item<span class="token punctuation">.</span>values<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span> self<span class="token punctuation">.</span>connection<span class="token punctuation">.</span>commit<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">except</span> Exception <span class="token keyword">as</span> e<span class="token punctuation">:</span> self<span class="token punctuation">.</span>connection<span class="token punctuation">.</span>rollback<span class="token punctuation">(</span><span class="token punctuation">)</span> spider<span class="token punctuation">.</span>logger<span class="token punctuation">.</span>error<span class="token punctuation">(</span><span class="token string-interpolation"><span class="token string">f"Error processing item and inserting data into database: </span><span class="token interpolation"><span class="token punctuation">{</span>e<span class="token punctuation">}</span></span><span class="token string">"</span></span><span class="token punctuation">)</span> <span class="token keyword">return</span> item </code></pre> <p>我创建数据库的代码如下:</p> <pre><code class="prism language-sql"><span class="token comment">/* Navicat Premium Data Transfer Source Server : 172.16.6.165 Source Server Type : MySQL Source Server Version : 80035 Source Host : 172.16.6.165:3306 Source Schema : swaq Target Server Type : MySQL Target Server Version : 80035 File Encoding : 65001 Date: 08/01/2024 10:01:57 */</span> <span class="token keyword">SET</span> NAMES utf8mb4<span class="token punctuation">;</span> <span class="token keyword">SET</span> FOREIGN_KEY_CHECKS <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">;</span> <span class="token comment">-- ----------------------------</span> <span class="token comment">-- Table structure for org_news</span> <span class="token comment">-- ----------------------------</span> <span class="token keyword">DROP</span> <span class="token keyword">TABLE</span> <span class="token keyword">IF</span> <span class="token keyword">EXISTS</span> <span class="token identifier"><span class="token punctuation">`</span>org_news<span class="token punctuation">`</span></span><span class="token punctuation">;</span> <span class="token keyword">CREATE</span> <span class="token keyword">TABLE</span> <span class="token identifier"><span class="token punctuation">`</span>org_news<span class="token punctuation">`</span></span> <span class="token punctuation">(</span> <span class="token identifier"><span class="token punctuation">`</span>id<span class="token punctuation">`</span></span> <span class="token keyword">int</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">)</span> <span class="token operator">NOT</span> <span class="token boolean">NULL</span> <span class="token keyword">AUTO_INCREMENT</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>title_t<span class="token punctuation">`</span></span> <span class="token keyword">varchar</span><span class="token punctuation">(</span><span class="token number">1000</span><span class="token punctuation">)</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'翻译标题名称'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>title_o<span class="token punctuation">`</span></span> <span class="token keyword">varchar</span><span class="token punctuation">(</span><span class="token number">1000</span><span class="token punctuation">)</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'原消息标题'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>content_t<span class="token punctuation">`</span></span> <span class="token keyword">longtext</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'翻译'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>publish_time<span class="token punctuation">`</span></span> <span class="token keyword">datetime</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">)</span> <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'发布时间'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>content_o<span class="token punctuation">`</span></span> <span class="token keyword">longtext</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'原文'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>site<span class="token punctuation">`</span></span> <span class="token keyword">varchar</span><span class="token punctuation">(</span><span class="token number">255</span><span class="token punctuation">)</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'新闻源'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>tag<span class="token punctuation">`</span></span> <span class="token keyword">varchar</span><span class="token punctuation">(</span><span class="token number">255</span><span class="token punctuation">)</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'标签'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>author<span class="token punctuation">`</span></span> <span class="token keyword">varchar</span><span class="token punctuation">(</span><span