MySQL Optimizer的子查询优化行为
MySQL Optimizer
先谈谈Optimizer。
Optimizer即数据库优化器,在MySQL中大家普遍称之为查询优化器。在任何一款数据库中,Optimizer一直占据着最为核心的角色,有些人将它比喻为数据库的大脑,真是太贴切了,因为从一定程度上来讲优化器的设计原则决定着一款数据库的行为。那么优化的前提是了解优化器,优化的作用是辅助优化器
MySQL Optimizer属于CBO,并且在不断地改进中已经渐渐开始支持各种主流的优化技术,在生成执行计划之前进行部分优化工作。mySQL中的SQL处理过程大致如下,
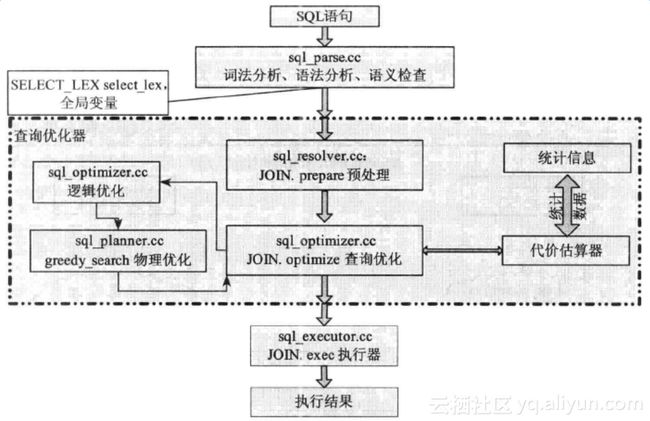
语法分析器处理的结果是将SQL语句解析为查询树(select_lex),优化器以JOIN::prepare方法作为入口,最终将语法树转变为最优的执行计划。期间交错进行着逻辑优化与物理优化,各个组件及数据结构彼此配合,共同完成查询优化以及执行计划生成这一个完整的工作流程。
再来说一下逻辑优化与物理优化。
逻辑优化,主要功能是基于关系代数以及启发式规则,找出SQL语句等价的变换形式,使得SQL执行更高效;物理优化,即根据代价估算模型,选择最优的表连接顺序以及数据访问方式,这个阶段依赖于对数据的了解。
从我们的角度来看,逻辑优化就是优化器对我们的SQL进行了一次改进优化,那么优化器就不单单只是简单地解析SQL,为了让生活更美好,它会选择自己更乐意接受的语法形式
子查询优化技术
在逻辑优化阶段,其中一个核心工作就是进行子查询的优化,因为子查询实在是太消耗性能了,MySQL查询优化器在演进历程中渐渐支持了子查询的优化,这还是相当有必要的。在MySQL Optimizer中,子查询的处理贯穿在整个优化器代码中,
在JOIN::prepare查询准备阶段就进行了一部分特殊子查询的优化,如
remove_redundant_subquery_clauses //去冗余子句
resolve_subquery //简单格式的semi-join优化,否则调用select_transformer
select_transformer //其他类型子查询优化,如IN/ALL/ANY等价转换JOIN::optimize方法中,融合了semi-join、Materialization以及EXISTS strategy这三种主要的优化策略,如
flatten_subqueries //子查询展开,即子查询上拉,无法上拉则使用EXISTS strategy方式
make_join_statistics //完成多表连接,此函数会进行嵌套连接的Materialization优化,并确定子查询的优化策略子查询优化的主流技术有三种:
子查询合并。即把多个子查询合并成一个子查询,作用是减少元组扫描的次数
子查询反嵌套。也称作子查询上拉,即将子查询重写为等价的多表连接
聚集子查询消除。即聚集函数上推,将消除聚集函数的子查询与父查询做外连接
其中,子查询反嵌套是一种最常用的子查询优化技术,同时MySQL中也只支持这种优化技术。MySQL 5.6中处理子查询的思路是,基于查询重写技术的规则,尽可能将子查询转换为连接(semi-join Semi-Join Transformations),并配合基于代价估算的Materialize、exists 等优化策略让子查询执行更优
接下来会对各种技术以及实现场景进行测试验证,测试用表如下,
[root@sakila 11:49:54]> desc customer_t;
+-------------+----------------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------------------+------+-----+-------------------+-----------------------------+
| | smallint(5) unsigned | NO | PRI | NULL | |
...
...
