本文来自OPPO互联网基础技术团队,转载请注名作者。同时欢迎关注我们的公众号:OPPO_tech,与你分享OPPO前沿互联网技术及活动。
OkHttp应该是目前Android平台上使用最为广泛的开源网络库了,Android 在6.0之后也将内部的HttpUrlConnection的默认实现替换成了OkHttp。
大部分开发的同学可能都有接触过OkHttp的源码,但很少有比较全面的阅读和了解的,目前网络上的大部分源码解析文章也都是点到为止,并且大段的贴源码,这种解析方式是我无法认可的,因此才有了想要重新写一篇解析OkHttp源码的想法。
这篇文章的目的,一个是要比较全面的介绍OkHttp源码,另一个是要尽量避免大段的贴出源码,涉及到源码的部分,会尽量通过调用关系图来展示。
本篇选用的OkHttp源码是目前最新的4.4.0版本,面向的读者也是有一定使用基础的Android开发同学。
OkHttp的源码可以从github上下载到(https://github.com/square/OkHttp)。
直奔主题,文章将从一下几个方面开始来拆解OkHttp的源码:
- 整体结构
- 拦截器
- 任务队列
- 连接复用和连接池
1. 从一个例子出发
首先来看一个最简单的Http请求是如何发送的。
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder().url("https://www.google.com").build();
Response response = client.newCall(request).execute();
return response.body().string();
这一段代码就是日常使用OkHttp最常见的用法,跟进源码后,可以得到一张更为详细的流程图,通过这张图来看下内部的逻辑是如何流动的。
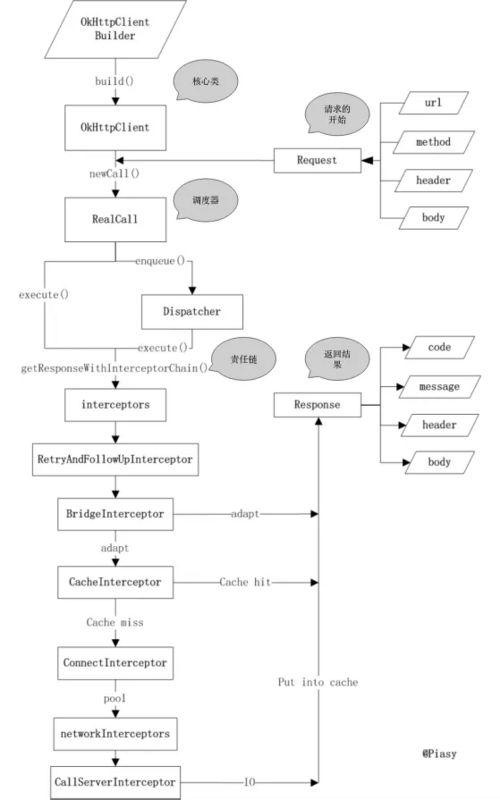
涉及到了几个核心类,我们一个个来看下。
- OkHttpClient
- Request 和 Response
- RealCall
OkHttpClient:这个是整个OkHttp的核心管理类,所有的内部逻辑和对象归OkHttpClient统一来管理,它通过Builder构造器生成,构造参数和类成员很多,这里先不做具体的分析。
Request 和Response:Request是我们发送请求封装类,内部有url, header , method,body等常见的参数,Response是请求的结果,包含code, message, header,body ;这两个类的定义是完全符合Http协议所定义的请求内容和响应内容。
RealCall :负责请求的调度(同步的话走当前线程发送请求,异步的话则使用OkHttp内部的线程池进行);同时负责构造内部逻辑责任链,并执行责任链相关的逻辑,直到获取结果。虽然OkHttpClient是整个OkHttp的核心管理类,但是真正发出请求并且组织逻辑的是RealCall类,它同时肩负了调度和责任链组织的两大重任,接下来我们来着重分析下RealCall类的逻辑。
RealCal类的源码地址:https://github.com/square/OkH...
