本文来自OPPO互联网基础技术团队,转载请注名作者。同时欢迎关注我们的公众号:OPPO_tech,与你分享OPPO前沿互联网技术及活动。
有的人可以徒手推导机器学习算法公式,可以深入源码了解算法的实现,又或者在Kaggle比赛中获得不错的名次,但在实际的项目中却走得“步履蹒跚”,究其根本原因是机器学习知识体系还不完善。
例如我们的用户兴趣标签生产系统中,需要考虑的问题有:如何做好特征工程、如何获取高质量的正负样本、怎样处理不平衡数据集、确定怎样的评估方式、选择什么算法、如何调参、解释模型。
算法直接相关的经验是最容易从书本或网上获取的,其他的则跟自身业务联系紧密,网上相关分享较少,这方面的经验知识获取相对难一些,一般都是靠项目实操积累起来。更不幸的是,这些不好获取的经验知识在现阶段项目中又是最重要的——相比于算法选择与调参,对建模数据集的优化获得的增益大的多。
本文将结合标签项目来分享一些实操经验,文章分为两大部分:第一部分介绍通用模块,包括特征工程、构建评测集、确定评估方式;第二部分介绍与算法相关的模块,包括算法选择、特征处理、调参(spark和sklearn平台)、模型解释。
1. 特征、样本工程
1.1 特征工程
特征工程主要包括:
特征使用方案
基于业务尽可能从有关的数据源提取特征,以及对这些特征的可用性评估(覆盖率、准确率等)。
特征获取方案
主要考虑如何获取和存储特征。
特征监控
监控重要特征,防止特征质量下滑影响模型。
特征处理
是特征工程最核心的部分,包含了特征清洗、特征转换、特征选择等操作。
可见,特征工程是庞杂的,特别是在大数据场景下一些常规操作甚至会出现性能问题——就要到deadline了,而自己还卡在工程问题上,这是无法容忍的。
所以我们的特征工程平台OFeature应运而生,其致力于解决特征工程一致性问题、易用性问题和性能问题,将使用者从工程“沼泽”中彻底解放,获取建模数据集的过程变得十分简洁。
下图直观地展示了高质量的建模数据集主要由丰富的特征集合、恰当的特征处理和高质量label组成,其中特征处理跟选择的算法有关,本文将放到算法章节介绍,本章只介绍获取特征和label的一些经验。

图1 使用OFeature获取建模数据集过程
1.1.1 特征集合
拥有怎样的特征集合跟行业乃至项目紧密相关,下面以互联网广告为例,其特征大致分为以下几类:
用户属性
年龄、性别、学历、职业、地域等
行为偏好
一般通过统计历史行为数据得到(也可以用模型预测得到),如统计用户近一个月付费情况来确定他的付费偏好
行为意向
某用户之前没有被曝光过或没有点击过母婴产品广告,但最近开始在浏览器中查询母婴相关的内容,那么他很有可能就是母婴产品广告主的目标人群。我们的行为意向特征主要有“信息流内容曝光点击行为”和“浏览器query”两大类
行为模式
所谓行为模式是指通过分析消费者的行为与时间、空间的关系,以及一系列行为之间的时间和空间序列关系,总结出的具有一定一致性意义的行为表现,通过这些一致性模式预测相关行为[1]。下图所示:假设我们有3类APP,然后周聚合统计用户USER1为B付费的次数(类似的有曝光、点击、下载、注册),最终把多周和多APP拼接起来
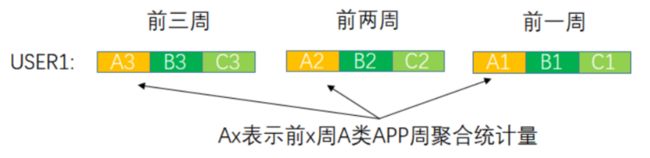
图2 用户游戏行为序列
1.1.2 Label
label的获取跟具体业务有关:
“定制标签”业务
建模者可根据业务需求选择正负样本,例如可将某类APP的有转化人群作为正样本,将曝光未转化的人群作为负样本。
LookAlike
由于种子包(正样本)可能由第三方提供,与之对应的负样本也无法确定,所以这是一个典型的PU learning(Positive and unlabeled learning)问题,这时需要尝试各种候选集(比如全量用户、信息流活跃用户、游戏活跃用户或他们之间的交集等)来作为负样本,同时使用PU learning相关算法(如Spy Technique)进一步提取质量更高的负样本,最终对比各方案确定最优负样本。
考虑到曝光和点击(下载、注册、付费)的关系,数据集的正负样本往往是极不平衡的,在此情况下测试集仍然需要采用真实分布(不平衡数据),而训练集需要使用一些技术处理不平衡数据。
例如当正样本充足时,对负样本进行降采样,否则需要使用smote技术扩充正样本,验证集也建议使用真实分布,但做K-FOLD时比较麻烦,所以当验证集使用真实分布时,建议使用early-stopping调参。
最后需要注意的是有些特征是历史数据统计量,所以label的时间一定要在feature后面,以防特征泄露。
1.2 构建评测集和确定评估指标
1.2.1 评测集
要评估特征工程或算法调参对模型的影响,就需要找出一些具有代表性的评测集,如果大部分评测集指标变好,我们就认为是对模型做了正向优化。具有代表性的评测集:
从业务上分类
分为“标签业务”和LookAlike,在“标签业务”中我们又划分了游戏和非游戏评测集
从量级上分类
