薅百度GPU羊毛!PaddlePaddle大升级,比Google更懂中文,打响AI开发者争夺战

记者 | 阿司匹林
出品 | AI科技大本营(ID: rgznai100)
深度学习已经推动人工智能进入工业大生产阶段,而深度学习框架则是智能时代的操作系统。
在4月23日下午的Wave Summit深度学习开发者峰会上,百度高级副总裁王海峰开场就为深度学习框架PaddlePaddle在百度内部的战略地位进行了定调。
王海峰表示,人类已经经历了三次工业革命:机械技术、电器技术以及信息技术,而这些都是从一个行业开始,然后扩展到各行各业,直到我们生活的各个角落。而这些为我们的生活带来深刻变革的技术往往有很强的通用性,包括标准化、自动化和模块化。如今,我们正进入第四次工业革命——智能时代,而人工智能是第四次工业革命核心驱动力量。
人工智能经历了人工规则、机器学习,而深度学习的出现则带来了很多新的变化,包括语音识别、语音合成、计算机视觉、自然语言处理、机器翻译等等都因为深度学习取得了更好的效果。王海峰认为,深度学习技术已经具备了很强的通用性,正在推动人工智能进入工业大生产阶段,呈现出标准化、自动化和模块化的特点。深度学习框架承上启下,下接芯片、大型计算机系统,上承各种业务模型、行业应用,是智能时代的操作系统。
作为最早研究深度学习技术的公司之一,百度早在2013年即设立了深度学习研究院,并于2016年正式开源深度学习框架,而PaddlePaddle也身负百度抢占人工智能时代高地的重要使命。
在发布几年之后,PaddlePaddle不再与TensorFlow、PyTorch等正面竞争,而是开始强调自己更懂中文,更懂中国开发者,以及更加专注于深度学习模型的工业生产和部署,并给自己取了个中文名「飞桨」。
为笼络开发者,现场百度深度学习技术平台部总监马艳军还宣布了“1亿元” 的AI Studio算力支持计划,为开发者免费提供昂贵的计算资源。
在此次的技术升级中,PaddlePaddle除了发布了11项新特性及服务,还首次展示了PaddlePaddle的全景图和未来的Roadmap,更加凸显了PaddlePaddle的战略地位。
PaddlePaddle全景图
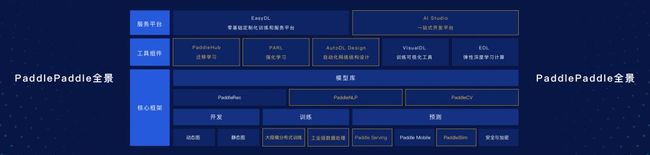
PaddlePaddle可以分为核心框架、工具组件、服务平台。
核心框架支持从开发到训练到预测,以及智能推荐工具集PaddleRec、NLP工具集PaddleNLP、计算机视觉PaddleCV工具集,并且支持超过60个模型。
工具组件则包括预训练模型管理框架PaddleHub,强化学习框架PARL,基于PaddlePaddle的AutoDL技术实现AutoDL Design,数据可视化工具库VisualDL,以及支持弹性深度学习计算的EDL。
服务平台则主要由可定制化训练深度学习模型的EasyDL以及一站式开发平台AI Studio组成。EasyDL目前已经支持图像识别、文本分类、声音分类等深度学习模型的训练,而AI Studio则集合了AI教程、代码环境、算法算力、数据集和比赛,属于百度大脑的深度学习实训平台。
而此次重磅发布的更新则涉及11项新特性及服务,包含PaddleNLP、视频识别工具集、Paddle Serving、PaddleSlim、AutoDL Design等多种深度学习开发、训练、预测环节。
开发环节

PaddleNLP
PaddlePaddle支持CV、NLP以及推荐系统三大类别的一系列模型算法,目前官方能够支持的模型数量已经超过60个,而且已经经过真实业务场景的验证。
PaddleNLP一直是PaddlePaddle的核心组件,囊括了诸多工业级中文NLP算法和模型库,涵盖文本分类、序列标注、语义匹配等多种NLP任务的解决方案,而这一次百度对又PaddleNLP进行了中大升级。
首先,百度把NLP这个领域的模型做了一套共享骨架代码,每一个模型都可以用同一套API和类似的模式,大大降低了操作的复杂程度;其次,这个工具包可以支持主流的中文处理任务,并且能够实现工业级的应用效果。