RealCall类并不复杂,有两个最重要的方法,execute() 和 enqueue(),一个是处理同步请求,一个是处理异步请求。跟进enqueue的源码后发现,它只是通过异步线程和callback做了一个异步调用的封装,最终逻辑还是会调用到execute()这个方法,然后调用了getResponseWithInterceptorChain()获得请求结果。
看来是 getResponseWithInterceptorChain() 方法承载了整个请求的核心逻辑,那么只需要把这个方法分析清楚了,真个OkHttp的请求流程就大体搞明白了。既然这么重要的方法,还是不能免俗的贴下完整的源码。
val interceptors = mutableListOf()
interceptors += client.interceptors
interceptors += RetryAndFollowUpInterceptor(client)
interceptors += BridgeInterceptor(client.cookieJar)
interceptors += CacheInterceptor(client.cache)
interceptors += ConnectInterceptor
if (!forWebSocket) {
interceptors += client.networkInterceptors
}
interceptors += CallServerInterceptor(forWebSocket)
val chain = RealInterceptorChain(interceptors, transmitter, null, 0, originalRequest, this,
client.connectTimeoutMillis, client.readTimeoutMillis, client.writeTimeoutMillis)
var calledNoMoreExchanges = false
try {
val response = chain.proceed(originalRequest)
............ 从源码可以看到,即使是 getResponseWithInterceptorChain() 方法的逻辑其实也很简单,它生成了一个Interceptors拦截器的List列表,按顺序依次将:
- client.Interceptors
- RetryAndFollowUpInterceptor,
- BridgeInterceptor
- CacheInterceptor
- ConnectInterceptor
- client.networkInterceptors
- CallServerInterceptor
这些成员添加到这个List中,然后创建了一个叫RealInterceptorChain的类,最后的Response就是通过chain.proceed获取到的。
通过进一步分析RealInterceptorChain和Interceptors,我们得到了一个结论,OkHttp将整个请求的复杂逻辑切成了一个一个的独立模块并命名为拦截器(Interceptor),通过责任链的设计模式串联到了一起,最终完成请求获取响应结果。
具体这些拦截器是如何串联,每个拦截器都有什么功能,下面的内容会作更详细的分析。
2. OkHttp的核心:拦截器
我们已经知道了OkHttp的核心逻辑就是一堆拦截器,那么它们是如何构造并关联到一起的呢?这里就要来分析RealInterceptorChain这个类了。
通过前面的分析可知,RealCall将Interceptors一个一个添加到List之后 ,就构造生成了一个RealInterceptorChain对象,并调用chain.proceed获得响应结果。那么就来分析下chain.proceed这个方法到底干了啥。为了不让篇幅太长,这里就不贴出源码内容,仅给出分析后的结论,大家对照源码可以很快看懂。
RealInterceptorChain的源码:https://github.com/square/OkH...
根据对RealInterceptorChain的源码解析,可得到如下示意图(省略了部分拦截器):

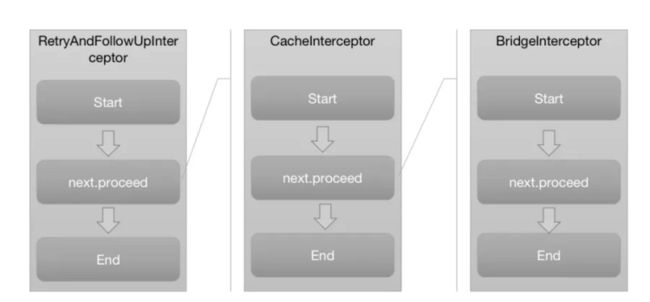
结合源码和该示意图,可以得到如下结论:
- 拦截器按照添加顺序依次执行
- 拦截器的执行从RealInterceptorChain.proceed()开始,进入到第一个拦截器的执行逻辑
- 每个拦截器在执行之前,会将剩余尚未执行的拦截器组成新的RealInterceptorChain
- 拦截器的逻辑被新的责任链调用next.proceed()切分为start、next.proceed、end这三个部分依次执行
- next.proceed() 所代表的其实就是剩余所有拦截器的执行逻辑
- 所有拦截器最终形成一个层层内嵌的嵌套结构
了解了上面拦截器的构造过程,我们再来一个个的分析每个拦截器的功能和作用。
从这张局部图来看,总共添加了五个拦截器(不包含自定义的拦截器如client.interceptors和client.networkInterceptors,这两个后面再解释)。
先来大概的了解下每一个拦截器的作用
- retryAndFollowUpInterceptor——失败和重定向拦截器
- BridgeInterceptor——封装request和response拦截器
- CacheInterceptor——缓存相关的过滤器,负责读取缓存直接返回、更新缓存
- ConnectInterceptor——连接服务,负责和服务器建立连接 这里才是真正的请求网络
- CallServerInterceptor——执行流操作(写出请求体、获得响应数据) 负责向服务器发送请求数据、从服务器读取响应数据 进行http请求报文的封装与请求报文的解析
下面就来一个个的拦截器进行分析。
2.1 RetryAndFollowUpInterceptor
源码地址:https://github.com/square/OkH...