一般是指LookAlike的种子量级。这是因为第三方提供的包量级常常相差很大,考虑到这一点,我们必须要根据实际情况,选出一些种子量级具有代表性的评测集
1.2.2 评估指标
前文提到的特征工程、label选择、重采样比例以及下文将提到的算法调参,都需要统一指标评判。
首先,最令人信服的指标当然是线上指标,但由于线上评估代价太大,不可能每次更新都上线测试,所以一般策略是当离线指标明显变好后再上线测试。本文接下来只介绍离线评估指标的制定,离线评估指标可分为两大类,下图所示。

图3 离线评估指标
模型内在指标
precision、recall、F1等指标都是先确定了阈值,然后从相应的混淆矩阵计算得到。而auc、aupr指标是不需要人工确定阈值:用每个点作为阈值,且每个阈值对应坐标一个点,最后计算图形总的面积。总之要根据实际业务来选择,比如我们LookAlike任务往往关注的是排名(即预测概率排在前面的转化比排后面的好就行了),这时候需要用auc和aupr来评估(对于不平衡数据集推荐使用aupr)。
又比如标签任务是想找到真正对“XX游戏”感兴趣的人群,我们就可以设定一个阈值来决定某用户是否真的感兴趣,所以模型对人群的预测概率值变得重要,另外调参阶段也应该使用logloss作为early-stopping的准则。
业务指标
- 交集指标:
一种常用的做法就是将标签广告历史曝光人群与标签包做交集,然后比较历史指标和交集的指标,例如模型预测了历史20200101这天全量人群,然后根据预测分数倒排并取topK作为“XX游戏”标签包,然后将标签包和20200101这天“XX游戏”实际曝光的人群做交集,最后统计出交集指标。交集指标优点是直观、可以与历史线上指标进行对比,缺点是交集量级很小时会导致统计指标无意义。
- X@N:
另一种指标我们称之为X@N,他由P@N演变而来,与交集不同的是,我们使用20200101这天“XX游戏”所有曝光人群,先用预测概率对人群倒排,然后通过分位数(N表示分位数节点)将此人群分为若干段,最后我们可以统计出每段的曝光、点击、下载、注册、付费、ctr、dtr、转化率等指标(X的含义),其指导意义是业务指标与预测分数应该呈单调递增关系,优点是量级足够,缺点是无法与历史线上指标对比。
除了考虑业务场景,我们也要考虑数据集分布发生变化的情况。例如当label分布发生变化后(尝试不同种子和负样本时),aupr往往不具有指导意义了,而X@N和交集指标仍可使用,因为它们使用的数据是历史线上数据,这个是不会变的。所以我们需要注意的是,模型内在指标的对比需要在测试集分布不变的条件下进行,比如增减特征、调参、调整训练集正负比例。
2. 算法
“没有免费午餐”定理(No Free Lunch,NFL)表示没有一种算法是适用所有情况的,选择什么样的算法要结合实际情况[2],但NFL主要针对“算法效果”谈“适用”,到了实际项目中我们应该综合“算法落地”与“算法效果”谈“适用”。
例如某算法在实验阶段表现非常好,但现阶段却无法将其应用到项目流程中(可能是不支持跨平台或性能问题),这种无法落地就是明显的不适用了,又比如A、B两种算法都可落地,A简单迅速B复杂耗时,但B带来的增益却很小,这种情况下B也是不适用的。
综上考虑,我们LookAlike项目决定在现阶段使用Logistic Regression,LR效果可接受、计算量小、资源开销小、模型解释性强且易于并行化,适合大数据、高维度场景。接下来本文将介绍LR实操中需要注意的一些问题。
2.1 特征处理
LR对特征工程要求较高,在特征处理环节有一步比较关键——将连续值离散化和one-hot编码,在LookAlike项目中采用离散化和one-hot编码后,特征数据内存开销和训练时间明显下降,aupr也显著提升。其原因如下:
- one-hot将数据稀疏化,稀疏存储更节约内存,稀疏向量内积速度快。
- 对连续值进行离散化可减少异常值的干扰,增加模型鲁棒性。进一步对离散数据one-hot编码是因为可将单个变量的N个离散值变成N维特征,每个特征独享权重,提升模型非线性能力。
2.2 超参
LR超参较少,除了推荐正则化方式一般情况采用elastic>L1>L2('>'表示优于)外,确实也没有什么值得介绍的了,但我们在使用sklearn和sparkML的LR时,发现用相同数据得到了不同模型,所以本节将重点介绍这两个平台一些重要超参的区别,以及如何操作来保证各平台模型一致。
设定双方平台都使用L2正则化,optimizer选择L-BFGS,笔者梳理了两平台间的一些区别:
2.2.1 目标函数差异
如下图公式所示,sklearn和spark的目标函数是n倍关系(n表示样本数),因为目标函数n倍关系并不影响最优化结果,所以我们只用保持正则化因子关系为λ= 1/(nC)就可以了。
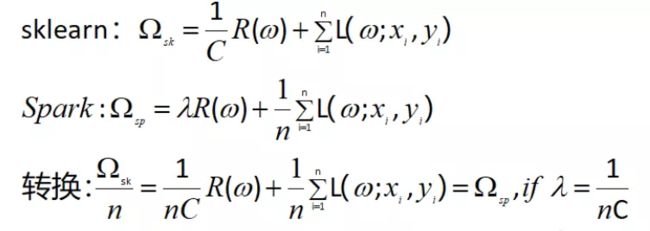
2.2.2 数据标准化差异