9 rows in set (0.07 sec)
[root@sakila 02:38:29]> desc payment_t;
+--------------+----------------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+----------------------+------+-----+-------------------+-----------------------------+
| payment_id | smallint(5) unsigned | NO | PRI | NULL | |
| | smallint(5) unsigned | NO | MUL | NULL | |
...
...
7 rows in set (0.00 sec)不支持的优化技术
1、子查询合并技术
对于两个相似的子查询作为where条件的查询,MySQL不支持合并处理。如下,
[root@sakila 05:00:22]> explain extended select customer_t.store_id from customer_t where customer_id in (select customer_id from payment_t where payment_id>1000) or customer_id in (select customer_id from payment_t where payment_id<10);
+----+-------------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | PRIMARY | customer_t | ALL | NULL | NULL | NULL | NULL | 644 | 100.00 | Using where |
| 3 | SUBQUERY | payment_t | range | PRIMARY | PRIMARY | 2 | NULL | 9 | 100.00 | Using where |
| 2 | SUBQUERY | payment_t | range | PRIMARY | PRIMARY | 2 | NULL | 8272 | 100.00 | Using where |
+----+-------------+------------+-------+---------------+---------+---------+------+------+----------+-------------+改写后的SQL语句如下,
/* select#1 */ select `sakila`.`customer_t`.`store_id` AS `store_id` from `sakila`.`customer_t` where ((`sakila`.`customer_t`.`customer_id`,`sakila`.`customer_t`.`customer_id` in ( (/* select#2 */ select `sakila`.`payment_t`.`customer_id` from `sakila`.`payment_t` where (`sakila`.`payment_t`.`payment_id` > 1000) ), (`sakila`.`customer_t`.`customer_id` in on where ((`sakila`.`customer_t`.`customer_id` = `materialized-subquery`.`customer_id`))))) or (`sakila`.`customer_t`.`customer_id`,`sakila`.`customer_t`.`customer_id` in ( (/* select#3 */ select `sakila`.`payment_t`.`customer_id` from `sakila`.`payment_t` where (`sakila`.`payment_t`.`payment_id` < 10) ), (`sakila`.`customer_t`.`customer_id` in on where ((`sakila`.`customer_t`.`customer_id` = `materialized-subquery`.`customer_id`))))))
从转换结果来看,优化器使用了多种优化策略来获得更快的元组扫描速率,但是两个子查询仍然单独进行,表payment_t被扫描了两次,而没有将两个子查询进行合并处理
2、聚集子查询消除。
子查询包含聚集函数,MySQL不支持消除,如下,
[root@sakila 09:38:54]> explain extended select * from customer_t where customer_id in (select min(customer_id) from payment_t);
+----+-------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| 1 | PRIMARY | customer_t | ALL | NULL | NULL | NULL | NULL | 644 | 100.00 | Using where |
| 2 | SUBQUERY | payment_t | ALL | NULL | NULL | NULL | NULL | 15448 | 100.00 | NULL |
+----+-------------+------------+------+---------------+------+---------+------+-------+----------+-------------+优化后语句如下,
/* select#1 */ select `sakila`.`customer_t`.`customer_id` AS `customer_id`,`sakila`.`customer_t`.`store_id` AS `store_id`,`sakila`.`customer_t`.`first_name` AS `first_name`,`sakila`.`customer_t`.`last_name` AS `last_name`,`sakila`.`customer_t`.`email` AS `email`,`sakila`.`customer_t`.`address_id` AS `address_id`,`sakila`.`customer_t`.`active` AS `active`,`sakila`.`customer_t`.`create_date` AS `create_date`,`sakila`.`customer_t`.`last_update` AS `last_update` from `sakila`.`customer_t` where (`sakila`.`customer_t`.`customer_id`,`sakila`.`customer_t`.`customer_id` in ( (/* select#2 */ select min(`sakila`.`payment_t`.`customer_id`) from `sakila`.`payment_t` having 1 ), (`sakila`.`customer_t`.`customer_id` in on where ((`sakila`.`customer_t`.`customer_id` = `materialized-subquery`.`min(customer_id)`))))) 可以发现被优化后的查询仍然有子查询,select_type值为SUBQUERY,这里用到了materialize、auto_key等各种优化手段,但是没有实现聚集子查询消除
特殊类型子查询的优化
1.IN类型。
MySQL支持简单in查询的优化,主要策略为semi-join、Materialization,否则会使用EXISTS strategy优化。这里用两个测试场景来分析优化行为,
场景一:... out_expr in (select primary_key ... )
[root@sakila 08:30:46]> explain extended select * from payment_t where customer_id in (select customer_id from customer_t);
+----+-------------+------------+--------+---------------+---------+---------+------------------------------+-------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+--------+---------------+---------+---------+------------------------------+-------+----------+-------------+
