label-embedding在文本分类中的应用

©PaperWeekly 原创 · 作者|蔡杰
学校|北京大学硕士生
研究方向|QA
最近在做文本分类相关的工作,目标是想提高分类器泛化新样本的能力,当有新样本产生的时候能够不需要重新训练分类器。所以挖了挖这个领域的研究,不挖不知道,一挖吓一跳,没想到这个坑还挺深的,看着看着就从普通的分类延续到 few-shot,zero-shot 以及 meta-learning 去了。在这里先介绍几篇与 label-embedding 相关的工作,以后有时间了其他的方法有时间了慢慢码字。

LEAM

论文标题:Joint Embedding of Words and Labels for Text Classification
论文来源:ACL 2018
论文链接:https://arxiv.org/abs/1805.04174
代码链接:https://github.com/guoyinwang/LEAM
1.1 概述
这篇文章作者将文本分类看作是一个 label-word 的联合嵌入问题:可以将每个 label embedding 到 word 向量相同的空间中。
作者提出了一个注意力框架 Label-Embedding Attentive Model (LEAM) 的模型,该模型能够学习 word 和 label 在同一空间的 representation,并且可以用来衡量文本序列和 label 之间 embedding 的兼容性。其中注意力是在标记样本的训练集上学习的,以确保在给定的文本序列中,相关词的权重高于不相关词。
该方法保证了 word-embedding 的可解释性,并具有利用除了输入文本序列之外的其他信息源的能力。
在 Zero-Shot learning 中,label embedding 是一个很经典的方法,通过学习 label embedding,模型可以预测在训练集中未曾出现过的类别。
1.2 方法
首先作者介绍了,一般的方法将文本分类看做以下几个步骤:

f0:将句子 embedding 的过程。L 是序列长度,P 是 embedding 的维度。
f1:将句子 embedding 进行各种操作的过程,一般就是模型(TextCNN,BERT...)。
f2:模型输出之后的 ffn,用于映射到最后的 label 空间。
一般方法在 f1 只利用了来自输入文本序列的信息,而忽略了 label 的信息。作者发现使用标签信息只发生在最后一步 f2,因此作者提出一种新的 pipeline,将label信息纳入每一步,如下图所示:
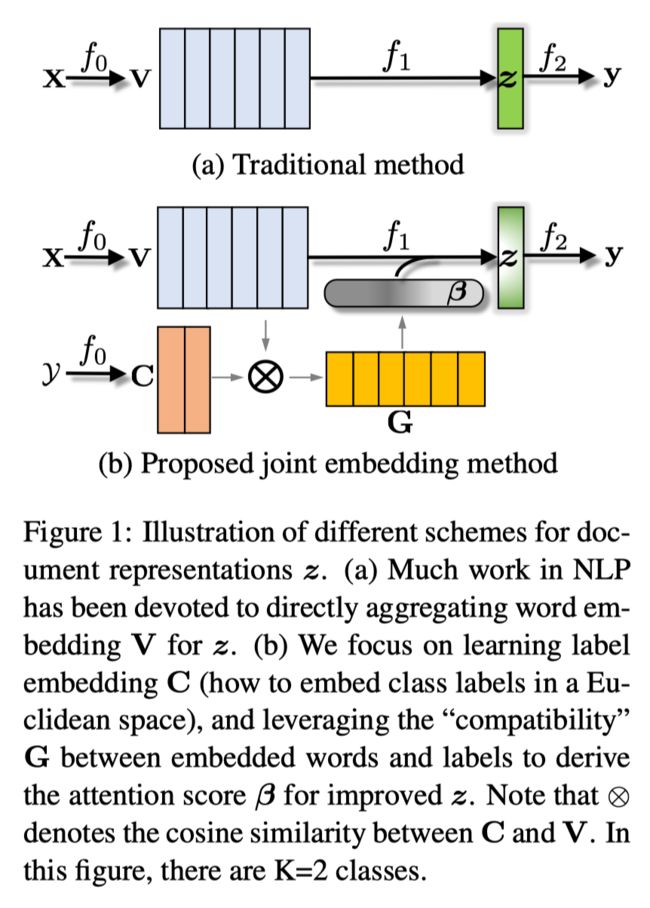
作者提出的方法将文本分类看做以下几个新的步骤:

f0:学习 label 的 embedding 作为“anchor points”来影响 word embedding。
f1:利用 label 和 word 之间的相关性进行 word embedding 的聚合。
f2:保持不变。
V 为 sequence embedding 的矩阵,C 为 label embedding 的矩阵,利用 cosine 相似度计算每个 label-word 之间的相似度:

进一步获取连续词(即连续词)之间的相对空间信息,对于以 l 为中心长度为 2r+1 的文本做如下操作:
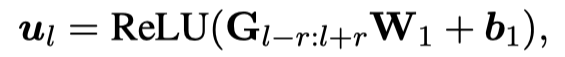
之后利用 max-pooling,可以得到最大相关的系数:

ml 是长度为 l 的向量,整个文本序列的兼容性/注意力得分为:

1.3 实验


MTLE

论文标题:Multi-Task Label Embedding for Text Classification
论文来源:ACL 2018
论文链接:https://arxiv.org/abs/1710.07210
本文作者指出了文本分类的三个缺陷:
缺少 label 信息:每个任务的标签都用独立的、没有意义的单热点向量来表示,例如情绪分析中的正、负,编码为 [1,0] 和 [0,1],可能会造成潜在标签信息的丢失。
不能 scaling(不造咋翻译了,缩放?):网络结构被精心设计来建模多任务学习的各种关联,但大多数网络结构是固定的,只能处理两个任务之间的交互,即成对交互。当引入新的任务时,网络结构必须被修改,整个网络必须再次被训练。
不能迁移:对于人类来说,在学习了几个相关的任务之后,我们可以很容易的就可以处理一个全新的任务,这就是迁移学习的能力。以往大多数模型的网络结构都是固定的,不兼容的,以致于无法处理新的任务。
因此,作者提出了多任务 label embedding (MTLE),将每个任务的 label 也映射到语义向量中,类似于 word embedding 表示单词序列,从而将原始的文本分类任务转化为向量匹配任务。
作者提出了三种模型:

第一种假设对于每个任务,我们只有 N 个输入序列和 C 个分类标签,但是缺少每个输入序列和对应标签的具体标注。在这种情况下,只能以无监督的方式实现 MTLE。包含三个部分:input encoder, label encoder, matcher。两个 encoder 将文本编码成定长的向量。
第一种由于使用了非监督方法,performance 不如有监督的。
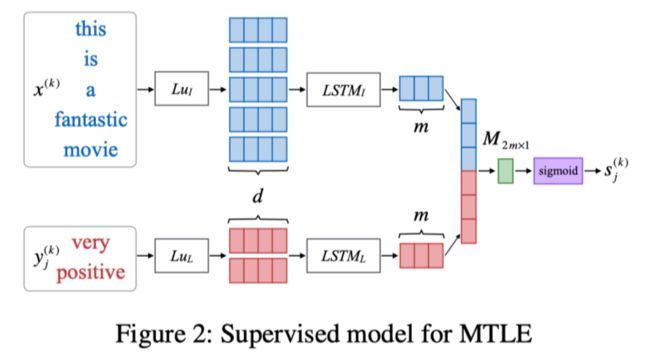

第二种就是有监督的了,两个 LSTM 分别对 label 和句子进行编码,之后分别 concat,过一层全连接( ),得到 logits,个人感觉这个交互做的过于简单。
第三种则是基于 MTLE 的半监督学习模型。
第二种和第三种之间唯一的不同是它们处理新任务的方式。如果新任务有标签,可以选择第二种的 Hot-Update 或 Cold-Update。如果新的任务完全没有标记,仍然可以使用第二种进行向量映射,无需进一步训练就可以为每个输入序列找到最佳的标记(但是还是映射到原来就有的 label 里),作者将其定义为 Zero-Update。
Hot-Update、Cold-Update 和 Zero-Update 之间的区别如下图所示,其中, Before Update 表示在引入新任务之前对旧任务进行训练的模型。