sklearn默认是没有对数据进行标准化,而spark默认在算法内部对数据进行标准化,甚至标准化的方式还会存在略微差异,下面以stackoverflow上的例子[3]进行扩展实验:
Python:
import numpy as np
from sklearn.linear_model import LogisticRegression, Ridge
from sklearn.preprocessing import StandardScaler
X = np.array([
[-0.7306653538519616, 0.0],[0.6750417712898752, -0.4232874171873786],[0.1863463229359709, -0.8163423997075965],
[-0.6719842051493347, 0.0],[0.9699938346531928, 0.0],[0.22759406190283604, 0.0],[0.9688721028330911, 0.0],
[0.5993795346650845, 0.0], [0.9219423508390701, -0.8972778242305388], [0.7006904841584055, -0.5607635619919824]])
y = np.array([0.0,1.0,1.0,0.0,1.0,1.0,1.0,0.0,0.0,0.0])
## sqrt(n-1)/sqrt(n) factor for getting the same standardization as spark
Xsc=StandardScaler().fit_transform(X)*3.0/np.sqrt(10.0)
l = 0.3
e = LogisticRegression(
fit_intercept=True,
penalty='l2',
C=1/l,
max_iter=100,
tol=1e-11,
solver='lbfgs',verbose=1)
e.fit(Xsc, y)
print e.coef_, e.intercept_SparkML:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.regression.LinearRegression
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.StandardScaler
val sparkTrainingData_orig = new SQLContext(sc).
createDataFrame(Seq(
(0.0, Vectors.dense(Array(-0.7306653538519616, 0.0))),
(1.0, Vectors.dense(Array(0.6750417712898752, -0.4232874171873786))),
(1.0, Vectors.dense(Array(0.1863463229359709, -0.8163423997075965))),
(0.0, Vectors.dense(Array(-0.6719842051493347, 0.0))),
(1.0, Vectors.dense(Array(0.9699938346531928, 0.0))),
(1.0, Vectors.dense(Array(0.22759406190283604, 0.0))),
(1.0, Vectors.dense(Array(0.9688721028330911, 0.0))),
(0.0, Vectors.dense(Array(0.5993795346650845, 0.0))),
(0.0, Vectors.dense(Array(0.9219423508390701, -0.8972778242305388))),
(0.0, Vectors.dense(Array(0.7006904841584055, -0.5607635619919824))))).
toDF("label", "features_orig")
val sparkTrainingData=new StandardScaler().
setWithMean(true).
setInputCol("features_orig").
setOutputCol("features").
fit(sparkTrainingData_orig).
transform(sparkTrainingData_orig)
//Make regularization 0.3/10=0.03
val logisticModel = new LogisticRegression().
setRegParam(0.03).
setLabelCol("label").
setFeaturesCol("features").
setTol(1e-12).