PaddleNLP由基础网络层和应用任务层构成。基础网络层是表示层,包括语义表示、语言模型、序列标注、文本分类、语义匹配、语言生成与复杂任务等组网集合。
分类组网集:可用于文本分类的深度学习网络结构,输入为文本中每个字、词的ID,输出为文本属于各个类别的概率。包括:BOW、CNN、GRU、LSTM、BiLSTM。
语义表示组网集:可用于文本表示的深度学习网络结构,输入为文本中每个字、词的ID,输出为文本中每个字词的embedding。包括:BERT、ELMo、ERNIE。
语义匹配组网集:可用于计算短文本相似度的深度学习网络结构,输入为两个文本中每个词的ID,输出为二者的相似度得分。包括:BOW、CNN、GRU、LSTM、MMDNN。
序列化标注组网集:可用于计算序列标注的深度学习网络结构,输入为文本中每个字的ID,输出为文本中每个字所属各个标注的概率。目前主要有BiGRU-CRF。
语言模型组网集:可以用于计算句子概率的深度学习网络结构,目前主要有LSTM。
复杂模型组网集:可以处理复杂任务的深度学习网络结构,包括阅读理解、对话等任务。包括:BERT、BiDAF。
基于这些网络结构,同时再配套任务相关的工具和数据,PaddleNLP可以实现一系列的应用任务,包括词法分析、情感分类等,未来百度还会进一步扩充PaddleNLP的能力。
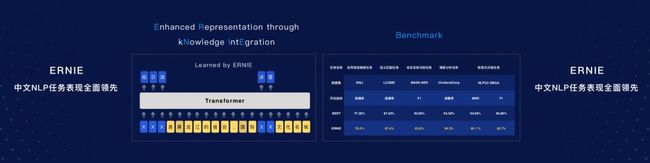
PaddleNLP还集成了百度近期发布的最新语义表示预训练模型——ERNIE。马艳军表示,ERNIE把中文领域处理的一些知识融入到建模的过程当中,从而提升整个语义表示的效果,它很多中文任务上它的Benchmarck都比现在最好的效果要好不少。
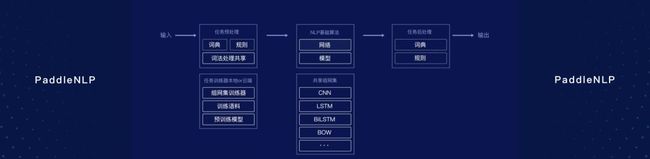
此外,PaddleNLP的另一大亮点则是在模型训练阶段可灵活切换基础网络结构,在任务预测过程中可灵活组合训练好的模型,大大提高了模型开发的灵活性。
视频识别工具集

除了NLP工具集,此次更新的还有视频识别的工具集。这个工具集覆盖当前7个经典的视频分类模型,包括TSN、Non-Local、stNet、TSM、Attention LSTM、Attention Cluster、NextVLAD。这些模型共享同一套配置文件,并且在数据的读取、评估等方面共享一套代码,并使用统一的训练和预测的框架。
据介绍,这些视频理解的技术已经在很多场景下得到了应用,并且已经在诸多百度产品上广泛使用。
训练环节
针对训练环节,PaddlePaddle也发布了两项重要升级:第一是大规模分布式训练的能力升级,第二是工业级数据处理能力的升级。
大规模分布式训练

对于大规模分布式训练,PaddlePaddle推出了三个主要特性:
全方位支持多机多卡,速度提升。
在CPU的应用场景,针对大规模稀疏特征,PaddlePaddle设计并且开放了大规模稀疏参数服务器,开发者可以下载相关的镜像。
大规模分布式训练支持在各种容器上高速运行,如今在K8S这个生态下也可以使用PaddlePaddle进行训练。

针对多机多卡的训练场景,在ResNet50数据集上进行测试,保持精度不变的情况下,FP16的训练速度要比FP32要快很多。此外,PaddlePaddle还做了带宽不敏感的技术,在ResNet50数据集上,带宽不敏感相关的技术在性能和效果方面也有非常出色的表现。
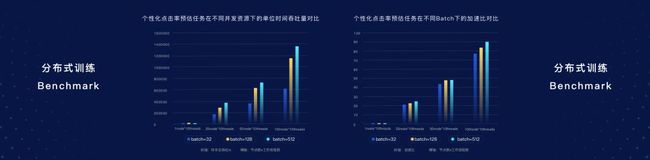
在CPU场景下进行基于个性化点击率预估任务场景测试,可以发现,不同并发资源下单位时间的吞吐量,不同的Batch Size下面加速比,都呈现线性的增长状态,可以直接应用到工业场景。
预测环节
模型在训练和开发完整之后需要部署到各个应用场景,这里面涉及到几个重要环节。首先,我们需要高速的推理引擎;在这个基础之上,为了部署在更多的硬件上,我们常常需要做模型压缩;最后,为了真正投入使用,还需要有相应的硬件。

