强化学习之基本核心概念与分类
1.基本概念
-
States and Observations
状态S可以完整地描述外部环境,观察O有可能会遗漏。如果O能够完整地观察S,就是环境就是完全可观察,否则就是部分可观察的 -
Action Spaces
行动空间是所有可以的行动S组成的空间,可以是离散的,也可以是连续的。 -
Policies
策略可以是确定性的,一般表示为μ,也可以是随机的,一般表示为π。 -
Rewards
强化学习中Agent的目标是累积获得最多奖励,一般来说奖励是随着运动轨迹衰减的。从直观上来说,未来的奖励肯定没有现在的奖励好,从数学上来说无衰减约束的奖励可能带来无法收敛的问题。
值函数是对应状态上开始行动,按照某个策略运行下去,最终期望能够获得的奖励。值函数有两个V函数(值函数)和Q函数(行动-值函数),两者的区别是Q函数需要指定执行一个行动a。
MDP过程
MDP就是用来描述RL中的环境,未来只与当前的状态有关,与之前的历史没有关系。MP是一个随机过程。从现在状态 S到下一个状态 S' 通过Pss' 状态转移概率矩阵(State transition probability matrix)来完成这个过程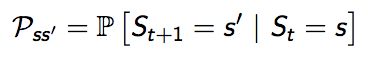 奖励R是环境的反馈,有了R,有了S,有了Pss' 矩阵,实际上我们就能够估算出每一个S上的Gt:E(Gt|St = S)。
奖励R是环境的反馈,有了R,有了S,有了Pss' 矩阵,实际上我们就能够估算出每一个S上的Gt:E(Gt|St = S)。
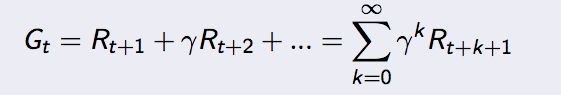
在Q learning中,这就是衰减系数。这个估算出来的Gt就叫做这个状态S上的Sate Value function(状态值函数): v(S)。
MDP则是指马尔可夫决策过程,决策就是在策略policy之后采取的行动。策略也是一个概率分布,体现了在给定状态下采取行动的概率。
Value Function(值函数)


贝尔曼等式
V函数和Q函数都是递归关系,也就是说知道了最终状态v(S最终)就可以倒推到初始状态的v(S初始),这个关系就是用Bellman 等式表达出来的。

最优值函数的贝尔曼等式是:

他们之间有如下关系:

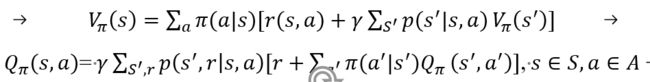

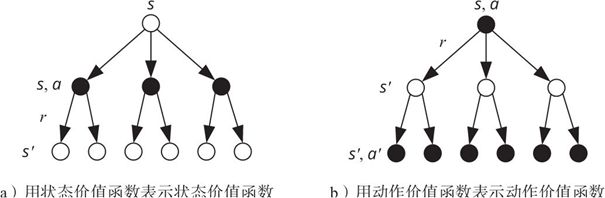
优势函数就是比较在状态s时,执行指定行动a,之后后再服从策略的Qπ(s,a),与一直执行策略Vπ(s)的优势。
数学表达式即为:![]() 优势函数可以是负数,说明在s状态下,指定行动a,并不比在策略π的指导下随机选择一个行动有优势。
优势函数可以是负数,说明在s状态下,指定行动a,并不比在策略π的指导下随机选择一个行动有优势。
如果能求解最优Ballman 等式我们就能得到最优的V函数和Q函数进而得到最优的策略。最优Ballman等式并不是线性的,所以不能直接通过解线性方程的方法求得。但是可以通过一些迭代算法求得比如Q learning和Sarsa算法就是求最优Ballman等式的算法,当然这些算法也就是强化学习的算法了
2.分类
(一)有/无模型学习

