自然语言处理(2)——文档相似度计算
上一篇讲了如何利用ICTCLAS分词工具进行分词,这一次讲一下文本相似度计算,从字面上理解就是比较两个文本之间的相似性。在文本分类和聚类中都会用到文本相似度的计算。
1.VSM
在讲文本相似度之前,先讲一下VSM即向量空间模型,该模型将文档映射到向量空间中。假设文档用![]() 表示文档集中D中的第i个文本,则
表示文档集中D中的第i个文本,则![]() 可以表示为:
可以表示为:
![]()
其中 可以有两种表达方式
(1)布尔类型表达,用0或1表示该词条是否在![]() 中出现,即该词出现则
中出现,即该词出现则![]() 为1,否则为0;
为1,否则为0;
(2)![]() 表示该词在
表示该词在![]() 中的权重,即
中的权重,即![]() ,N代表文档
,N代表文档![]() 中词的总数,
中词的总数,![]() 表示词j在文档
表示词j在文档![]() 中出现的次数。
中出现的次数。
举个例子:
![]() =小米 n 手机 n 4m 的 u 屏幕 n 太 d 给力 a 了 y , w 5m 英寸 q 的 u 高 a 色彩 n 饱和度 n 夏普 n wJ DI n 屏幕 n , w 1920x1080 n 全 d 高清 a 分辨率 n 。 w
=小米 n 手机 n 4m 的 u 屏幕 n 太 d 给力 a 了 y , w 5m 英寸 q 的 u 高 a 色彩 n 饱和度 n 夏普 n wJ DI n 屏幕 n , w 1920x1080 n 全 d 高清 a 分辨率 n 。 w
![]() =锤子 n 手机 n 终于 d 要 v 发货 v 了 y ! w 只 d 是 v 没 v 4Gn 的 u 机子 n , w 我 r 基本 a 不 d 要 v 了 y ! w 有 v 哪 r 位 q 同学 n 要 v 的 u , w 这 r 单子 n 给 p 你 r ! w 不 d 加收 v 任何 r 费用 n ! w
=锤子 n 手机 n 终于 d 要 v 发货 v 了 y ! w 只 d 是 v 没 v 4Gn 的 u 机子 n , w 我 r 基本 a 不 d 要 v 了 y ! w 有 v 哪 r 位 q 同学 n 要 v 的 u , w 这 r 单子 n 给 p 你 r ! w 不 d 加收 v 任何 r 费用 n ! w
过滤掉停用词后,则抽取出词袋<小米,手机,屏幕,太,给力,高,色彩,饱和度,完善,全,高清,分辨率,锤子,终于,要,发货,4G,机子,基本,同学,单子,加收,费用>。用VSM模型表示该文本,采用第1种布尔类型表达方式
![]()
![]()
2.文本相似度计算
本文采用余弦相似度来度量文本的相似度,该公式如下:
![]()
![]() 表示两个向量的内积,即假设两个向量为n维向量,则
表示两个向量的内积,即假设两个向量为n维向量,则
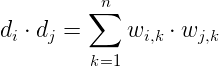
现在可以通过余弦相似度公式计算上述两个文档的相似度。
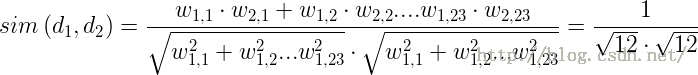
int foundWordBag(char *file,vector &vc_word){
ifstream ifs;
string word;
char mark;
int flag=0;
vector::iterator vc_ite;
ifs.open(file,ios::in);
while(!ifs.eof()){
ifs>>word>>mark;
if(mark=='n'||mark=='a'||mark=='d'||mark=='v'){
flag=0;
for(vc_ite=vc_word.begin();vc_ite!=vc_word.end();vc_ite++){
if(*vc_ite==word){
flag=1;
break;
}
}
if(flag==0)
vc_word.push_back(word);
}
}
ifs.close();
return 0;
} 第一个参数是所需要计算相似度的文本路径,其格式是在上一篇中讲的分词处理后的格式,第二个参数是一个string类型的vector容器,用于存放词袋的。
(2)构建VSM矩阵
int foundVSMMatrix(char *file,char *result,vector vc_word){
ifstream ifs;
ofstream ofs;
string words;
char mark;
vector::iterator ite;
int n=vc_word.size();
float *matrix=new float[n];
int i;
ifs.open(file,ios::in);
ofs.open(result,ios::ate);
for(i=0;i>words>>mark;
if(ifs.fail())
break;
if(mark!='l'){//文档结尾标记
if(mark=='n'||mark=='a'||mark=='d'||mark=='v'){
for(ite=vc_word.begin(),i=0;ite!=vc_word.end();ite++,i++)
if(*ite==words){
matrix[i]++;
}
}
}else if(mark=='l'){
for(i=0;i 第一个参数为文档分词处理文件路径,第二个参数是VSM矩阵存放的文件路径,第3个参数为词袋。
(3)计算相似度
float countSimilarity(int v,float d1[],float d2[]){
float sim;
float m=0;
float n1=0,n2=0;
int i;
for(i=0;i文档相似度计算就介绍到这里,感兴趣的同学可以自己做一个模型自己测试一下。