上图是PaddlePaddle完整的端到端的全流程部署方案。
底层:在服务器端,PaddlePaddle已经支持了比较主流的CPU和GPU;在移动端,PaddlePaddle支持多种CPU和GPU,包括ARM的CPU以及Mali GPU等。对其他硬件的支持也正在快速扩充中。
推理引擎:在底层硬件之上就是推理引擎,一方面是底层的加速库,另外就是在服务器端和移动端做推理的能力。
多语言支持:PaddlePaddle目前已经支持Python、C++,后续还会支持JaveScript等编程语言。
工具:PaddlePaddle这次正式发布的是一整套压缩工具,可以不同的端上把模型压到最小,同时又不损失精度。
方案与服务:此外,PaddlePaddle还提供完整的方案,比如专用的硬件和部署的手册说明等等,方便开发者部署和使用。
推理引擎
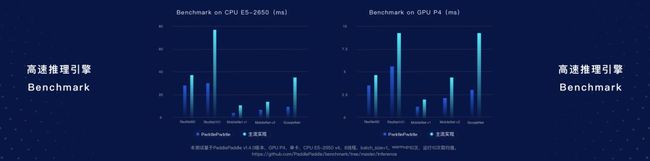
PaddlePaddle在推理引擎方面做了大量工作,能够实现推理加速,提升用户的体验。据介绍,跟某主流框架的对比,在不同的GPU场景下,PaddlePaddle在多个模型推理的速度上展现了非常显著的加速效果。
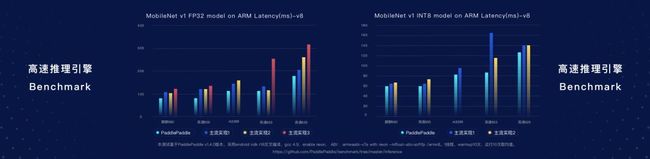
另外,在移动端(ARM处理器),用MobileNet进行测试,PaddlePaddle也实现了很好的效果。
Paddle Serving

针对服务器端,此次PaddlePaddle也终于开放了Serving的能力,可以实现模型从训练到上线服务器的无缝对接。Paddle Serving还内置了诸多模型,可以实现批量预测。其架构图显示,Paddle Serving有离线的准备和在线的实现,另外还有基本的Built-in的一些预处理执行器。
Paddle Serving可以提供非常完备的在线服务能力,包括单服务多个模型,包括多版本的模型A/B Testing,模型的热更新等等这些能力。硬件也是可扩展的,包括CPU、GPU。同时,还有内置了多个模型服务,包括图像分类、文本分类等。
PaddleSlim

在移动端部署深度学习模型常常要考虑模型的大小,因此模型压缩的能力在移动端的场景下是一个刚需。PaddleSlim做了参数集中管理,可以对模型进行自动压缩,并且提升了操作的便利程度,开发者只需要两行Python代码就可以调自动化的模型压缩能力。目前PaddleSlim支持三种主要的压缩能力,包括剪枝、量化以及蒸馏的方法。
工具
除了从开发到训练到部署的全流程,PaddlePaddle还更新了几款工具组件:自动化网络设计工具AutoDL Design,强化学习工具PARL,以及预训练一站式管理工具PaddleHub。
AutoDL Design

AutoDL是一种高效的自动搜索构建最佳网络结构的方法,通过增强学习在不断训练过程中得到定制化高质量的模型。系统由两部分组成,第一部分是网络结构的编码器,第二部分是网络结构的评测器。这次PaddlePaddle发布的AutoDL Design的版本,主要是基于PaddlePaddle和PARL来实现,并且已经开源。
PARL