根据源码的逻辑走向,直接画出对应的流程图(这段逻辑在RetryAndFollowUpInterceptor的intercept()方法内部):
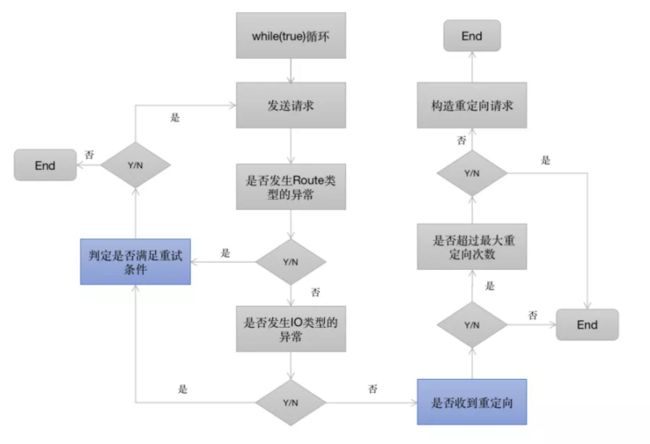
从上图中可以看出,RetryAndFollowUpInterceptor开启了一个while(true)的循环,并在循环内部完成两个重要的判定,如图中的蓝色方框:
- 当请求内部抛出异常时,判定是否需要重试
- 当响应结果是3xx重定向时,构建新的请求并发送请求
重试的逻辑相对复杂,有如下的判定逻辑(具体代码在RetryAndFollowUpInterceptor类的recover方法):
- 规则1: client的retryOnConnectionFailure参数设置为false,不进行重试
- 规则2: 请求的body已经发出,不进行重试
- 规则3: 特殊的异常类型不进行重试(如ProtocolException,SSLHandshakeException等)
- 规则4: 没有更多的route(包含proxy和inetaddress),不进行重试
前面这四条规则都不符合的条件下,则会重试当前请求。重定向的逻辑则相对简单,这里就不深入了。
2.2 Interceptors和NetworkInterceptors的区别
前面提到,在OkHttpClient.Builder的构造方法有两个参数,使用者可以通过addInterceptor 和 addNetworkdInterceptor 添加自定义的拦截器,分析完 RetryAndFollowUpInterceptor 我们就可以知道这两种自动拦截器的区别了。
从前面添加拦截器的顺序可以知道 Interceptors 和 networkInterceptors 刚好一个在 RetryAndFollowUpInterceptor 的前面,一个在后面。
结合前面的责任链调用图可以分析出来,假如一个请求在 RetryAndFollowUpInterceptor 这个拦截器内部重试或者重定向了 N 次,那么其内部嵌套的所有拦截器也会被调用N次,同样 networkInterceptors 自定义的拦截器也会被调用 N 次。而相对的 Interceptors 则一个请求只会调用一次,所以在OkHttp的内部也将其称之为 Application Interceptor。
2.3 BridgeInterceptor 和 CacheInterceptor
BridageInterceptor 拦截器的功能如下:
- 负责把用户构造的请求转换为发送到服务器的请求 、把服务器返回的响应转换为用户友好的响应,是从应用程序代码到网络代码的桥梁
- 设置内容长度,内容编码
- 设置gzip压缩,并在接收到内容后进行解压。省去了应用层处理数据解压的麻烦
- 添加cookie
- 设置其他报头,如User-Agent,Host,Keep-alive等。其中Keep-Alive是实现连接复用的必要步骤
CacheInterceptor 拦截器的逻辑流程如下:
- 通过Request尝试到Cache中拿缓存,当然前提是OkHttpClient中配置了缓存,默认是不支持的。
- 根据response,time,request创建一个缓存策略,用于判断怎样使用缓存。
- 如果缓存策略中设置禁止使用网络,并且缓存又为空,则构建一个Response直接返回,注意返回码=504