class="token number">255</span><span class="token punctuation">)</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'作者'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>create_time<span class="token punctuation">`</span></span> <span class="token keyword">datetime</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">)</span> <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'爬取时间'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>source_url<span class="token punctuation">`</span></span> <span class="token keyword">varchar</span><span class="token punctuation">(</span><span class="token number">1000</span><span class="token punctuation">)</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'url'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>country<span class="token punctuation">`</span></span> <span class="token keyword">varchar</span><span class="token punctuation">(</span><span class="token number">100</span><span class="token punctuation">)</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'国家/地区'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>imgurl<span class="token punctuation">`</span></span> <span class="token keyword">varchar</span><span class="token punctuation">(</span><span class="token number">255</span><span class="token punctuation">)</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'图片存放地址'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>org<span class="token punctuation">`</span></span> <span class="token keyword">varchar</span><span class="token punctuation">(</span><span class="token number">255</span><span class="token punctuation">)</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'机构名称'</span><span class="token punctuation">,</span> <span class="token identifier"><span class="token punctuation">`</span>org_e<span class="token punctuation">`</span></span> <span class="token keyword">varchar</span><span class="token punctuation">(</span><span class="token number">255</span><span class="token punctuation">)</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> utf8mb3 <span class="token keyword">COLLATE</span> utf8mb3_general_ci <span class="token boolean">NULL</span> <span class="token keyword">DEFAULT</span> <span class="token boolean">NULL</span> <span class="token keyword">COMMENT</span> <span class="token string">'机构英文名称'</span><span class="token punctuation">,</span> <span class="token keyword">PRIMARY</span> <span class="token keyword">KEY</span> <span class="token punctuation">(</span><span class="token identifier"><span class="token punctuation">`</span>id<span class="token punctuation">`</span></span><span class="token punctuation">)</span> <span class="token keyword">USING</span> <span class="token keyword">BTREE</span> <span class="token punctuation">)</span> <span class="token keyword">ENGINE</span> <span class="token operator">=</span> <span class="token keyword">InnoDB</span> <span class="token keyword">AUTO_INCREMENT</span> <span class="token operator">=</span> <span class="token number">314</span> <span class="token keyword">CHARACTER</span> <span class="token keyword">SET</span> <span class="token operator">=</span> utf8mb3 <span class="token keyword">COLLATE</span> <span class="token operator">=</span> utf8mb3_general_ci ROW_FORMAT <span class="token operator">=</span> Dynamic<span class="token punctuation">;</span> <span class="token keyword">SET</span> FOREIGN_KEY_CHECKS <span class="token operator">=</span> <span class="token number">1</span><span class="token punctuation">;</span> </code></pre> <h2>附录2,如何在本地启动数据库</h2> <p>1、先安装mysql<br> 2、配置好?(我电脑的mysql几年前安装的,下载了一个navicat)<br> 3、windows控制台输入<code>mysqld --console</code>应该就能启动了。<br> 注意: <code>mysqld 是服务端程序</code> ,<code>mysql是命令行客户端程序</code><br> 4、然后应该就能够连接了</p> </div> </div> </div> </div> </div> <!--PC和WAP自适应版--> <div id="SOHUCS" sid="1746010954237231104"></div> <script type="text/javascript" src="/views/front/js/chanyan.js"></script> <!-- 文章页-底部 动态广告位 --> <div class="youdao-fixed-ad" id="detail_ad_bottom"></div> </div> <div class="col-md-3"> <div class="row" id="ad"> <!-- 文章页-右侧1 动态广告位 --> <div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_1"> </div> </div> <!-- 文章页-右侧2 动态广告位 --> <div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_2"></div> </div> <!-- 文章页-右侧3 动态广告位 --> <div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_3"></div> </div> </div> </div> </div> </div> </div> <div class="container"> <h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(爬虫,scrapy,爬虫)</h4> <div id="paradigm-article-related"> <div class="recommend-post mb30"> <ul class="widget-links"> <li><a href="/article/1886261090581540864.htm" title="Python淘宝电脑销售数据爬虫可视化分析大屏全屏系统 开题报告" target="_blank">Python淘宝电脑销售数据爬虫可视化分析大屏全屏系统 开题报告</a> <span class="text-muted">字节全栈_Jwy</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/flutter/1.htm">flutter</a> <div>博主介绍:黄菊华老师《Vue.js入门与商城开发实战》《微信小程序商城开发》图书作者,CSDN博客专家,在线教育专家,CSDN钻石讲师;专注大学生毕业设计教育和辅导。