谈谈软件行业普遍存在的`立即数`和`引用数`
事情是这样的, 最近没事玩玩前端的polyfill, 就是填充浏览器的标准库, 之前写了几篇, 比如
Fuck标准库系列: location.parameter
整个url中从左到右分别是: 协议, 主机名, 域名, 端口号, 路径, 查询参数, 于是window.location对象有:
- location.href
- location.protocol
- location.host
- location.port
- location.pathname
但是唯独缺少了最后面的查询参数, 于是我们封装一下吧, 通过location.href后面分割"?", "&", 以及"="字符来把键值对封装成一个js对象, 于是我写了一句话代码:
location.param = (decodeURIComponent(location.href).split('?')[1] || '')
.split('&')
.map(p => p.split('='))
.reduce(
(p, [key, value]) => (key ? Object.assign(p, { [key]: value }) : p),
{},
);测试一下, 打开 https://www.baidu.com/s?ie=UTF-8&wd=JavaScript , 输入以上代码, 然后打印location.parameter:
location.parameter;
> {ie: "UTF-8", wd: "JavaScript"}
嗯, 效果不错, 没啥技术含量, 只是用到MapReduce有点绕, 仔细看看就能明白.
反正才写了一点点, 就扯点别的吧, 打发下时间.
`立即数`和引用的普世思想
上面提到的url参数是在url中寄存了一些轻量的数据, 而不是将数据放在请求返回的结果中, 这2种数据存放方式有一个很经典的区别: 前者是"立即数", 后者是引用. 立即数是直接存放在地址中的数据, 而引用是需要通过地址, 经过一次查找后才能得到的数据.
这看上去很明显啊? 为啥非要写出来呢? 因为这种现象在软件行业非常常见, 上升到一个普遍适用的哲学地位. 下面举几个例子:
有请求的url和无请求的url
以一个图片url为例, 通常都是通过一个图片地址比如https://example.com/test.png来获取图片, 但如果图片很小, 就可以直接将图片的数据信息放在url中, 比如复制下面这个url会在浏览器中打开一张svg图片, 但没有发送任何请求:
data:image/svg+xml;utf8,截图:

同理, 各种mime类型都可以通过data:协议来实现无请求的url, 或者"立即得到"的媒体
粘贴板
电脑的粘贴板一般只能存放一种类型的数据,比如一段文本,一张图片,但如果你尝试复制一个文件或者很大的一张图片,粘贴板中的内容将不再是文件本身而变成一份引用,文件移除后引用将失效,对吧?
软链接文件和硬链接文件
我们知道文件系统都有文件名与数据,这在 Linux 上被分成两个部分:用户数据 (user data) 与元数据 (metadata)。用户数据即文件数据块 (data block),是记录文件真实内容的地方;而元数据则是文件的附加属性,如文件大小、创建时间、所有者等信息。在 Linux 中,元数据中的 inode 号(inode 是文件元数据的一部分但其并不包含文件名,inode 号即索引节点号)才是文件的唯一标识而非文件名。文件名仅是为了方便人们的记忆和使用,系统或程序通过 inode 号寻找正确的文件数据块。下图展示了程序通过文件名获取文件内容的过程。
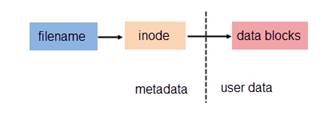
可以类比面向对象语言中变量与对象之间的关系: 变量是对对象的引用, 用户只能通过变量来和暗箱中的对象打交道. 这里元数据就是变量, 数据块就是对象. 我们日常接触的每一个文件都分成这2个部分, 元数据和数据块一一对应才有意义, 那有没有这样一个很小的文件, 它只有元数据(文件头), 没有文件块呢? 还真有, 这就是硬链接文件.
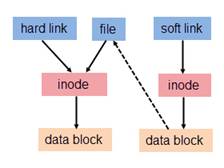
为解决文件的共享使用,Linux 系统引入了两种链接:硬链接 (hard link) 与软链接(又称符号链接,即 soft link 或 symbolic link)。链接为 Linux 系统解决了文件的共享使用,还带来了隐藏文件路径、增加权限安全及节省存储等好处。若一个 inode 号对应多个文件名,则称这些文件为硬链接。换言之,硬链接就是同一个文件使用了多个别名.
软链接与硬链接不同,若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接。软链接就是一个普通文件,只是数据块内容有点特殊。软链接有着自己的 inode 号以及用户数据块。因此软链接的创建与使用没有类似硬链接的诸多限制.
举个通俗的例子, 你创建一个txt文档, 打开在里面写上: "file:////Users/test/hello.png", 保存关闭, 然后重新命名为hello.png.softlink, 再写一个简单的程序向OS注册.softlink的文件打开方式, 读取其中的文本内容后调用系统的默认打开方式打开目标路径的文件, 这样一个软链接系统就完成了.
下图说明了软链接和硬链接的区别:
变量和对象
这个不再陌生了, 基础数据类型和引用数据类型的最大区别就是前者将数据直接存放在栈空间中, 特点是查找速度快, 后者通过栈空间的引用定位到堆空间的数据, 特点是数据容量大. 这种模式和文件系统很像: 使用栈空间来节省成本, 提高查询速度; 使用堆空间来提高系统灵活度, 为数据共享提供可能.
我们的认知过程大致是先意识到栈空间的存储能力, 再意识到可以把较大的数据存放到堆中; 但真实的发展模式是, 将所有数据存在堆中, 通过变量栈暴露给用户一个索引, 之后优化的时候再将一些比较轻巧的数据比如数字, 字符和boolean直接存到变量中.
CPU的立即寻址和直接寻址
CPU的设计也遵守着堆栈的思想.
cpu的寻址方式就是处理器根据指令中给出的地址信息来寻找有效地址的方式,现在情况很鲜明了, CPU每次得到的这几个字节即有可能是相关数据的地址(即直接寻址), 也有可能是数据地址的地址(即间接寻址), 还有可能就是数据本身(即立即寻址). 如果非要和文件系统的操作做一个对照的话:
- 立即寻址 ---> 删除一个硬链接文件
- 直接寻址 ---> 读取一个普通文件
- 间接寻址 ---> 读取一个软链接文件
完.