Hot-Update: 在训练过多个 task 的模型基础上进行 finetune。
Cold-Update: 在所有的 tasks 上重新训练。
Zero update: 不更新模型。利用训练过的模型在新 task 上直接得出结果。
实验结果如下:

第二种在多个数据集也碾压了很多当时不错的 model。


EXAM

论文标题:Explicit Interaction Model towards Text Classification
论文来源:AAAI 2019
论文链接:https://arxiv.org/abs/1811.09386
代码链接:https://github.com/NonvolatileMemory/AAAI_2019_EXAM
该文章的 idea 和以上的几篇类似,文本分类中没有充分利用 label 信息的问题,也都指出了对 label 做 encoding 的方法,作者提出了一个新的框架 EXplicit interAction Model (EXAM),加入了 interaction mechanism。
3.1 概述
如下图所示,传统分类的解决方案通过 dot-product 操作将文本级表示与 label 表示匹配。在数学上,FC 层的参数矩阵可以解释为一组类表示(每个列与一个类关联)。
因此,文本属于某个类的概率在很大程度上取决于其整体匹配得分,而与单词级匹配信号无关,单词级匹配信号会为分类提供明确的信号(例如,missile 强烈暗示了军事的主题)。

针对上述情况,作者引入了交互机制,该机制能够将单词级匹配信号纳入文本分类中。交互机制背后的关键思想是显式计算单词和类之间的匹配分数。从单词级别的表示中,它会计算一个交互矩阵,其中每个条目是单词和类(dot-product)之间的匹配得分。
3.2 模型

3.2.1 字级编码器(Encoder),用于将输入文本 d_i 投影到字级表示 H。
Gated Recurrent Unit
Region Embedding 来学习和利用 Ngrams 的任务特定的分布式表示。
3.2.2 交互层(Interaction),用于计算单词和类之间的交互信号的交互层。


3.2.3 聚合层(Aggregation),用于聚合每个类的交互信号并进行最终预测。
该层的设计目的是将每个类的交互特性聚合到一个 logits 中,表示类与输入文本之间的匹配分数。聚合层可以通过不同的方式实现,如 CNN 和 LSTM。但是,为了保持考试的简单性和效率,这里作者只使用了一个具有两个 FC 层的 MLP,其中 ReLU 被用作第一层的激活函数。在形式上,MLP对类的交互特性进行聚合,并计算其关联 logits 如下:

3.2.4 Loss(Cross Entropy)
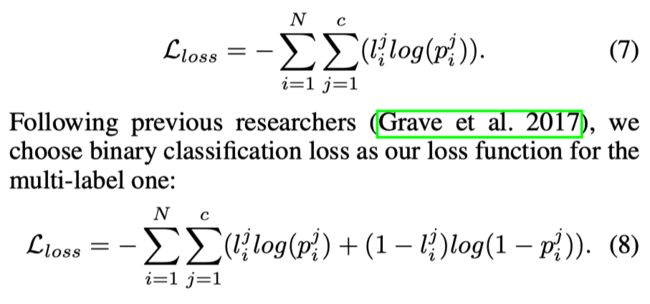
3.3 实验结果

3.4 结论
本文使用交互机制来明确地计算文本分类的单词级交互信号,并将 EXAM 应用于多类和多标签文本分类。对几个基准数据集的实验验证了该机制的有效性。
3.5 相关论文

论文标题:GILE: A Generalized Input-Label Embedding for Text Classification
论文来源:TACL 2019
论文链接:https://arxiv.org/abs/1806.06219
代码链接:https://github.com/idiap/gile
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