所有项目都配有从入门到精通的基础知识视频课程,学习后应对毕业设计答辩。项目配有对应开发文档、开题报告、任务书、PPT、论文模版等项目都录了发布和功能操作演示视频;项目的界面和功能都可以定制,包安装运行!!!如果需要联系我,可以在CSD</div> </li> <li><a href="/article/1886180634590769152.htm" title="从零开始构建一个简单的Python Web爬虫实战指南与技巧" target="_blank">从零开始构建一个简单的Python Web爬虫实战指南与技巧</a> <span class="text-muted">一键难忘</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a> <div>从零开始构建一个简单的PythonWeb爬虫实战指南与技巧随着数据科学和大数据分析的快速发展,网络爬虫(WebScraping)成为了获取互联网数据的重要工具。通过爬虫,我们可以自动化地从网页上获取各种信息,如新闻、产品价格、社交媒体内容等。本文将带您从零开始,使用Python构建一个简单的Web爬虫,抓取网页内容并保存数据。Web爬虫的基本概念什么是Web爬虫?Web爬虫(也称为网络蜘蛛或抓取器</div> </li> <li><a href="/article/1886148475930865664.htm" title="python爬虫之JS逆向入门,了解JS逆向的原理及用法(18)" target="_blank">python爬虫之JS逆向入门,了解JS逆向的原理及用法(18)</a> <span class="text-muted">盲敲代码的阿豪</span> <a class="tag" taget="_blank" href="/search/python%E4%B9%8B%E7%88%AC%E8%99%AB%E7%B3%BB%E7%BB%9F%E6%95%99%E5%AD%A6/1.htm">python之爬虫系统教学</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a><a class="tag" taget="_blank" href="/search/JS%E9%80%86%E5%90%91/1.htm">JS逆向</a> <div>文章目录1.JS逆向是什么?2、如何分析加密参数并还原其加密方式?2.1分析JS加密的网页2.2编写python代码还原JS加密代码3、案例测试4、操作进阶(通过执行第三方js文件实现逆向)4.1python第三方模块(execjs)4.2调用第三方js文件完成逆向操作4.3总结1.JS逆向是什么?什么是JS加密?我们在分析某些网站的数据接口时,经常会遇到一些密文参数,这些参数实际就是通过Java</div> </li> <li><a href="/article/1886101930166513664.htm" title="Pyhon : 爬虫Requests高级用法--超时(timeout)" target="_blank">Pyhon : 爬虫Requests高级用法--超时(timeout)</a> <span class="text-muted">ZhuCheng Xie</span> <a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a> <div>超时(timeout)为防止服务器不能及时响应,大部分发至外部服务器的请求都应该带着timeout参数。在默认情况下,除非显式指定了timeout值,requests是不会自动进行超时处理的。如果没有timeout,你的代码可能会挂起若干分钟甚至更长时间。连接超时指的是在你的客户端实现到远端机器端口的连接时(对应的是connect()_),Request会等待的秒数。一个很好的实践方法是把连接超时</div> </li> <li><a href="/article/1886097008519868416.htm" title="Python网络爬虫调试技巧:解决爬虫中的问题" target="_blank">Python网络爬虫调试技巧:解决爬虫中的问题</a> <span class="text-muted">master_chenchengg</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/python%E5%BC%80%E5%8F%91/1.htm">python开发</a><a class="tag" taget="_blank" href="/search/IT/1.htm">IT</a> <div>Python网络爬虫调试技巧:解决爬虫中的问题引子:当你的小蜘蛛遇到大麻烦知己知彼:了解常见的爬虫错误类型侦探出马:使用开发者工具和日志追踪问题源头化险为夷:调整User-Agent与添加延时策略进阶秘籍:处理JavaScript渲染页面与动态加载内容引子:当你的小蜘蛛遇到大麻烦在一个阳光明媚的下午,我正坐在电脑前,满怀信心地运行着我的Python爬虫脚本。这个脚本是为了从一个大型电子商务网站上抓</div> </li> <li><a href="/article/1886096504108675072.htm" title="requests模块-timeout参数" target="_blank">requests模块-timeout参数</a> <span class="text-muted">李乾星</span> <a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB%E8%87%AA%E5%AD%A6%E7%AC%94%E8%AE%B0/1.htm">爬虫自学笔记</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/1.htm">网络爬虫</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E5%8D%8F%E8%AE%AE/1.htm">网络协议</a> <div>超时参数timeout的重要性与使用方法在进行网上冲浪或爬虫项目开发时,我们常常会遇到网络波动和请求处理时间过长的情况。长时间等待一个请求可能仍然没有结果,导致整个项目效率低下。为了解决这个问题,我们可以使用超时参数timeout来强制要求请求在特定时间内返回结果,否则将抛出异常。使用超时参数timeout的方法在学习爬虫和request模块的过程中,我们会频繁使用requests.get(url</div> </li> <li><a href="/article/1886065365117628416.htm" title="Python从0到100(八十一):神经网络-Fashion MNIST数据集取得最高的识别准确率" target="_blank">Python从0到100(八十一):神经网络-Fashion MNIST数据集取得最高的识别准确率</a> <span class="text-muted">是Dream呀</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/1.htm">神经网络</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>前言:零基础学Python:Python从0到100最新最全教程。想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学习学习和学业的先行者!欢迎大家订阅专栏:零基础学Python:Python从0到100最新</div> </li> <li><a href="/article/1886011409897156608.htm" title="Python 网络爬虫实战:从基础到高级爬取技术" target="_blank">Python 网络爬虫实战:从基础到高级爬取技术</a> <span class="text-muted">一ge科研小菜鸡</span> <a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8%80/1.htm">编程语言</a><a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a> <div>个人主页:一ge科研小菜鸡-CSDN博客期待您的关注1.引言网络爬虫(WebScraping)是一种自动化技术,利用程序从网页中提取数据,广泛应用于数据采集、搜索引擎、市场分析、舆情监测等领域。本教程将涵盖requests、BeautifulSoup、Selenium、Scrapy等常用工具,并深入探讨反爬机制突破、动态加载页面、模拟登录、多线程/分布式爬取等高级技巧。2.爬虫基础:request</div> </li> <li><a href="/article/1885992747584778240.htm" title="对Python中常用的爬虫request库做一个简单的介绍" target="_blank">对Python中常用的爬虫request库做一个简单的介绍</a> <span class="text-muted">HL.云黑</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>在Python爬虫的世界中,Requests库是一个不可或缺的工具。它以其简洁的API和强大的功能,成为了开发者进行HTTP请求的首选库。下面将从几个方面介绍Requests库的特点和使用技巧。1.简洁易用的APIRequests库的设计理念是让HTTP请求变得简单直观。通过几行代码,开发者就可以发送GET或POST请求,获取网页内容。例如:```pythonimportrequestsrespo</div> </li> <li><a href="/article/1885992621231370240.htm" title="Python一个爬虫" target="_blank">Python一个爬虫</a> <span class="text-muted">HL.云黑</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>importrequestsimportreimportthreadingfromconcurrent.futuresimportThreadPoolExecutorheaders={'User-Agent':'Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/62.0.3202.101Safari/5</div> </li> <li><a href="/article/1885974593164865536.htm" title="pythonrequests发送数据_对python requests发送json格式数据的实例详解" target="_blank">pythonrequests发送数据_对python requests发送json格式数据的实例详解</a> <span class="text-muted">weixin_39652869</span> <div>requests是常用的请求库,不管是写爬虫脚本,还是测试接口返回数据等。都是很简单常用的工具。