| 1 | SIMPLE | payment_t | ALL | NULL | NULL | NULL | NULL | 15448 | 100.00 | NULL |
| 1 | SIMPLE | customer_t | eq_ref | PRIMARY | PRIMARY | 2 | sakila.payment_t.customer_id | 1 | 100.00 | Using index |
+----+-------------+------------+--------+---------------+---------+---------+------------------------------+-------+----------+-------------+ /* select#1 */ select `sakila`.`payment_t`.`payment_id` AS `payment_id`,`sakila`.`payment_t`.`customer_id` AS `customer_id`,`sakila`.`payment_t`.`staff_id` AS `staff_id`,`sakila`.`payment_t`.`rental_id` AS `rental_id`,`sakila`.`payment_t`.`amount` AS `amount`,`sakila`.`payment_t`.`payment_date` AS `payment_date`,`sakila`.`payment_t`.`last_update` AS `last_update` from `sakila`.`customer_t` join `sakila`.`payment_t` where (`sakila`.`customer_t`.`customer_id` = `sakila`.`payment_t`.`customer_id`)场景二:... primary_key in (select inner_expr ... )
[root@sakila 08:30:21]> explain extended select * from customer_t where customer_id in (select customer_id from payment_t);
+----+--------------+-------------+--------+---------------+------------+---------+-------------------------------+-------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+-------------+--------+---------------+------------+---------+-------------------------------+-------+----------+-------------+
| 1 | SIMPLE | customer_t | ALL | PRIMARY | NULL | NULL | NULL | 644 | 100.00 | Using where |
| 1 | SIMPLE | | eq_ref | | | 2 | sakila.customer_t.customer_id | 1 | 100.00 | NULL |
| 2 | MATERIALIZED | payment_t | ALL | NULL | NULL | NULL | NULL | 15448 | 100.00 | NULL |
+----+--------------+-------------+--------+---------------+------------+---------+-------------------------------+-------+----------+-------------+
转换后的语句如下,
/* select#1 */ select `sakila`.`customer_t`.`customer_id` AS `customer_id`,`sakila`.`customer_t`.`store_id` AS `store_id`,`sakila`.`customer_t`.`first_name` AS `first_name`,`sakila`.`customer_t`.`last_name` AS `last_name`,`sakila`.`customer_t`.`email` AS `email`,`sakila`.`customer_t`.`address_id` AS `address_id`,`sakila`.`customer_t`.`active` AS `active`,`sakila`.`customer_t`.`create_date` AS `create_date`,`sakila`.`customer_t`.`last_update` AS `last_update` from `sakila`.`customer_t` semi join (`sakila`.`payment_t`) where (``.`customer_id` = `sakila`.`customer_t`.`customer_id`) 这个语句和前面一个很类似,但是处理结果有一些区别。从执行计划看,好像还是有subquery,但是结合转换结果看,这种子查询被物化处理,然后进行了与外部表的semi join转换。
这两个语句的差别在哪里呢?
语句本身无差异,但是转换成join就会有很大区别,就是场景二的SQL转换为join之后还需要进行消重处理,这里的处理策略是物化为临时表,然后semi join消重。在这种场景下MySQL优化器还提供多种优化策略,如FirstMatch、LooseScan等,根据成本选择。
这两种场景都实现了MySQL的子查询反嵌套技术,只是在后一种场景下进行了更细致的处理,让SQL的处理消耗更少的资源。在MySQL中,与各种独特优化策略相结合的子查询上拉技术,被统称为Semi-Join Transformations。
2.ANY/ALL/SOME。
MySQL对于ANY/ALL/SOME类型的优化,主要策略是基于查询重写技术,将查询转换成更易被优化的min()/max(),= ANY则等价于in,= ALL一般会通过EXISTS strategy进行优化
场景一:outer_expr > ANY(select inner_expr ... )
[root@sakila 10:32:10]> explain extended select * from customer_t where customer_id > ANY(select customer_id from payment_t);
+----+-------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| 1 | PRIMARY | customer_t | ALL | NULL | NULL | NULL | NULL | 644 | 100.00 | Using where |
| 2 | SUBQUERY | payment_t | ALL | NULL | NULL | NULL | NULL | 15448 | 100.00 | NULL |
+----+-------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
转换后的语句如下,
/* select#1 */ select `sakila`.`customer_t`.`customer_id` AS `customer_id`,`sakila`.`customer_t`.`store_id` AS `store_id`,`sakila`.`customer_t`.`first_name` AS `first_name`,`sakila`.`customer_t`.`last_name` AS `last_name`,`sakila`.`customer_t`.`email` AS `email`,`sakila`.`customer_t`.`address_id` AS `address_id`,`sakila`.`customer_t`.`active` AS `active`,`sakila`.`customer_t`.`create_date` AS `create_date`,`sakila`.`customer_t`.`last_update` AS `last_update` from `sakila`.`customer_t` where ((`sakila`.`customer_t`.`customer_id` > (/* select#2 */ select min(`sakila`.`payment_t`.`customer_id`) from `sakila`.`payment_t`))) 从等价转换后的句式可以看到,子查询还是存在的,但是ANY被转换为>min()。那么这种转换的意义在哪里呢?