- 缓存策略中设置不使用网络,但是又缓存,直接返回缓存
- 接着走后续过滤器的流程,chain.proceed(networkRequest)
- 当缓存存在的时候,如果网络返回的Resposne为304,则使用缓存的Resposne。
- 构建网络请求的Resposne
- 当在OkHttpClient中配置了缓存,则将这个Resposne缓存起来。
- 缓存起来的步骤也是先缓存header,再缓存body。
- 返回Resposne
接下来的两个应该是所有内部拦截器里最重要的两个了,一个负责处理Dns和Socket连接,另一个则负责Http请求体的发送。
2.4 ConnectInterceptor
上面已经提到了,connectInterceptor应该是最重要的拦截器之一了,它同时负责了Dns解析和Socket连接(包括tls连接)。
源码地址:https://github.com/square/OkH...
这个类本身很简单,从源码来看,关键的代码只有一句。
val exchange = transmitter.newExchange(chain, doExtensiveHealthChecks)从Transmitter获得了一个新的ExChange的对象,这句简单的代码仔细跟进去以后,会发现其实埋藏了非常多的逻辑,涉及整个网络连接建立的过程,其中包括dns过程和socket连接的过程,这里我们通过两个图来了解下整个网络连接的过程。
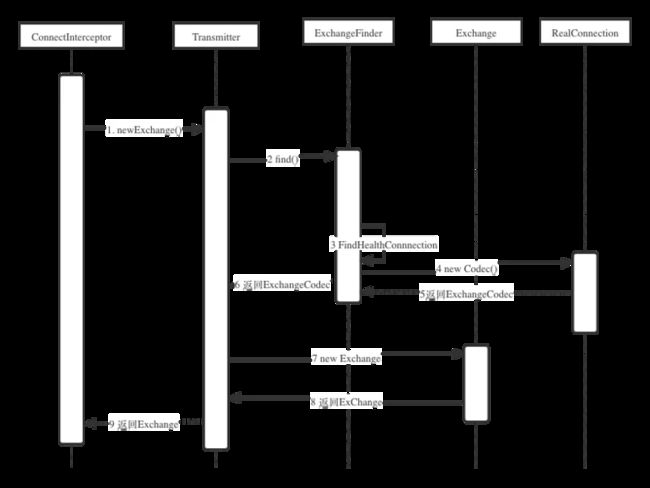
先来看方法调用的时序图,梳理出关键步骤:
- ConnectInterceptor调用transmitter.newExchange
- Transmitter先调用ExchangeFinder的find()获得ExchangeCodec
- ExchangeFinder调用自身的findHealthConnectio获得RealConnection
- ExchangeFinder通过刚才获取的RealConnection的codec()方法获得ExchangeCodec
- Transmitter获取到了ExchangeCodec,然后new了一个ExChange,将刚才的ExchangeCodec包含在内
通过刚才的5步,最终Connectinterceptor通过Transmitter获取到了一个Exchange的类,这个类有两个实现,一个是Http1ExchangeCodec,一个是Http2Exchangecodec,分别对应的是Http1协议和Http2协议。
那么获取到Exchange类有什么用呢?再来看这几个类的关系图,如下:
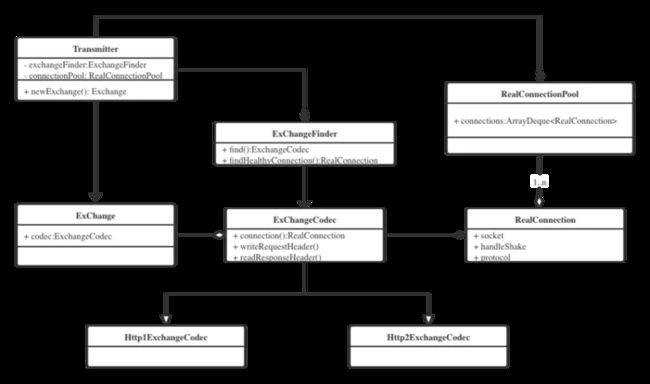
从上面可以看到,前面获得的Exchange类里面包含了ExchangeCodec对象,而这个对象里面又包含了一个RealConnection对象,RealConnection的属性成员有socket、handlShake、protocol等,可见它应该是一个Socket连接的包装类,而ExchangeCode对象是对RealConnection操作(writeRequestHeader、readResposneHeader)的封装。
通过这两个图可以很清晰的知道,最终获得的是一个已经建立连接的Socket对象,也就是说,在ConnectInterceptor内部已经完成了socket连接,那么具体是哪一步完成的呢?