这里就记录一下如何用requests发送json格式的数据,因为一般我们post参数,都是直接post,没管post的数据的类型,它默认有一个类型的,貌似是application/x-www-form-urlencoded。但是,我们写程序的时候,最常用的接口post数据的格式是json格式。当我们需要</div> </li> <li><a href="/article/1885889999786799104.htm" title="python怎么爬网站视频教程_python爬虫爬取某网站视频的示例代码" target="_blank">python怎么爬网站视频教程_python爬虫爬取某网站视频的示例代码</a> <span class="text-muted">weixin_39630247</span> <a class="tag" taget="_blank" href="/search/python%E6%80%8E%E4%B9%88%E7%88%AC%E7%BD%91%E7%AB%99%E8%A7%86%E9%A2%91%E6%95%99%E7%A8%8B/1.htm">python怎么爬网站视频教程</a> <div>把获取到的下载视频的url存放在数组中(也可写入文件中),通过调用迅雷接口,进行自动下载。(请先下载迅雷,并在其设置中心的下载管理中设置为一键下载)实现代码如下:frombs4importBeautifulSoupimportrequestsimportos,re,timeimporturllib3fromwin32com.clientimportDispatchclassDownloadVide</div> </li> <li><a href="/article/1885879033015627776.htm" title="运用python爬虫爬取汽车网站图片并下载,几个汽车网站的示例参考" target="_blank">运用python爬虫爬取汽车网站图片并下载,几个汽车网站的示例参考</a> <span class="text-muted">大懒猫软件</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E6%B1%BD%E8%BD%A6/1.htm">汽车</a><a class="tag" taget="_blank" href="/search/%E5%9B%BE%E5%83%8F%E5%A4%84%E7%90%86/1.htm">图像处理</a> <div>当然,以下是一些常见的汽车网站及其爬虫示例代码,展示如何爬取汽车图片并下载。请注意,爬取网站内容时应遵守网站的使用协议和法律法规,避免对网站造成不必要的负担。示例1:爬取汽车之家图片网站地址汽车之家爬虫代码Python复制importrequestsfrombs4importBeautifulSoupimportosdefdownload_images(url,folder):ifnotos.pa</div> </li> <li><a href="/article/1885868433334136832.htm" title="爬虫_pandas" target="_blank">爬虫_pandas</a> <span class="text-muted">起来,该敲代码啦</span> <a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a> <div>123.pyimportpandasaspddf=pd.read_csv('./123.csv')打印某一列;判断某一列是否有空值print(df['NUM_BEDROOMS'])print(df['NUM_BEDROOMS'].isnull())dropna()中写inplace=True修改源数据df2=df.dropna()指定的列的某一行有空值的话就删除那一行数据df3=df.dropna</div> </li> <li><a href="/article/1885733425491537920.htm" title="爬虫基础(五)爬虫基本原理" target="_blank">爬虫基础(五)爬虫基本原理</a> <span class="text-muted">A.sir啊</span> <a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB%E5%BF%85%E5%A4%87%E7%9F%A5%E8%AF%86%E7%82%B9/1.htm">网络爬虫必备知识点</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a><a class="tag" taget="_blank" href="/search/http/1.htm">http</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E5%8D%8F%E8%AE%AE/1.htm">网络协议</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/pycharm/1.htm">pycharm</a> <div>目录一、爬虫是什么二、爬虫过程(1)获取网页(2)提取信息(3)保存数据三、爬虫可爬的数据四、爬虫问题一、爬虫是什么互联网,后面有个网字,我们可以把它看成一张蜘蛛网。爬虫,后面有个虫子,我们可以把它看成蜘蛛。爬虫之于互联网,就是蜘蛛之于蜘蛛网。蜘蛛每爬到一个节点,就是爬虫访问了一个网页。用正式的话来说,爬虫,就是自动提取、保存网页信息的程序。二、爬虫过程(1)获取网页获取网页,就是获取网页的源代码</div> </li> <li><a href="/article/1885733423696375808.htm" title="爬虫基础(三)Session和Cookie讲解" target="_blank">爬虫基础(三)Session和Cookie讲解</a> <span class="text-muted">A.sir啊</span> <a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB%E5%BF%85%E5%A4%87%E7%9F%A5%E8%AF%86%E7%82%B9/1.htm">网络爬虫必备知识点</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/1.htm">网络爬虫</a> <div>目录一、前备知识点(1)静态网页(2)动态网页(3)无状态HTTP二、Session和Cookie三、Session四、Cookie(1)维持过程(2)结构正式开始说Session和Cookie之前,有些基础知识需要知道,我们先来看一下:一、前备知识点(1)静态网页比如,我们写了一段html代码,然后保存为一个html文件该文件所在主机,具有服务器那么其他人就可以通过访问服务器,来打开这个html</div> </li> <li><a href="/article/1885733424665260032.htm" title="爬虫基础(四)线程 和 进程 及相关知识点" target="_blank">爬虫基础(四)线程 和 进程 及相关知识点</a> <span class="text-muted">A.sir啊</span> <a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB%E5%BF%85%E5%A4%87%E7%9F%A5%E8%AF%86%E7%82%B9/1.htm">网络爬虫必备知识点</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/1.htm">网络爬虫</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/pycharm/1.htm">pycharm</a> <div>目录一、线程和进程(1)进程(2)线程(3)区别二、串行、并发、并行(1)串行(2)并行(3)并发三、爬虫中的线程和进程(1)GIL锁(2)爬虫的多线程(3)Python的多进程一、线程和进程(1)进程所谓进程,就是正在运行的程序,它占用独立的内存区域用通俗的话来说:我们打开媒体播放器,就是打开了一个媒体播放器进程,打开浏览器,就是打开了一个浏览器进程,打开某软件,就是打开了某软件进程。这三个进程</div> </li> <li><a href="/article/1885730651370483712.htm" title="爬虫基础(六)代理简述" target="_blank">爬虫基础(六)代理简述</a> <span class="text-muted">A.sir啊</span> <a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB%E5%BF%85%E5%A4%87%E7%9F%A5%E8%AF%86%E7%82%B9/1.htm">网络爬虫必备知识点</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E5%8D%8F%E8%AE%AE/1.htm">网络协议</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a> <div>目录一、什么是代理二、基本原理三、代理分类一、什么是代理爬虫一般是自动化的,当我们自动运行时爬虫自动抓取数据,但一会就出现了错误:如,您的访问频率过高!这是因为网站的反爬措施,如果频繁访问,则会被禁止,即封IP为解决这种情况,我们需要把自己的IP伪装一下,即代理所谓代理,就是代理服务器。二、基本原理正常来说:客户发送请求给服务器然后服务器将响应传给客户而代理的话:相当于在客户和服务器之间加一个代理</div> </li> <li><a href="/article/1885644022379245568.htm" title="python 爬取小红书" target="_blank">python 爬取小红书</a> <span class="text-muted">追光少年3322</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/1.htm">网络爬虫</a> <div>爬虫实现基本流程一.明确需求明确采集的网站及数据内容目标:根据小红书作者主页链接,采集作者主页所有笔记,并保存为excel表格。采集的字段包括作者、笔记类型、标题、点赞数、笔记链接。网址:https://www.xiaohongshu.com/user/profile/64c38af4000000000e026b43二.分析思路分析爬虫思路,概括如下:打开小红书主页与登录打开小红书作者主页,获取作</div> </li> <li><a href="/article/1885609238282170368.htm" title="XXL-CRAWLER v1.4.0 | Java爬虫框架" target="_blank">XXL-CRAWLER v1.4.0 | Java爬虫框架</a> <span class="text-muted"></span> <a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF%E7%88%AC%E8%99%ABjava/1.htm">后端爬虫java</a> <div>ReleaseNotes1、【提升】爬虫JS渲染能力强化:升级提供"Selenium+ChromeDriver"方案支持JS渲染,兼容性更高,废弃旧Phantomjs方案。