现在对payment_t表添加一个索引:alter table payment_t add key(customer_id),然后再看看这条查询的执行计划
[root@sakila 12:02:16]> explain extended select * from customer_t where customer_id > ANY(select customer_id from payment_t);
+----+-------------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------+---------------+------+---------+------+------+----------+------------------------------+
| 1 | PRIMARY | customer_t | ALL | NULL | NULL | NULL | NULL | 644 | 100.00 | Using where |
| 2 | SUBQUERY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+------------+------+---------------+------+---------+------+------+----------+------------------------------+可以发现,在customer_id字段添加了索引之后,优化器直接通过索引获取min(),Extra信息为Select tables optimized away。那么优化器的转换思路就是,朝更容易被使用索引进行物理优化的方向进行改写。
场景二:... outer_expr < ALL(select inner_expr ... )
[root@sakila 12:02:21]> explain extended select * from customer_t where customer_id < ALL(select customer_id from payment_t);
转换后的语句如下,
/* select#1 */ select `sakila`.`customer_t`.`customer_id` AS `customer_id`,`sakila`.`customer_t`.`store_id` AS `store_id`,`sakila`.`customer_t`.`first_name` AS `first_name`,`sakila`.`customer_t`.`last_name` AS `last_name`,`sakila`.`customer_t`.`email` AS `email`,`sakila`.`customer_t`.`address_id` AS `address_id`,`sakila`.`customer_t`.`active` AS `active`,`sakila`.`customer_t`.`create_date` AS `create_date`,`sakila`.`customer_t`.`last_update` AS `last_update` from `sakila`.`customer_t` where ((`sakila`.`customer_t`.`customer_id` >= (/* select#2 */ select min(`sakila`.`payment_t`.`customer_id`) from `sakila`.`payment_t`))) 场景三:... outer_expr = ANY(select inner_expr ... )
[root@sakila 12:06:15]> explain extended select * from customer_t where customer_id = ANY (select customer_id from payment_t);
+----+--------------+-------------+--------+---------------+------------+---------+-------------------------------+-------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+-------------+--------+---------------+------------+---------+-------------------------------+-------+----------+-------------+
| 1 | SIMPLE | customer_t | ALL | PRIMARY | NULL | NULL | NULL | 644 | 100.00 | Using where |
| 1 | SIMPLE | | eq_ref | | | 2 | sakila.customer_t.customer_id | 1 | 100.00 | NULL |
| 2 | MATERIALIZED | payment_t | ALL | NULL | NULL | NULL | NULL | 15448 | 100.00 | NULL |
+----+--------------+-------------+--------+---------------+------------+---------+-------------------------------+-------+----------+-------------+
转换后如下,
/* select#1 */ select `sakila`.`customer_t`.`customer_id` AS `customer_id`,`sakila`.`customer_t`.`store_id` AS `store_id`,`sakila`.`customer_t`.`first_name` AS `first_name`,`sakila`.`customer_t`.`last_name` AS `last_name`,`sakila`.`customer_t`.`email` AS `email`,`sakila`.`customer_t`.`address_id` AS `address_id`,`sakila`.`customer_t`.`active` AS `active`,`sakila`.`customer_t`.`create_date` AS `create_date`,`sakila`.`customer_t`.`last_update` AS `last_update` from `sakila`.`customer_t` semi join (`sakila`.`payment_t`) where (``.`customer_id` = `sakila`.`customer_t`.`customer_id`) 场景四:... outer_expr = ALL(select inner_expr ... )
[root@sakila 12:06:21]> explain extended select * from customer_t where customer_id = ALL (select customer_id from payment_t);
+----+--------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