setMaxIter(100).
fit(sparkTrainingData)
println(s"Spark logistic model coefficients: ${logisticModel.coefficients} Intercept: ${logisticModel.intercept}")我们在上图例子中增加了数据标准化交叉实验来验证各标准化操作是否一致。
如下表所示:当双方都不做标准化时,参数与截距都可保持一致,当双方都做标准化时且sparkML在预处理阶段做标准化,双方参数才会保持一致(截距不同)。
| 注:训练阶段都考虑截距,L2惩罚因子已做转换 | sklearn不使用标准化 | sklearn使用标准化 |
|---|---|---|
| spark不使用标准化 | 参数相等、截距相等 | 参数不等、截距不等 |
| spark预处理使用标准化,算法内部也使用 | 参数不等、截距不等 | 参数相等、截距不等 |
| spark预处理使用标准化,算法内部不使用 | 参数不等、截距不等 | 参数相等、截距不等 |
| spark预处理不使用标准化,算法内部使用 | 参数不等、截距不等 | 参数不等、截距不等 |
2.2.3 tol使用方式差异和L-BFGS中海森矩阵的逆存在差异
tol用来作为optimizer的收敛条件,在sklearn中tol只作用于梯度,即只用于判别梯度是否收敛,而判断目标函数是否收敛的ftol使用默认值,用户是无法调整的,而spark中的tol同时控制着梯度和函数的收敛。
L-BFGS使用最近m个数据来近似海森矩阵的逆,sklearn和spark的m取值不一样,分别为10和7,该参数也没有开放给用户。
所以我们需要考虑收敛条件差异和海森矩阵逆的差异是否会对模型产生显著影响,从前面的例子来看是没有影响的,但前面例子毕竟数据集简单,迭代次数少(6~8次迭代),接下来使用部分criteo样本进行测试:训练集样本360万、特征100万维,根据上面的实验结果,采取都不标准化的策略。
如下表所示,我们只截取前10维参数,可以看到800次迭代后,双方参数没有出现显著差异。
| train_size:360万X100万迭代次数:800 | w1 | w2 | w3 | w4 | w5 | w6 |
|---|---|---|---|---|---|---|
| sklearn | 0.0000 | 0.0668 | 0.0123 | 0.1432 | 0.0000 | 0.0070 |
| spark | 0.0000 | 0.0687 | 0.0131 | 0.1505 | 0.0000 | 0.0079 |
综上所述,当我们使用不同平台建立LR模型时,应该认识到其中标准化与惩罚因子存在差异。
2.3 模型解释
LR模型可解释性很强,把模型参数倒排后,特征重要性一目了然。但在实际项目中把这些对应特征的覆盖量也考虑进去,就会发现排在前面的特征往往覆盖量很小,这其实是遇到了small-sample bias(小样本偏差)问题,且该问题是由其最大似然估计导致的[4]。
下面举一个极端的例子来理解上述问题,假设特征xj的覆盖量如下表:
| 离散+one-hot后特征都被01化 | xj=0覆盖量 | xj=1覆盖量 | 样本总数 |
|---|---|---|---|
| 正样本(y=1) | 99 | 1 | 100 |
| 负样本(y=-1) | 10000 | 0 | 10000 |
| xj总覆盖量 | 10099 | 1 |
接下来用最大似然构建目标函数,然后用梯度下降来更新模型参数,其公式如下:
$$ w_j:=w_j-\alpha {1\over m}\sum^m_{i=1}(h(x^{(i)})-y^{(i)})x_j^{(i)} \Rightarrow w_j:=w_j-\alpha (h(x^{(k)})-1)$$
综上,我们可以得到$x_j$只有在一个正样本中为1,即y=1,$x_j$=1, 其他情况下$x_j$=0。所以上式等价为$w_j:=w_j-\alpha (h(x^{(k)})-1)$,即只有$x_j$=1的样本起作用,又因为h(x)是sigmoid函数,其值域|h(x)|<1,所以$w_j$每次迭代都只会朝一个方向前进,最终导致他们的权重比较大。
所以我们在解释模型的时候不能单纯的看参数排序,还需要结合特征的覆盖量综合考虑。
3. 总结
本文从实际项目出发,对机器学习实操经验做了一次梳理,其中包括样本工程、特征工程、评估指标的选择、超参和模型解释,由于笔者知识储备有限,对有些问题理解可能比较片面甚至有误,还请读者海涵并给予斧正。
4 参考文献
1.https://www.jianshu.com/p/c79...
2.https://blog.csdn.net/qq_2873...
3.https://stackoverflow.com/que...
4.https://statisticalhorizons.c...