有模型学习
(1)基于模型的强化学习:
第一步:从与真实世界互动的经历(Experience)中建立模型。
第二步:在模型中进行学习(可以使用MDP,TD等等所有之前使用的方法) 更新价值函数和策略。
第三步:用学到的价值函数和策略与真实世界进行互动并获得更多的经历。
它可以使用熟悉的监督学习方法,通过模型能够使机器人能够更加深入的理解环境,而不仅局限在最大化奖励本身,换句话说就是机器人能够通过模型具备一定的推理能力。但是整个过程涉及到两个学习过程,一是对模型的学习,二是对价值函数的学习,两个学习都会引入数学近似从而带来双重近似误差,这种误差会导致Agent虽然在模型中表现很好,但是在真实环境中可能打不到预期结果。
1.模型M实际上就是对环境,MDP![]() ,其中
,其中
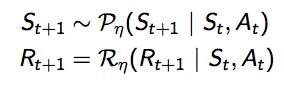
2.通过监督学习的方式建立模型
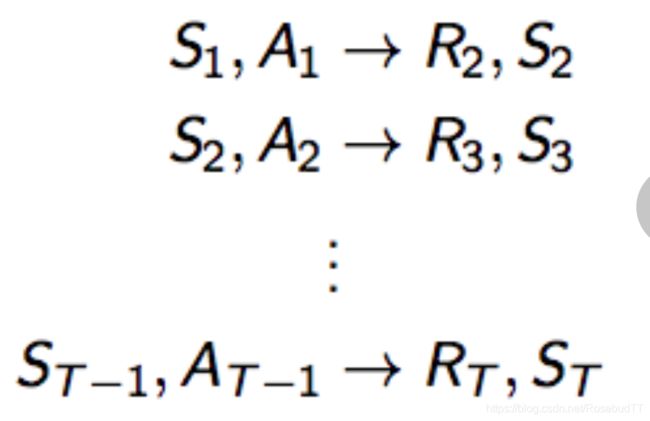
从s, a 学习 r 的过程是一个回归问题(regression problem)
从s, a 学习 s' 的过程是一个密度估计问题(density estimation problem)
模型可以是查表式(Table lookup Model)、线性期望模型(Linear Expectation Model)、线性高斯模型(Linear Gaussian Model)、高斯决策模型(Gaussian Process Model)、和深信度神经网络模型(Deep Belief Network Model)等
选择一个损失函数,比如均方差,KL 散度等,优化参数η来最小化经验损失(empirical loss)。所有监督学习相关的算法都可以用来解决上述两个问题。