非JS渲染场景仍然Jsoup,速度更快。同时支持自由扩展其他实现。2、【优化】进一步优化Selenium兼容问题,完善JS渲染场景下兼容性和性能。3、【重构】重构核心功能模块,提升扩展性;修复历史代码隐藏问题,提升系统稳定习惯。</div> </li> <li><a href="/article/1885576283757277184.htm" title="03-1.python爬虫-爬虫简介" target="_blank">03-1.python爬虫-爬虫简介</a> <span class="text-muted">执着的小火车</span> <a class="tag" taget="_blank" href="/search/python%E5%85%A5%E9%97%A8%E5%88%B0%E9%A1%B9%E7%9B%AE%E5%AE%9E%E8%B7%B5/1.htm">python入门到项目实践</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/http/1.htm">http</a> <div>03-1.python爬虫-爬虫简介简介Python爬虫是一种使用Python编程语言编写的程序,用于自动从互联网上获取网页数据。它可以模拟人类浏览器的行为,发送HTTP请求到目标网站,获取网页的HTML内容,然后通过解析HTML提取所需的数据,如文本、图片链接、表格数据等。爬虫的应用广泛,比如在数据挖掘领域,可收集大量数据用于分析趋势和模式;在信息聚合方面,能将不同网站的特定信息汇总到一处;还可</div> </li> <li><a href="/article/1885576284520640512.htm" title="03-2.python爬虫-Python爬虫基础(一)" target="_blank">03-2.python爬虫-Python爬虫基础(一)</a> <span class="text-muted">执着的小火车</span> <a class="tag" taget="_blank" href="/search/python%E5%85%A5%E9%97%A8%E5%88%B0%E9%A1%B9%E7%9B%AE%E5%AE%9E%E8%B7%B5/1.htm">python入门到项目实践</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>HTTP基本原理HTTP(HyperTextTransferProtocol),即超文本传输协议,是互联网通信的关键所在。它作为应用层协议,构建于可靠的TCP协议之上,保障了数据传输的稳定与可靠,犹如网络世界的“交通规则”,规范着客户端与服务器之间的数据往来。HTTP的请求响应过程是其核心机制。当用户在浏览器中输入一个URL并按下回车键,浏览器就会作为客户端向服务器发送HTTP请求。请求由请求行、</div> </li> <li><a href="/article/1885449934254174208.htm" title="Python 爬虫实战:在马蜂窝抓取旅游攻略,打造个性化出行指南" target="_blank">Python 爬虫实战:在马蜂窝抓取旅游攻略,打造个性化出行指南</a> <span class="text-muted">西攻城狮北</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E6%97%85%E6%B8%B8/1.htm">旅游</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E5%AE%9E%E6%88%98%E6%A1%88%E4%BE%8B/1.htm">实战案例</a> <div>一、引言二、准备工作(一)安装必要的库(二)分析网页结构三、抓取攻略列表信息(一)发送请求获取网页内容(二)解析网页提取攻略信息(三)整合代码获取攻略列表四、抓取单个攻略详情信息(一)发送请求获取攻略详情页面内容(二)解析网页提取攻略详情信息(三)整合代码获取攻略详情五、数据存储(一)存储到CSV文件(二)存储到数据库(以SQLite为例)六、注意事项(一)遵守法律法规和平台规定(二)应对反爬虫机</div> </li> <li><a href="/article/1885430117530923008.htm" title="爬虫守则--写爬虫,不犯法" target="_blank">爬虫守则--写爬虫,不犯法</a> <span class="text-muted">Erfec</span> <div>玩爬虫,技术当然是中立的,浏览了因为爬虫被捕入狱的案例,自己总结了如下爬虫守则,不吃牢饭!1、爬虫速度不要太快,不要给对方服务器造成太大压力2、爬虫不要伪造VIP,绕过对方身份验证,你可以真的买一个VIP做自动化,这没问题3、公民个人信息不要去碰4、爬取的数据不能用于盈利5、爬虫是模拟人,不要做人不能做到的事情</div> </li> <li><a href="/article/1885427469125742592.htm" title="Python程序员爬取大量视频资源,最终面临刑期2年的惩罚!" target="_blank">Python程序员爬取大量视频资源,最终面临刑期2年的惩罚!</a> <span class="text-muted">夜色恬静一人</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a> <div>Python程序员爬取大量视频资源,最终面临刑期2年的惩罚!近日,一名Python程序员因为涉嫌大规模爬取视频资源而被判处2年有期徒刑。这个案例引起了广泛的关注,也引发了对于网络爬虫合法性和道德问题的讨论。据了解,这名程序员利用Python编程语言开发了一套自动化爬虫工具,通过抓取网站上的视频链接,批量下载了超过13万部视频资源。这些资源包括电影、电视剧以及其他各种类型的视频内容。然而,尽管他成功</div> </li> <li><a href="/article/1885400990165823488.htm" title="Python 爬虫实战案例 - 获取拉勾网招聘职位信息" target="_blank">Python 爬虫实战案例 - 获取拉勾网招聘职位信息</a> <span class="text-muted">西攻城狮北</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E6%8B%89%E5%8B%BE%E7%BD%91/1.htm">拉勾网</a><a class="tag" taget="_blank" href="/search/%E6%8B%9B%E8%81%98%E4%BF%A1%E6%81%AF/1.htm">招聘信息</a> <div>引言拉勾网,作为互联网招聘领域的佼佼者,汇聚了海量且多样的职位招聘信息。这些信息涵盖了从新兴科技领域到传统行业转型所需的各类岗位,无论是初出茅庐的应届生,还是经验丰富的职场老手,都能在其中探寻到机遇。对于求职者而言,能够快速、全面地掌握招聘职位的详细情况,如薪资待遇的高低、工作地点的便利性、职位描述所要求的技能与职责等,无疑能在求职路上抢占先机。而企业方,通过分析同行业职位信息的发布趋势、薪资水平</div> </li> <li><a href="/article/1885371230761054208.htm" title="Python从0到100(八十六):神经网络-ShuffleNet通道混合轻量级网络的深入介绍" target="_blank">Python从0到100(八十六):神经网络-ShuffleNet通道混合轻量级网络的深入介绍</a> <span class="text-muted">是Dream呀</span> <a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/1.htm">神经网络</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a> <div>前言:零基础学Python:Python从0到100最新最全教程。想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学习学习和学业的先行者!欢迎大家订阅专栏:零基础学Python:Python从0到100最新</div> </li> <li><a href="/article/1885300981449682944.htm" title="Python爬虫与窗口实现翻译小工具(仅限学习交流)" target="_blank">Python爬虫与窗口实现翻译小工具(仅限学习交流)</a> <span class="text-muted">纵码奔腾</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a> <div>Python爬虫与窗口实现翻译小工具(仅限学习交流)在工作中,遇到一个不懂的单词时,就会去网页找对应的翻译,我们可以用Python爬虫与窗口配合,制作一个简易的翻译小工具,不需要打开网页,自动把翻译结果显示出来。整个过程比较简单。#ThisisasamplePythonscript.#PressShift+F10toexecuteitorreplaceitwithyourcode.#PressDo</div> </li> <li><a href="/article/1885292526773006336.htm" title="Python爬虫基础知识:从零开始的抓取艺术" target="_blank">Python爬虫基础知识:从零开始的抓取艺术</a> <span class="text-muted">egzosn</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>在大数据时代,网络数据成为宝贵的资源,而Python爬虫则是获取这些数据的重要工具。本文旨在为初学者提供一份Python爬虫的入门指南,涵盖基础知识、常用库介绍、实战案例以及注意事项,帮助你快速上手,成为一名合格的“网络矿工”。一、Python爬虫概述1.1什么是爬虫?爬虫,也称为网络爬虫或蜘蛛,是一种自动抓取互联网信息的程序。它通过模拟人类浏览网页的行为,自动地遍历和抓取网络上的数据,常用于数据</div> </li> <li><a href="/article/1885249141894868992.htm" title="Python的旅游网站数据爬虫分析与可视化大屏展示论文" target="_blank">Python的旅游网站数据爬虫分析与可视化大屏展示论文</a> <span class="text-muted">IT实战课堂—x小凡同学</span> <a class="tag" taget="_blank" href="/search/Python%E6%AF%95%E4%B8%9A%E8%AE%BE%E8%AE%A1%E9%A1%B9%E7%9B%AE/1.htm">Python毕业设计项目</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E6%97%85%E6%B8%B8/1.htm">旅游</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a> <div>摘要随着互联网技术的迅猛发展,旅游行业也逐渐实现了数字化转型。