看上面的时序图,可以知道,获得RealConnection的ExchangeFinder调用的findHealthConnection()方法,因此,socket连接的获取和建立都是在这里完成的。
同样,在socket进行连接之前,其实还有一个dns的过程,也是隐含在findHealthConnection 里的内部逻辑,详细的过程在后面DNS的过程再进行分析,这里ConnectionInterceptor的任务已经完成了。
另外还需要注意的一点是,在执行完ConnectInterceptor之后,其实添加了自定义的网络拦截器networkInterceptors,按照顺序执行的规定,所有的networkInterceptor执行执行,socket连接其实已经建立了,可以通过realChain拿到socket做一些事情了,这也就是为什么称之为network Interceptor的原因。
2.5 CallServerInterceptor
CalllServerInterceptor是最后一个拦截器了,前面的拦截器已经完成了socket连接和tls连接,那么这一步就是传输http的头部和body数据了。
CallServerInterceptor源码:https://github.com/square/OkH...
CallServerInterceptor由以下步骤组成:
- 向服务器发送 request header
- 如果有 request body,就向服务器发送
- 读取 response header,先构造一个 Response 对象
- 如果有 response body,就在 3 的基础上加上 body 构造一个新的 Response 对象
这里我们可以看到,核心工作都由 HttpCodec 对象完成,而 HttpCodec 实际上利用的是 Okio,而 Okio 实际上还是用的 Socket,只不过一层套一层,层数有点多。
3. 整体架构
至此为止,所有的拦截器都讲完了,我们已经知道了一个完整的请求流程是如何发生的。那么这个时候再来看OkHttp的架构图就比较清晰了
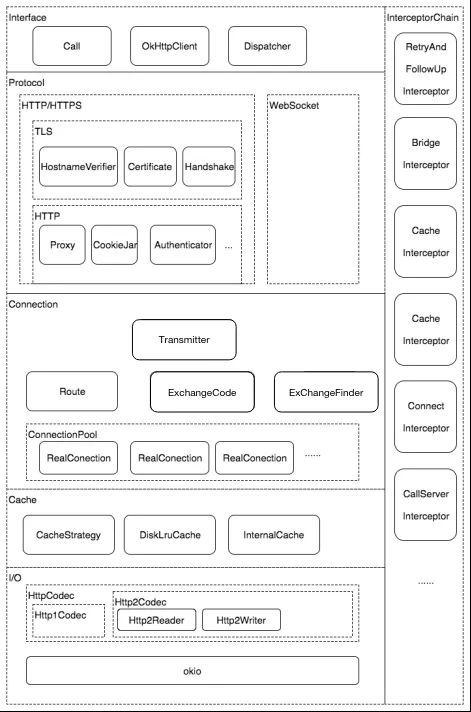
整个OkHttp的架构纵向来看就是五个内部拦截器,横向来看被切分成了几个部分,而纵向的拦截器就是通过对横向分层的调用来完成整个请求过程,从这两个方面来把握和理解OkHttp就比较全面了。
针对横向的部分将在接下来的部分进行详细分析。
3.1 连接复用,DNS和Socket的连接
通过前面的分析知道,Socket连接和Dns过程都是在ConnecInterceptor中通过Transmitter和ExchangeFinder来完成的,而在前面的时序图中可以看到,最终建立Socket连接的方法是通过ExchangeFinder的findConnection来完成的,可以说一切秘密都是findConnection方法中。
因此接下来详细解析下findConnection(),这里贴出源码和注释。
synchronized(connectionPool) {
//前面有一大段判定当前的conencection是否需要释放,先删除
.....
