numpy.random模块常用函数
在Numpy库中,常用使用np.random.rand()、np.random.randn()和np.random.randint()随机函数。
1、 np.random.randn()函数
作用:返回一个或一组服从标准正态分布的随机样本值
1)当函数括号内没有参数时,则返回一个浮点数;
2)当函数括号内有一个参数时,则返回秩为1的数组,不能表示向量和矩阵;
3)当函数括号内有两个及以上参数时,则返回对应维度的数组,能表示向量或矩阵; np.random.randn()的输入通常为整数,但是如果为浮点数,则会自动直接截断转换为整数。

注意:randn()函数没有上下界设置
标准正态分布是以0为均数、以1为标准差的正态分布,记为N(0,1)。对应的正态分布曲线如下所示,即
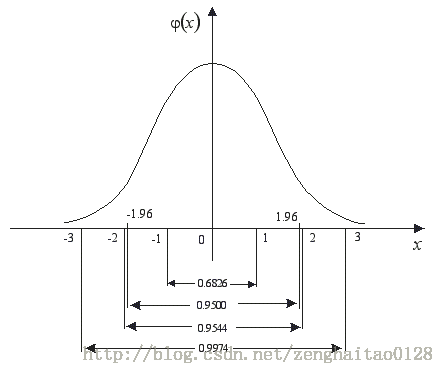
在-1.96~+1.96范围内曲线下的面积等于0.9500(即取值在这个范围的概率为95%),在-2.58~+2.58范围内曲线下面积为0.9900(即取值在这个范围的概率为99%).
因此,由 np.random.randn()函数所产生的随机样本基本上取值主要在-1.96~+1.96之间,当然也不排除存在较大值的情形,只是概率较小而已
2、np.random.rand()函数
np.random.rand(d0,d1,d2……dn)
注:使用方法与np.random.randn()函数相同 ,通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1

3、np..random.uniform(low,high,size)
功能:从指定范围内[low,high)产生均匀分布的随机浮点数,注意定义域是左闭右开,即包含low,不包含high.
参数介绍:
low: 采样下界,float类型,默认值为0;
high: 采样上界,float类型,默认值为1;
size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出m*n*k个样本,缺省时输出1个值。
返回值:ndarray类型,其形状和参数size中描述一致。
4、numpy.random.randint
numpy.random.randint(low, high=None, size=None, dtype='l')
输入:
low—–为最小值
high—-为最大值
size—–为数组维度大小
dtype—为数据类型,默认的数据类型是np.int。
返回值: 返回随机整数或整型数组,范围区间为[low,high),包含low,不包含high; high没有填写时,默认生成随机数的范围是[0,low
>>>np.random.randint(1, size=10)
输出:array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
>>> np.random.randint(5, size=(2, 4))
输出:array([[4, 0, 2, 1],
[3, 2, 2, 0]])4、numpy.random.seed
随机种子生成器,使下一次生成的随机数为由种子数决定的“特定”的随机数,如果seed中参数为空,则生成的随机数“完全”随机:
>>> import numpy as np
>>> np.random.seed(1) #指定生成“特定”的随机数-与seed 1 相关
>>> a = np.random.random()
>>> a
0.417022004702574 #该随机数与seed 1 相关
>>> a = np.random.random() #未指定seed,则本次随机数为完全随机
>>> a
0.7203244934421581 #完全随机数
>>> np.random.seed(1) #再次指定本次随机与seed 1 相关
>>> a = np.random.random()
>>> a
0.417022004702574 #随机数的结果与seed 1相关,与第一次生成的随机数相同
计算机中没有完全的随机数,随机数函数都是通过概率分布来产生随机数,不同的seed函数参数修改概率分布函数中的参数,所以会出来不同的随机值。
from:https://blog.csdn.net/IAMoldpan/article/details/78429165
5、np.random.choice
>>> np.random.choice(5, 3)
array([0, 3, 4])
>>> #This is equivalent to np.random.randint(0,5,3)
a1=np.array([3,5,2.6,41.2,5.7])
a2 = np.random.choice(a=a1, size=3, replace=False, p=[0.2, 0.1, 0.3, 0.4, 0.0])
print(a2)输出: array([41.2, 5. , 2.6])
解释:1、以p的概率,在a中取size个数,p值越大越可能被取到;2、当replace=True时,取值可重复
5 、numpy.random.permutation(x)
返回一个随机排列。随机打乱x中的元素。若x是整数,则打乱arange(x),若x是一个数组,则将copy(x)的第一位索引打乱,意思是先复制x,对副本进行打乱处理,打乱只针对数组的第一维
>>> random.permutation(5)
array([1, 2, 3, 0, 4])
>>> np.random.permutation([1, 4, 9, 12, 15])
array([15, 1, 9, 4, 12])
>>> arr = np.arange(9).reshape((3, 3))
>>> np.random.permutation(arr)
array([[6, 7, 8],
[0, 1, 2],
[3, 4, 5]])6、numpy.random.shuffle(x)
修改序列,改变自身内容。(类似洗牌,打乱顺序),与permutation类似,随机打乱x中的元素。若x是整数,则打乱arange(x). 但是shuffle会对x进行修改
>>> a = arange(5)
>>> a
array([0, 1, 2, 3, 4])
>>> random.permutation(a)
array([1, 4, 3, 2, 0])
>>> a
array([0, 1, 2, 3, 4])
>>> random.shuffle(a)
>>> a
array([4, 1, 3, 2, 0])