PaddlePaddle针对强化学习的工具PARL进行了诸多升级,在算法覆盖、高性能通讯以及并行训练方面做了大量的支持和扩展。百度前一段时间在NeurIPS获得AI假尸挑战赛冠军的模型,运用了Target Driven DDPG + Bootstrapping的方法实现,并取得了很好地效果。
PaddleHub

PaddleHub是基于PaddlePaddle开发的预训练模型管理工具,可以借助预训练模型更便捷地开展迁移学习工作。利用这个平台,只需10行左右的代码就可以实现迁移学习,从而在自己的任务场景下使用。
架构图显示,PaddleHub封装了一系列的NLP和CV领域的数据集,同时还在数据的处理方面做了Reader封装。PaddleHub目前已经支持5大类的预训练模型,包括Transformer分析等等,还有几类模型会在后续陆续开放。同时,PaddleHub还支持文本分类、序列标注等任务场景下的迁移,并提供了两种优化策略来提升迁移学习的效果。最后,PaddleHub还提供Finetune API和命令行,保证开发者可以快速使用PaddleHub来做迁移学习。
Roadmap

在2016年百度开源了PaddlePaddle,并且在2017年、2018年的时间内陆续把PaddlePaddle Fluid新一代的深度学习框架做了完善,并发布了稳定的1.0版本。根据PaddlePaddle的Roadmap,7月PaddlePaddle还会发布Fluid动态图分布式训练的功能,以及会新增流水线并行的能力,分布式训练会变得更快。11月PaddlePaddle会实现动态图的能力与静态图的灵活转换,让开发更加便捷,兼顾效率和性能。
2019年7月:
动态图基本功能完善,新增流水线并行能力
提供视觉检测、生成工具集,使用文档全面优化
显存占用优化,静态图训练速度全面提升
优化高速推理引擎,支持在更多硬件的快速扩展,完善支持半精度
2019年11月:
动态图实现与静态图灵活转换,支持高层 API
动态图训练速度全面优化
PaddleHub 升级到 2.0,基于最完备的预训练模型库进行迁移学习
多项行业应用解决方案发布
“1亿元” 笼络人心
想要笼络开发者的心,单靠这些功能更新显然不行,毕竟TensorFlow、PyTorch等已经十分强大。因此百度还推出了“1亿元”的AI Studio算力支持计划。

马艳军介绍,开发者可以免费申请使用工业级应用的一些旗舰型的GPU硬件,这次主要是V100,另外还提供免费、免安装的集成环境,直接上手使用。
具体的使用模式有两种,第一种是一人一卡的模式,包括16G的显存,最高2T的存储空间。第二种是远程集群模式,开发者只要登录AI Studio做预测,就可以免费使用上面的算力资源。
除了免费算力,PaddlePaddle还会提供各种深度学习的培训、认证等等,壮大自己的朋友圈,打造自己的开发者生态,让更多开发者来使用百度云服务,最终实现AI的商业化落地。
2018年7月,李彦宏在百度AI开发者上喊出了要让“Everyone Can AI”的口号,PaddlePaddle具有重要的战略地位。不过,CSDN的《2018-2019中国开发者调查报告》显示,目前国内绝大部分的开发者依然选择主流的深度学习开发框架,PaddlePaddle依然任重道远。
*关注AI科技大本营,后台回复关键字「paddle」获取完整PPT。
(本文为AI科技大本营原创文章,转载请微信联系1092722531)
代码就是力量,长三角的开发者联合起来!
加入「长三角开发者联盟」将获得以下权益
长三角地区明星企业内推岗位
CSDN独家技术与行业报告
CSDN线下活动优先参与权
CSDN线上分享活动优先参与权
我们希望你是:位于长三角地区(上海、江苏、浙江等)优秀开发者。扫码添加联盟小助手,回复关键词“长三角4”,加入「长三角开发者联盟」。

推荐阅读:
特斯拉全新自动驾驶芯片最强?英伟达回怼,投资者用脚投票
用Python实现OpenCV特征提取与图像检索 | Demo
用Python做数据分析,这些基本数据分析技术你知道吗?
Jupyter/IPython笔记本集合 !(附大量资源链接)-上篇
西安奔驰女车主哭诉维权背后, 区块链究竟能否还消费者以尊严?
深入浅出Docker 镜像 | 技术头条
微软 GitHub 旗帜鲜明抵制 996!
源码泄露是裁员报复还是程序员反抗 996?
她说:为啥程序员都特想要机械键盘?这答案我服!

❤点击“阅读原文”,了解更多活动信息。