if (result == null) {
// 1, 第一次尝试从缓冲池里面获取RealConnection(Socket的包装类)
if (connectionPool.transmitterAcquirePooledConnection(address, transmitter, null, false)) {
foundPooledConnection = true
result = transmitter.connection
} else if (nextRouteToTry != null) {
//2, 如果缓冲池中没有,则看看有没有下一个Route可以尝试,这里只有重试的情况会走进来
selectedRoute = nextRouteToTry
nextRouteToTry = null
} else if (retryCurrentRoute()) {
//3,如果已经设置了使用当前Route重试,那么会继续使用当前的Route
selectedRoute = transmitter.connection!!.route()
}
}
}
if (result != null) {
// 4,如果前面发现ConnectionPool或者transmiter中有可以复用的Connection,这里就直接返回了
return result!!
}
// 5, 如果前面没有获取到Connection,这里就需要通过routeSelector来获取到新的Route来进行Connection的建立
var newRouteSelection = false
if (selectedRoute == null && (routeSelection == null || !routeSelection!!.hasNext())) {
newRouteSelection = true
//6,获取route的过程其实就是DNS获取到域名IP的过程,这是一个阻塞的过程,会等待DNS结果返回
routeSelection = routeSelector.next()
}
var routes: List? = null
synchronized(connectionPool) {
if (newRouteSelection) {
// Now that we have a set of IP addresses, make another attempt at getting a connection from
// the pool. This could match due to connection coalescing.
routes = routeSelection!!.routes
//7,前面如果通过routeSelector拿到新的Route,其实就是相当于拿到一批新的IP,这里会再次尝试从ConnectionPool
// 中检查是否有可以复用的Connection
if (connectionPool.transmitterAcquirePooledConnection( address, transmitter, routes, false)) {
foundPooledConnection = true
result = transmitter.connection
}
}
if (!foundPooledConnection) {
if (selectedRoute == null) {
//8,前面我们拿到的是一批IP,这里通过routeSelection获取到其中一个IP,Route是proxy和InetAddress的包装类
selectedRoute = routeSelection!!.next()
}
// Create a connection and assign it to this allocation immediately. This makes it possible
// for an asynchronous cancel() to interrupt the handshake we're about to do.
//9,用新的route创建RealConnection,注意这里还没有尝试连接
result = RealConnection(connectionPool, selectedRoute!!)
connectingConnection = result
}
}
// If we found a pooled connection on the 2nd time around, we're done.
// 10,注释说得很清楚,如果第二次从connectionPool获取到Connection可以直接返回了
if (foundPooledConnection) {
eventListener.connectionAcquired(call, result!!)
return result!!
}
// Do TCP + TLS handshakes. This is a blocking operation.