| 1 | PRIMARY | customer_t | ALL | NULL | NULL | NULL | NULL | 644 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | payment_t | ALL | NULL | NULL | NULL | NULL | 15448 | 100.00 | Using where |
+----+--------------------+------------+------+---------------+------+---------+------+-------+----------+-------------+
转换后句式如下,
/* select#1 */ select `sakila`.`customer_t`.`customer_id` AS `customer_id`,`sakila`.`customer_t`.`store_id` AS `store_id`,`sakila`.`customer_t`.`first_name` AS `first_name`,`sakila`.`customer_t`.`last_name` AS `last_name`,`sakila`.`customer_t`.`email` AS `email`,`sakila`.`customer_t`.`address_id` AS `address_id`,`sakila`.`customer_t`.`active` AS `active`,`sakila`.`customer_t`.`create_date` AS `create_date`,`sakila`.`customer_t`.`last_update` AS `last_update` from `sakila`.`customer_t` where ((`sakila`.`customer_t`.`customer_id`,(/* select#2 */ select 1 from `sakila`.`payment_t` where ((`sakila`.`customer_t`.`customer_id`) <> `sakila`.`payment_t`.`customer_id`)))) 非特殊子查询
1.Derived Tables。
MySQL支持对派生表形式的子查询进行优化。
对于派生类子查询的处理,优化器进一步优化了Materialization策略,只有当派生表中的数据必须加载时才可能被物化;对于join派生表的子查询类型,MySQL Optimizer支持auto_key策略优化,该策略会在物化的子查询结果集上添加索引,从而加速访问效率。
模拟SQL场景如下,
[root@sakila 02:32:16]> explain extended select customer_t.customer_id,derived_t.payment_id from customer_t join (select * from payment_t)
as derived_t on customer_t.customer_id=derived_t.customer_id where derived_t.customer_id <100;
+----+-------------+------------+-------+---------------+-------------+---------+-------------------------------+-------+----------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+-------+---------------+-------------+---------+-------------------------------+-------+----------+--------------------------+
| 1 | PRIMARY | customer_t | range | PRIMARY | PRIMARY | 2 | NULL | 98 | 100.00 | Using where; Using index |
| 1 | PRIMARY | | ref | | | 2 | sakila.customer_t.customer_id | 23 | 100.00 | NULL |
| 2 | DERIVED | payment_t | ALL | NULL | NULL | NULL | NULL | 15448 | 100.00 | NULL |
+----+-------------+------------+-------+---------------+-------------+---------+-------------------------------+-------+----------+--------------------------+
优化器转换后如下,
/* select#1 */ select `sakila`.`customer_t`.`customer_id` AS `customer_id`,`derived_t`.`payment_id` AS `payment_id` from `sakila`.`customer_t` join
(/* select#2 */ select `sakila`.`payment_t`.`payment_id` AS `payment_id`,`sakila`.`payment_t`.`customer_id` AS `customer_id`,
`sakila`.`payment_t`.`staff_id` AS `staff_id`,`sakila`.`payment_t`.`rental_id` AS `rental_id`,`sakila`.`payment_t`.`amount` AS `amount`,
`sakila`.`payment_t`.`payment_date` AS `payment_date`,`sakila`.`payment_t`.`last_update` AS `last_update` from `sakila`.`payment_t`) `derived_t`
where ((`derived_t`.`customer_id` = `sakila`.`customer_t`.`customer_id`) and (`sakila`.`customer_t`.`customer_id` < 100)) 2.其他复杂子查询
MySQL Optimizer对具有UNION、ORDER BY ...LIMIT、GROUP BY等操作的子查询支持的也不是很好。大家可以找几个复杂的例子做下测试。
另外,对于NULL值的忠告,当一个涉及多表操作的子查询的外部表达式包含NULL值时(如NULL in (select inner_expe ...)),NULL值将会在join optimizer中进行单独处理,无法享受到优化待遇,大量NULL值可能会带来严重的性能问题。
辅助优化策略
知道了优化器怎么做,我们才知道如何让它更好的工作,那么想要构造高性能的子查询,使用策略主要是以下几点,
1、NOT NULL约束。不管是否为子查询,NULL值得处理都会是一个棘手的问题
2、建立合适的索引。优化器总是朝更容易利用索引进行优化的方向进行转换
3、多用连接而不是子查询。优化器处理子查询总是想方设法的将它转换为join,看来join才是他更喜欢的形式
4、不要太复杂。要知道,目前的MySQL查询优化器对复杂查询的优化支持的并不好