旅游网站作为游客获取旅游信息的主要渠道,蕴含着丰富的旅游数据资源。本文旨在通过Python技术,实现旅游网站数据的爬虫分析,并利用可视化大屏展示分析结果,为旅游行业的数据驱动决策提供支持。关键词:Python;旅游网站;数据爬虫;可视化大屏一、引言旅游行业作为服务业的重要组成部分,其发展水平直接关系到国家经济的繁荣和人民生活的质量。随着</div> </li> <li><a href="/article/65.htm" title="Java常用排序算法/程序员必须掌握的8大排序算法" target="_blank">Java常用排序算法/程序员必须掌握的8大排序算法</a> <span class="text-muted">cugfy</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a> <div>分类: 1)插入排序(直接插入排序、希尔排序) 2)交换排序(冒泡排序、快速排序) 3)选择排序(直接选择排序、堆排序) 4)归并排序 5)分配排序(基数排序) 所需辅助空间最多:归并排序 所需辅助空间最少:堆排序 平均速度最快:快速排序 不稳定:快速排序,希尔排序,堆排序。 先来看看8种排序之间的关系: 1.直接插入排序 (1</div> </li> <li><a href="/article/192.htm" title="【Spark102】Spark存储模块BlockManager剖析" target="_blank">【Spark102】Spark存储模块BlockManager剖析</a> <span class="text-muted">bit1129</span> <a class="tag" taget="_blank" href="/search/manager/1.htm">manager</a> <div>Spark围绕着BlockManager构建了存储模块,包括RDD,Shuffle,Broadcast的存储都使用了BlockManager。而BlockManager在实现上是一个针对每个应用的Master/Executor结构,即Driver上BlockManager充当了Master角色,而各个Slave上(具体到应用范围,就是Executor)的BlockManager充当了Slave角色</div> </li> <li><a href="/article/319.htm" title="linux 查看端口被占用情况详解" target="_blank">linux 查看端口被占用情况详解</a> <span class="text-muted">daizj</span> <a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E7%AB%AF%E5%8F%A3%E5%8D%A0%E7%94%A8/1.htm">端口占用</a><a class="tag" taget="_blank" href="/search/netstat/1.htm">netstat</a><a class="tag" taget="_blank" href="/search/lsof/1.htm">lsof</a> <div>经常在启动一个程序会碰到端口被占用,这里讲一下怎么查看端口是否被占用,及哪个程序占用,怎么Kill掉已占用端口的程序 1、lsof -i:port port为端口号 [root@slave /data/spark-1.4.0-bin-cdh4]# lsof -i:8080 COMMAND PID USER FD TY</div> </li> <li><a href="/article/446.htm" title="Hosts文件使用" target="_blank">Hosts文件使用</a> <span class="text-muted">周凡杨</span> <a class="tag" taget="_blank" href="/search/hosts/1.htm">hosts</a><a class="tag" taget="_blank" href="/search/locahost/1.htm">locahost</a> <div> 一切都要从localhost说起,经常在tomcat容器起动后,访问页面时输入http://localhost:8088/index.jsp,大家都知道localhost代表本机地址,如果本机IP是10.10.134.21,那就相当于http://10.10.134.21:8088/index.jsp,有时候也会看到http: 127.0.0.1:</div> </li> <li><a href="/article/573.htm" title="java excel工具" target="_blank">java excel工具</a> <span class="text-muted">g21121</span> <a class="tag" taget="_blank" href="/search/Java+excel/1.htm">Java excel</a> <div>直接上代码,一看就懂,利用的是jxl: import java.io.File; import java.io.IOException; import jxl.Cell; import jxl.Sheet; import jxl.Workbook; import jxl.read.biff.BiffException; import jxl.write.Label; import </div> </li> <li><a href="/article/700.htm" title="web报表工具finereport常用函数的用法总结(数组函数)" target="_blank">web报表工具finereport常用函数的用法总结(数组函数)</a> <span class="text-muted">老A不折腾</span> <a class="tag" taget="_blank" href="/search/finereport/1.htm">finereport</a><a class="tag" taget="_blank" href="/search/web%E6%8A%A5%E8%A1%A8/1.htm">web报表</a><a class="tag" taget="_blank" href="/search/%E5%87%BD%E6%95%B0%E6%80%BB%E7%BB%93/1.htm">函数总结</a> <div>ADD2ARRAY ADDARRAY(array,insertArray, start):在数组第start个位置插入insertArray中的所有元素,再返回该数组。 示例: ADDARRAY([3,4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7]. ADDARRAY([3,4, 1, 5, 7], "测试&q</div> </li> <li><a href="/article/827.htm" title="游戏服务器网络带宽负载计算" target="_blank">游戏服务器网络带宽负载计算</a> <span class="text-muted">墙头上一根草</span> <a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a> <div>家庭所安装的4M,8M宽带。其中M是指,Mbits/S 其中要提前说明的是: 8bits = 1Byte 即8位等于1字节。我们硬盘大小50G。意思是50*1024M字节,约为 50000多字节。但是网宽是以“位”为单位的,所以,8Mbits就是1M字节。是容积体积的单位。 8Mbits/s后面的S是秒。8Mbits/s意思是 每秒8M位,即每秒1M字节。 我是在计算我们网络流量时想到的</div> </li> <li><a href="/article/954.htm" title="我的spring学习笔记2-IoC(反向控制 依赖注入)" target="_blank">我的spring学习笔记2-IoC(反向控制 依赖注入)</a> <span class="text-muted">aijuans</span> <a class="tag" taget="_blank" href="/search/Spring+3+%E7%B3%BB%E5%88%97/1.htm">Spring 3 系列</a> <div>IoC(反向控制 依赖注入)这是Spring提出来了,这也是Spring一大特色。这里我不用多说,我们看Spring教程就可以了解。当然我们不用Spring也可以用IoC,下面我将介绍不用Spring的IoC。 IoC不是框架,她是java的技术,如今大多数轻量级的容器都会用到IoC技术。这里我就用一个例子来说明: 如:程序中有 Mysql.calss 、Oracle.class 、SqlSe</div> </li> <li><a href="/article/1081.htm" title="高性能mysql 之 选择存储引擎(一)" target="_blank">高性能mysql 之 选择存储引擎(一)</a> <span class="text-muted">annan211</span> <a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/InnoDB/1.htm">InnoDB</a><a class="tag" taget="_blank" href="/search/MySQL%E5%BC%95%E6%93%8E/1.htm">MySQL引擎</a><a class="tag" taget="_blank" href="/search/%E5%AD%98%E5%82%A8%E5%BC%95%E6%93%8E/1.htm">存储引擎</a> <div> 1 没有特殊情况,应尽可能使用InnoDB存储引擎。 原因:InnoDB 和 MYIsAM 是mysql 最常用、使用最普遍的存储引擎。其中InnoDB是最重要、最广泛的存储引擎。她 被设计用来处理大量的短期事务。短期事务大部分情况下是正常提交的,很少有回滚的情况。