Python笔试面试题
什么是python
python 诞生于1989年
优点:
- 简单优雅明确
- 强大的模块三方库
- 容易移植
- 面向对象
- 可扩展
缺点:
- 代码不能加密(开源)
- 速度慢(动态语言,解释型语言:比如ruby,PHP等,都需要一句一句解释执行;静态语言,多了一个编译的过程。)
Python的内部执行过程:
https://blog.csdn.net/helloxiaozhe/article/details/78104975
当我们执行Python代码的时候,在Python解释器中用四个过程来拆解我们的代码,最终被CPU执行返回给用户。
1. 用户键入diamante交给Python解释器处理的时候会先进行词法分析(写错单词了没),不正确的代码就不会被执行
2. 语法分析。例如 for i in range(): 最后的:换成其他符号就不会被执行
3. 最关键的过程来了:
在执行python之前,Python解释器会先生成.pyc文件,这个文件就是字节码文件,如果我们不小心修改了字节码文件,python下次编译的时候程序就会和上次生成的字节码进行比较,若不匹配则将被修改的字节码文件进行覆盖,以确保每次编译后字节码的正确性。
what is 字节码?
字节码在Python虚拟机程序里对应的是PyCodeObject对象。.pyc文件是字节码在磁盘上的表现形式。简单来说就是在编译代码的过程中,首先会将代码中的函数、类等对象分类处理,然后生成字节码文件。有了字节码文件,CPU可以直接识别字节码文件进行处理,接着Python就可执行了。
上图:
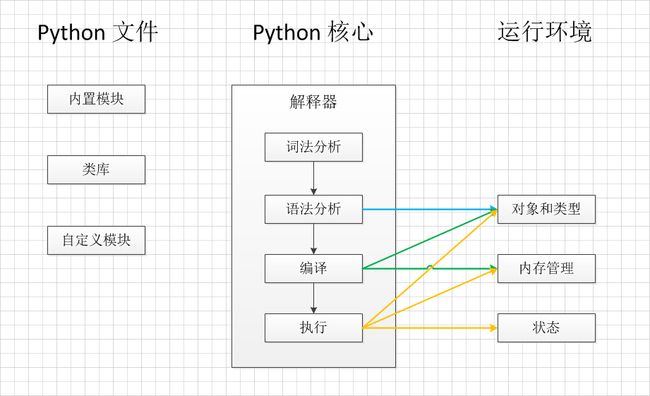
解释型:(对比编译型语言)
解释型是指Python代码是通过Python解释器来将代码解释成计算机硬件能够执行的机器语言。(动态语言)
C编写的代码,则需要通过编译---链接生成exe文件才能变成计算机能够运行的机器语言(静态语言),Python和C在转换成为机器语言的方式有着本质的不同,Python的这种特性称之为解释型。
Python解释器:
.py文件在执行之前会进行两步预处理:
- 编译成为所谓的字节码
- 将字节码发送至虚拟机(虚拟机来执行)
Python解释器通过将每一条源代码分解成为单一步骤来将这些源语句翻译字节码,这些字节码可以提高执行速度,比起源代码中的语句,字节码要快得多。一旦程序编译为字节码,就会被送至Python虚拟机(Python Virtual Machine)中执行
可移植:
python可以扩平台操作,也就是说python程序的核心语言和标准库可以在linux/windows/和其他带有python解释器的平台上无差别的运行。主要归功于以下三个方面:
- Python发行时自带的标准库和模块在实现上也尽可能地考虑到了跨平台的可移植性
- Python程序自动编译成可移植的字节码,这些字节码在已安装兼容版本的Python上运行时一样的
- Pyhton的标准实现是由可移植的ANSI C编写的(ANSI C是C语言发布的标准)
Python是如何进行内存管理的?
现在的高级语言,如java等,都采用了垃圾回收机制,而不是C/C++里用户自己管理内存的方式。
C++的自己管理内存方式十分自由,可以任意申请内存,但是这也如同一把双刃剑,存在着大量内存泄漏,悬空指针等问题
python内存管理:
引用计数(为主) + 标记清除 + 分代收集
引用计数机制:
python里面每一个东西都是对象。对象的核心就是一个结构体:
typedef struct_object{
int ob_refcnt;
struct_typeobject *ob_type;
}PyObject;PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少
当引用计数ob_refcnt=0的时候,该对象的生命就seeyounala了。
#define Py_INCREF(op) ((op)->ob_refcnt++) //增加计数
#define Py_DECREF(op) \ //减少计数
if (--(op)->ob_refcnt != 0) \
; \
else \
__Py_Dealloc((PyObject *)(op))
引用机制的优点:
简单
实时性:
一旦没有了引用,内存直接就被释放掉了。不像其他机制等到特定的时机。
非常重要的一点:处理回收内存的时间被分摊到了平时
缺点:
维护引用计数会消耗资源
循环利用,正是循环利用的存在,python又出现了后面两种机制:标记清除和分代收集
比如
list1 = []
list2 = []
list1.append(list2)
list2.append(list1)list1和list2相互利用,如果不存在其他对象对它们的引用,list1和list2的引用计数仍然为1,无法被回收。这种循环引用导致的内存泄漏,势必要被搞定(标记清除和分代收集)
https://www.jianshu.com/p/1e375fb40506