这个算法赋予了机器人在与实际环境进行交互式时有一段时间用来思考的能力。其中的步骤:a,b,c,d,和e都是从实际经历中学习,d过程是学习价值函数,e过程是学习模型。
在f步,给以机器人一定时间(或次数)的思考。在思考环节,个体将使用模型,在之前观测过的状态空间中随机采样一个状态,同时从这个状态下曾经使用过的行为中随机选择一个行为,将两者带入模型得到新的状态和奖励,依据这个来再次更新行为价值和函数。
3 基于模型的规划(Planning)
在给定的模型M
纯动态规划(Pure Planning)
Pure Planning 是一个基础的算法,其策略并不显示的表达出来,而是使用规划技术来选择行动。比如 模型预测控制 (model-predictive control, MPC)。在MPC中:
第一步:Agent首先观察环境,并通过模型预测出所有可以行动的路径(路径包含多连续个行动)。
第二步:Agent执行规划的第一个行动,然后立即舍去规划剩余部分。
第三步:重复第一、二步。
Expert Iteration(专家迭代)
这个算法是Pure Planing 的升级版,它将策略显示地表达出来,并通过学习得到这个最优策略π*θ(a|s)
Agent用规划算法(类似于MT树搜索)在模型中通过采样生成候选行动。通过采样生成的行动比单纯通过策略本身生成的行动要好
免模型方法的数据增强
这个方法是将模型采样中生成的数据用来训练Model-Free的策略或者Q函数。训练的数据可以单纯是模型采样生成的,也可以是真实经历的数据与模型采样数据的结合
无模型学习
Policy Optimization
基于策略的强化学习就是参数化策略本身,获得策略函数πθ(a|s), 我们训练策略函数的目标是什么呢?是获得最大奖励。优化策略函数就是优化目标函数可以定义为J(πθ).
Q-Learning
Q-Learning 就是通过学习参数化Q函数Qθ(s,a)从而得* 到最优Q*(s,a)的,典型地方法是优化基于Bellman方程的目标函数。Q-Learning 通常是Off-Policy的,这就意味着训练的数据可以是训练期间任意时刻的数据。
Q-Learning 的经典例子包含DQN和C51。
Policy Optimization和Q-Learning 的权衡与融合
Policy Optimization直接了当地优化你想要的对象(策略),因此Policy Optimization稳定性和可信度都较好,而Q-learning是采用训练Qθ的方式间接优化策略,会遇到不稳定的情况。但是Q-learning的优点是利用数据的效率较高,Policy Optimization和Q-Learning并非水火不相容,有些算法就融合和平衡了两者的优缺点:DDPG, 同时学出一个确定性策略和Q函数,并用他们互相优化。
根据观测数据的时间特性 预测可以分为单步预测和多步预测「基于历史数据预测现在和未来的区别」;关于监督学习和时间差分的区别,传统监督学习是根据预测值和实际观测值的误差来修正预测模型,而TD是根据时间上连续两次预测之间的差值来修正预测误差;具体的来说 前者需要得到全部观测数据后 才能通过计算预测误差来修正预测模型,后者 只需要某两个时刻的预测值和局部观测数据来修正预测模型;所以可以实现在线学习 减少存储量和计算量 有着更高效的学习效率;同时 也可以看出 监督学习只能实现单步学习预测 也就是只能基于当前信息来对于当前时刻的输出进行预测,而TD可以实习多步预测;
时域差分算法 往往被看组学习控制算法 如sarsa和qlearning的一部分 就像多步预测被看做为多步控制的一部分一样。
在上面也提到过学习预测可以看做学习控制的一个子问题,原因也就是在于 常见的强化学习算法的目的毕竟还是为了优化决策求解出来一个合适的行动策略;而学习预测本质上依旧是为了给学习控制提供出来一个评判标准:评判出来当前的优化得到的策略是好亦或是坏;这句话也指明了学习控制本质的作用:求解策略,而学习预测本质目的:求解出来一个评价函数。
另一种分法,本质一样:
除了常见的序贯决策问题之外,本身序贯策略问题基于reward的是否延迟 来源于联想强化学习,同时又有着非联想强化信息;而序贯策略本身为了解决它,采用markov模型来处理,基于指标的不同 还会分为折扣型的和平均型的;在折扣型的里面 基于交互环境的模型是否已知「markov中的转移概率」对于已知的 我们直接采用动态规划来解决这一markov过程;未知的才是我们常见的各类强化学习算法,对于强化学习算法本身,我们根据其中过程可以分为学习预测部分和学习控制部分;紧接着根据问题环境的不同,对于小状态空间 我们采用表格式的方法,大状态空间就是采用值函数近似或者策略梯度的方法;
(二)基于概率/价值
Policy-Based RL
最直接, 可通过感官分析所处的环境, 直接输出下一步要采取的各种动作的概率, 然后根据概率采取行动, 所以每种动作都有可能被选中, 只是可能性不同,可利用概率分布在连续动作中选取特定动作。如Policy Gradients。
Value-Based RL
输出所有动作的价值, 根据最高价值来选择动作,对于选取连续的动作无能为力,如Q learning,Sarsa
结合
Actor-Critic , actor 会基于概率做出动作, 而 critic 会对做出的动作给出动作的价值, 这样就在原有的 policy gradients 上加速了学习过程.
(三)回合/单步更新
回合更新(Monte-Carlo update)
在蒙特卡罗中,如果采用确定性策略,每次试验的轨迹都是一样的,因此无法进一步改进策略。为了使更多状态-动作对参与到交互过程中,即平衡探索和利用,常用ε-greedy策略来产生动作 ,以保证每个状态-动作对都有机会作为初始状态,在评估状态-动作值函数时,需要对每次试验中所有状态-动作对进行估计。
基础版Policy Gradients,Monte-Carlo learning
单步更新/时序差分方法(Temporal-Difference update)
在蒙特卡罗中,如果采用确定性策略,每次试验的轨迹都是一样的,因此无法进一步改进策略。为了使更多状态-动作对参与到交互过程中,即平衡探索和利用,常用ε-greedy策略来产生动作 ,以保证每个状态-动作对都有机会作为初始状态,在评估状态-动作值函数时,需要对每次试验中所有状态-动作对进行估计。
Q learning,Sarsa,升级版Policy Gradients
在此感谢洪滔Hongtao博主