InnoDB的性能和自动崩溃 恢复特性使得她在非事务型存储的需求中也非常流行,除非有非常</div> </li> <li><a href="/article/1208.htm" title="UDP网络编程" target="_blank">UDP网络编程</a> <span class="text-muted">百合不是茶</span> <a class="tag" taget="_blank" href="/search/UDP%E7%BC%96%E7%A8%8B/1.htm">UDP编程</a><a class="tag" taget="_blank" href="/search/%E5%B1%80%E5%9F%9F%E7%BD%91%E7%BB%84%E6%92%AD/1.htm">局域网组播</a> <div> UDP是基于无连接的,不可靠的传输 与TCP/IP相反 UDP实现私聊,发送方式客户端,接受方式服务器 package netUDP_sc; import java.net.DatagramPacket; import java.net.DatagramSocket; import java.net.Ine</div> </li> <li><a href="/article/1335.htm" title="JQuery对象的val()方法执行结果分析" target="_blank">JQuery对象的val()方法执行结果分析</a> <span class="text-muted">bijian1013</span> <a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/js/1.htm">js</a><a class="tag" taget="_blank" href="/search/jquery/1.htm">jquery</a> <div> JavaScript中,如果id对应的标签不存在(同理JAVA中,如果对象不存在),则调用它的方法会报错或抛异常。在实际开发中,发现JQuery在id对应的标签不存在时,调其val()方法不会报错,结果是undefined。 </div> </li> <li><a href="/article/1462.htm" title="http请求测试实例(采用json-lib解析)" target="_blank">http请求测试实例(采用json-lib解析)</a> <span class="text-muted">bijian1013</span> <a class="tag" taget="_blank" href="/search/json/1.htm">json</a><a class="tag" taget="_blank" href="/search/http/1.htm">http</a> <div> 由于fastjson只支持JDK1.5版本,因些对于JDK1.4的项目,可以采用json-lib来解析JSON数据。如下是http请求的另外一种写法,仅供参考。 package com; import java.util.HashMap; import java.util.Map; import </div> </li> <li><a href="/article/1589.htm" title="【RPC框架Hessian四】Hessian与Spring集成" target="_blank">【RPC框架Hessian四】Hessian与Spring集成</a> <span class="text-muted">bit1129</span> <a class="tag" taget="_blank" href="/search/hessian/1.htm">hessian</a> <div>在【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中介绍了基于Hessian的RPC服务的实现步骤,在那里使用Hessian提供的API完成基于Hessian的RPC服务开发和客户端调用,本文使用Spring对Hessian的集成来实现Hessian的RPC调用。 定义模型、接口和服务器端代码 |---Model &nb</div> </li> <li><a href="/article/1716.htm" title="【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析" target="_blank">【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析</a> <span class="text-muted">bit1129</span> <a class="tag" taget="_blank" href="/search/Mahout/1.htm">Mahout</a> <div>1.Mahout环境搭建 1.下载Mahout http://mirror.bit.edu.cn/apache/mahout/0.10.0/mahout-distribution-0.10.0.tar.gz 2.解压Mahout 3. 配置环境变量 vim /etc/profile export HADOOP_HOME=/home</div> </li> <li><a href="/article/1843.htm" title="nginx负载tomcat遇非80时的转发问题" target="_blank">nginx负载tomcat遇非80时的转发问题</a> <span class="text-muted">ronin47</span> <div> nginx负载后端容器是tomcat(其它容器如WAS,JBOSS暂没发现这个问题)非80端口,遇到跳转异常问题。解决的思路是:$host:port 详细如下: 该问题是最先发现的,由于之前对nginx不是特别的熟悉所以该问题是个入门级别的: ? 1 2 3 4 5 </div> </li> <li><a href="/article/1970.htm" title="java-17-在一个字符串中找到第一个只出现一次的字符" target="_blank">java-17-在一个字符串中找到第一个只出现一次的字符</a> <span class="text-muted">bylijinnan</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a> <div> public class FirstShowOnlyOnceElement { /**Q17.在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b * 1.int[] count:count[i]表示i对应字符出现的次数 * 2.将26个英文字母映射:a-z <--> 0-25 * 3.假设全部字母都是小写 */ pu</div> </li> <li><a href="/article/2097.htm" title="mongoDB 复制集" target="_blank">mongoDB 复制集</a> <span class="text-muted">开窍的石头</span> <a class="tag" taget="_blank" href="/search/mongodb/1.htm">mongodb</a> <div>mongo的复制集就像mysql的主从数据库,当你往其中的主复制集(primary)写数据的时候,副复制集(secondary)会自动同步主复制集(Primary)的数据,当主复制集挂掉以后其中的一个副复制集会自动成为主复制集。提供服务器的可用性。和防止当机问题 mo</div> </li> <li><a href="/article/2224.htm" title="[宇宙与天文]宇宙时代的经济学" target="_blank">[宇宙与天文]宇宙时代的经济学</a> <span class="text-muted">comsci</span> <a class="tag" taget="_blank" href="/search/%E7%BB%8F%E6%B5%8E/1.htm">经济</a> <div> 宇宙尺度的交通工具一般都体型巨大,造价高昂。。。。。 在宇宙中进行航行,近程采用反作用力类型的发动机,需要消耗少量矿石燃料,中远程航行要采用量子或者聚变反应堆发动机,进行超空间跳跃,要消耗大量高纯度水晶体能源 以目前地球上国家的经济发展水平来讲,</div> </li> <li><a href="/article/2351.htm" title="Git忽略文件" target="_blank">Git忽略文件</a> <span class="text-muted">Cwind</span> <a class="tag" taget="_blank" href="/search/git/1.htm">git</a> <div> 有很多文件不必使用git管理。例如Eclipse或其他IDE生成的项目文件,编译生成的各种目标或临时文件等。使用git status时,会在Untracked files里面看到这些文件列表,在一次需要添加的文件比较多时(使用git add . / git add -u),会把这些所有的未跟踪文件添加进索引。 ==== ==== ==== 一些牢骚</div> </li> <li><a href="/article/2478.htm" title="MySQL连接数据库的必须配置" target="_blank">MySQL连接数据库的必须配置</a> <span class="text-muted">dashuaifu</span> <a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/%E8%BF%9E%E6%8E%A5%E6%95%B0%E6%8D%AE%E5%BA%93%E9%85%8D%E7%BD%AE/1.htm">连接数据库配置</a> <div>MySQL连接数据库的必须配置 1.driverClass:com.mysql.jdbc.Driver 2.jdbcUrl:jdbc:mysql://localhost:3306/dbname 3.user:username 4.password:password 其中1是驱动名;2是url,这里的‘dbna</div> </li> <li><a href="/article/2605.htm" title="一生要养成的60个习惯" target="_blank">一生要养成的60个习惯</a> <span class="text-muted">dcj3sjt126com</span> <a class="tag" taget="_blank" href="/search/%E4%B9%A0%E6%83%AF/1.htm">习惯</a> <div>一生要养成的60个习惯 第1篇 让你更受大家欢迎的习惯 1 守时,不准时赴约,让别人等,会失去很多机会。 如何做到: ①该起床时就起床, ②养成任何事情都提前15分钟的习惯。 ③带本可以随时阅读的书,如果早了就拿出来读读。 ④有条理,生活没条理最容易耽误时间。 ⑤提前计划:将重要和不重要的事情岔开。 ⑥今天就准备好明天要穿的衣服。 ⑦按时睡觉,这会让按时起床更容易。 2 注重</div> </li> <li><a href="/article/2732.htm" title="[介绍]Yii 是什么" target="_blank">[介绍]Yii 是什么</a> <span class="text-muted">dcj3sjt126com</span> <a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/yii2/1.htm">yii2</a> <div>Yii 是一个高性能,基于组件的 PHP 框架,用于快速开发现代 Web 应用程序。名字 Yii (读作 易)在中文里有“极致简单与不断演变”两重含义,也可看作 Yes It Is! 的缩写。 Yii 最适合做什么? Yii 是一个通用的 Web 编程框架,即可以用于开发各种用 PHP 构建的 Web 应用。