//11,原文注释的很清楚,这里是进行TCP + TLS连接的地方
result!!.connect(
connectTimeout,
readTimeout,
writeTimeout,
pingIntervalMillis,
connectionRetryEnabled,
call,
eventListener
)
//后面一段是将连接成功的RealConnection放到ConnectionPool里面,这里就不贴出来了
}
return result!! 从上面的流程可以看到,findConnection这个方法做了以下几件事:
- 检查当前exchangeFinder所保存的Connection是否满足此次请求
- 检查当前连接池ConnectionPool中是否满足此次请求的Connection
- 检查当前RouteSelector列表中,是否还有可用Route(Route是proxy,IP地址的包装类),如果没有就发起DNS请求
- 通过DNS获取到新的Route之后,第二次从ConnectionPool查找有无可复用的Connection,否则就创建新的RealConnection
- 用RealConnection进行TCP和TLS连接,连接成功后保存到ConnectionPool
Connection的连接复用
可以看到,第二步和第四步对ConnectionPool做了两次复用检查,第五步创建了新的RealConnection之后就会写会到ConnectionPool中。
因此这里就是OkHttp的连接复用其实是通过ConnectionPool来实现的,前面的类图中也反映出来,ConnectionPool内部有一个connections的ArrayDeque对象就是用来保存缓存的连接池。
DNS过程
从前面解析的步骤可知,Dns的过程隐藏在了第三步RouteSelector检查中,整个过程在findConnection方法中写的比较散,可能不是特别好理解,但是只要搞明白了RouteSelector, RouteSelection,Route这三个类的关系,其实就比较容易理解了,如下图中展示了三个类之间的关系。

从图中可以得到如下结论:
- RouteSelector在调用next遍历在不同proxy情况下获得下一个Selection封装类,Selection持有一个Route的列表,也就是每个proxy都对应有Route列表
- Selection其实就是针对List
封装的一个迭代器,通过next()方法获得下一个Route,Route持有proxy、address和inetAddress,可以理解为Route就是针对IP和Proxy配对的一个封装 - RouteSelector的next()方法内部调用了nextProxy(), nextProxy()又会调用resetNextInetSocketAddres()方法
- resetNextInetSocketAddres通过address.dns.lookup获取InetSocketAddress,也就是IP地址
通过上面一系列流程知道,IP地址最终是通过address的dns获取到的,而这个dns又是怎么构建的呢?
反向追踪代码,定位到address的dns是transmitter在构建address的时候,将内置的client.dns传递进来,而client.dns是在OkHttpclient的构建过程中传递进来Dns.System,里面的lookup是通过InetAddress.getAllByName 方法获取到对应域名的IP,也就是默认的Dns实现。
至此,整个DNS的过程就真相大白了。OkHttp在这一块设计的时候,为了强调接耦和开放性,将DNS的整个过程隐藏的比较深,如果不仔细debug跟代码的话,可能还不是很容易发现。
3.2 Socket连接的建立
通过Dns获得Connectoin之后,就是建立连接的过程了,在findConnection中只体现为一句代码,如下:
result!!.connect(
connectTimeout,
readTimeout,
writeTimeout,
pingIntervalMillis,
connectionRetryEnabled,
call,
eventListener
)这里的result是RealConnection类型的对象,就是调用了RealConnection.connect方法,终于离开findConnection 了,接下来看下connect 方法的源码。
//省略前面一大段
....
while (true) {
try {
if (route.requiresTunnel()) {
//这里进入的条件是,通过http代理了https请求,有一个特殊的协议交换过程
connectTunnel(connectTimeout, readTimeout, writeTimeout, call, eventListener)
} else {
//建立socket连接
connectSocket(connectTimeout, readTimeout, call, eventListener)
}
//如果前面判定是https请求,这里就是https的tls建立过程
establishProtocol(connectionSpecSelector, pingIntervalMillis, call, eventListener)
break
} catch (e: IOException) {
//清理资源
socket?.closeQuietly()
//对异常做二次封装,然后抛出
if (routeException == null) {
routeException = RouteException(e)
} else {
routeException.addConnectException(e)
}
if (!connectionRetryEnabled || !connectionSpecSelector.connectionFailed(e)) {
throw routeException
}
}
}connect方法并不复杂,先会判定是否有代理的情况做一些特殊处理,然后调用系统方法建立socket连接。
如果是https请求,还有一个tls的连接要建立,这中间如果有抛出异常,会做一个二次封装再抛出去。
4. 总结
到此为止,基本上OkHttp源码设计的一个全貌都有了,有一些内容因为日常使用经常会遇到,比如OkHttpClient的Builde参数,比如Request和Response的用法,这里就不再多讲。另外针对http2和https的支持,因为涉及到更为复杂的机制和原理,以后有机会另开一篇文章来说。