因为基于组件的框架结构和设计精巧的缓存支持,它特别适合开发大型应</div> </li> <li><a href="/article/2859.htm" title="Linux SSH常用总结" target="_blank">Linux SSH常用总结</a> <span class="text-muted">eksliang</span> <a class="tag" taget="_blank" href="/search/linux+ssh/1.htm">linux ssh</a><a class="tag" taget="_blank" href="/search/SSHD/1.htm">SSHD</a> <div>转载请出自出处:http://eksliang.iteye.com/blog/2186931 一、连接到远程主机 格式: ssh name@remoteserver 例如: ssh ickes@192.168.27.211 二、连接到远程主机指定的端口 格式: ssh name@remoteserver -p 22 例如: ssh i</div> </li> <li><a href="/article/2986.htm" title="快速上传头像到服务端工具类FaceUtil" target="_blank">快速上传头像到服务端工具类FaceUtil</a> <span class="text-muted">gundumw100</span> <a class="tag" taget="_blank" href="/search/android/1.htm">android</a> <div>快速迭代用 import java.io.DataOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOExceptio</div> </li> <li><a href="/article/3113.htm" title="jQuery入门之怎么使用" target="_blank">jQuery入门之怎么使用</a> <span class="text-muted">ini</span> <a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/jquery/1.htm">jquery</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/css/1.htm">css</a> <div>jQuery的强大我何问起(个人主页:hovertree.com)就不用多说了,那么怎么使用jQuery呢? 首先,下载jquery。下载地址:http://hovertree.com/hvtart/bjae/b8627323101a4994.htm,一个是压缩版本,一个是未压缩版本,如果在开发测试阶段,可以使用未压缩版本,实际应用一般使用压缩版本(min)。然后就在页面上引用。</div> </li> <li><a href="/article/3240.htm" title="带filter的hbase查询优化" target="_blank">带filter的hbase查询优化</a> <span class="text-muted">kane_xie</span> <a class="tag" taget="_blank" href="/search/%E6%9F%A5%E8%AF%A2%E4%BC%98%E5%8C%96/1.htm">查询优化</a><a class="tag" taget="_blank" href="/search/hbase/1.htm">hbase</a><a class="tag" taget="_blank" href="/search/RandomRowFilter/1.htm">RandomRowFilter</a> <div> 问题描述 hbase scan数据缓慢,server端出现LeaseException。hbase写入缓慢。 问题原因 直接原因是: hbase client端每次和regionserver交互的时候,都会在服务器端生成一个Lease,Lease的有效期由参数hbase.regionserver.lease.period确定。如果hbase scan需</div> </li> <li><a href="/article/3367.htm" title="java设计模式-单例模式" target="_blank">java设计模式-单例模式</a> <span class="text-muted">men4661273</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%8D%95%E4%BE%8B/1.htm">单例</a><a class="tag" taget="_blank" href="/search/%E6%9E%9A%E4%B8%BE/1.htm">枚举</a><a class="tag" taget="_blank" href="/search/%E5%8F%8D%E5%B0%84/1.htm">反射</a><a class="tag" taget="_blank" href="/search/IOC/1.htm">IOC</a> <div> 单例模式1,饿汉模式 //饿汉式单例类.在类初始化时,已经自行实例化 public class Singleton1 { //私有的默认构造函数 private Singleton1() {} //已经自行实例化 private static final Singleton1 singl</div> </li> <li><a href="/article/3494.htm" title="mongodb 查询某一天所有信息的3种方法,根据日期查询" target="_blank">mongodb 查询某一天所有信息的3种方法,根据日期查询</a> <span class="text-muted">qiaolevip</span> <a class="tag" taget="_blank" href="/search/%E6%AF%8F%E5%A4%A9%E8%BF%9B%E6%AD%A5%E4%B8%80%E7%82%B9%E7%82%B9/1.htm">每天进步一点点</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0%E6%B0%B8%E6%97%A0%E6%AD%A2%E5%A2%83/1.htm">学习永无止境</a><a class="tag" taget="_blank" href="/search/mongodb/1.htm">mongodb</a><a class="tag" taget="_blank" href="/search/%E7%BA%B5%E8%A7%82%E5%8D%83%E8%B1%A1/1.htm">纵观千象</a> <div>// mongodb的查询真让人难以琢磨,就查询单天信息,都需要花费一番功夫才行。 // 第一种方式: coll.aggregate([ {$project:{sendDate: {$substr: ['$sendTime', 0, 10]}, sendTime: 1, content:1}}, {$match:{sendDate: '2015-</div> </li> <li><a href="/article/3621.htm" title="二维数组转换成JSON" target="_blank">二维数组转换成JSON</a> <span class="text-muted">tangqi609567707</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84/1.htm">二维数组</a><a class="tag" taget="_blank" href="/search/json/1.htm">json</a> <div>原文出处:http://blog.csdn.net/springsen/article/details/7833596 public class Demo { public static void main(String[] args) { String[][] blogL</div> </li> <li><a href="/article/3748.htm" title="erlang supervisor" target="_blank">erlang supervisor</a> <span class="text-muted">wudixiaotie</span> <a class="tag" taget="_blank" href="/search/erlang/1.htm">erlang</a> <div>定义supervisor时,如果是监控celuesimple_one_for_one则删除children的时候就用supervisor:terminate_child (SupModuleName, ChildPid),如果shutdown策略选择的是brutal_kill,那么supervisor会调用exit(ChildPid, kill),这样的话如果Child的behavior是gen_</div> </li> </ul> </div> </div> </div> <div> <div class="container"> <div class="indexes"> <strong>按字母分类:</strong> <a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a> </div> </div> </div> <footer id="footer" class="mb30 mt30"> <div class="container"> <div class="footBglm"> <a target="_blank" href="/">首页</a> - <a target="_blank" href="/custom/about.htm">关于我们</a> - <a target="_blank" href="/search/Java/1.htm">站内搜索</a> - <a target="_blank" href="/sitemap.txt">Sitemap</a> - <a target="_blank" href="/custom/delete.htm">侵权投诉</a> </div> <div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved. <!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>--> </div> </div> </footer> <!-- 代码高亮 --> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script> <link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/> <script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script> </body> </html>