姐姐教你写脚本解析Map文件
本文首发于“嵌入式软件实战派”,作者实战派师姐,关注“嵌入式软件实战派”获得更多精品干货。
什么问题
小李,你算一下这个项目每个模块的资源使用情况,我明天早上要向客户汇报。
你老板这句话让你慌乱而不知所措?
别着急,其实可以从程序编译链接后生成的Map文件中提取相关数据。
本文,姐教你一步步解析Map文件,给老板一个漂亮的报告。
怎么统计这些资源呢?
上次,我讲了嵌入式程序员为什么要学脚本(见《“嵌入式开发学脚本干嘛”之进制/Byte/Hex处理》),我们这次也用Python脚本来解析Map文件并生成图表。本文会用到并简要讲解以下Python相关知识:
-
Python文件操作
-
Python字符串处理
-
Python的正则表达式使用
-
csv文件操作
-
Matplotlib图表生成
还没学会也没关系,只要把Python和相关库安装好,操起家伙直接实战吧。
什么是Map文件
首先要搞清楚什么是Map文件。
简单粗暴地理解:Map文件就是MCU程序的Map(地图)。
我们编写好的代码,通过编译链接一系列动作后,会生成一个elf格式的文件,IDE同时会从这个elf文件生成一个hex/s19或者bin文件,以供烧录到MCU里面去运行,同时(可配置地)生成一个叫Map的文件。
这个elf文件实际上就包含了程序的各种信息,包括函数名、变量名,地址、大小等等非常丰富的信息。而这个map文件就是从elf提出取来的,非常直观地(以文本形式)展现程序中的各文件包含了哪些函数变量,而这些函数变量分配在哪些段,地址是什么,以及其占用的空间大小等。
![]()
那么,我们是可以从这个map文件(当然也可以从elf文件)中提取很多有用的信息的哦。
以下,我以ghs编译器生成的Map文件(注意:每种IDE生成出来的Map文件格式可能会有点不一样)为例,讲解如何提取各文件或者模块占有的RAM/ROM资源。内容提取和解析的大概的过程如下:

如何解析Map
>>Map里面的基本信息
为了高效精准地讲解,以下截取了Map中部分内容,也是我们要解析的重点内容。
Image Summary Section Base Size(hex) Size(dec) SecOffs .intvect 00010000 00000174 372 00102c0 .except_table 00010200 00000598 1432 0010600 .rozdata 00010798 00000000 0 0000000 .robase 00010798 00000000 0 0000000 .rosdata 00010798 00000000 0 0000000 .rodata 00010798 0002678c 157580 0010b98 .text 00036f30 0008eb9c 584604 0037330 ... .data febd0000 00002890 10384 00c5fe8 .bss febd2890 00014080 82048 000000 ... .debug_info 00000000 00fc511c 16535836 00eb9e4 .debug_abbrev 00000000 00013789 79753 10b0b00 .debug_line 00000000 000773b5 488373 10c4289 .debug_macinfo 00000000 00c86d01 13135105 113b63e .debug_frame 00000000 00029780 169856 1dc233f
Image Summary下面的内容存放的是数据段的汇总大小,你看第一行Section Base Size(hex) Size(dec) SecOffs就是这些内容的标题说明。
例如,这个.text后面的数据就是这个.text段(一般来说是程序静态代码的存放段)的起始地址和大小,00036f30是base address,即存放起始位置,而0008eb9c是十六进制形式的size,即段所占大小。而后面的584604是十进制的大小,跟前面的size等价,我们可以不用管它,SecOffs也暂时不管它。
实际上,这个Image Summary包含了三类信息:
-
ROM字段数据;
-
RAM字段数据;
-
Debug数据。
以上,只有ROM和RAM的数据才是我们要关心的。
Module Summary Origin+Size Section Module 00036f30+000124 .text crt0.o 000370ba+000032 .text main.o 000107f8+00001c .rodata main.o 00000034+000018 .ghpepatch main.o 00001818+00454b .debug_info main.o 0000018b+0001a1 .debug_abbrev main.o 00000145+0002c2 .debug_line main.o 0000157e+0072e5 .debug_macinfo main.o 000000d0+0000b0 .debug_frame main.o 000370ec+0002d4 .text task.o febd28c8+000030 .bss task.o 00010814+0001a4 .rodata task.o 0000004c+00004c .ghpepatch task.o 00005d63+00831d .debug_info task.o 0000032c+0001d3 .debug_abbrev task.o 00000407+000516 .debug_line task.o 00008863+00903c .debug_macinfo task.o 00000180+000100 .debug_frame task.o ...
Module Summary是module里面的段的数据,这个module在本文说明的map文件中是指文件,例如task.o即task.c编译后的object文件名。
从上面的片段可以看出,一个文件包含了各个段信息,包括其占用的ROM和RAM的地址和大小。我们只需提取出这个文件中ROM和RAM占用的大小数据即可。
>>Map文件操作
既然Map文件没有固定的形式,那就直接当做文本操作吧。
Python的文件操作实际上跟C/C++的类似,但是语法上会巧妙点。
mf = open("mapfile.map",mode="r" )
# ...
mf.close()
这个open函数有很多个参数,大部分都有默认值,常用的只有两三个:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
-
file: 必需,文件路径(相对或者绝对路径)。
-
mode: 可选,文件打开模式,默认为t,即文本方式。例如mode='rb',表示binary read形式
-
buffering: 设置缓冲
-
encoding: 一般使用utf8
-
errors: 报错级别
-
newline: 区分换行符
-
closefd: 传入的file参数类型
-
...
另外,我们可以用with语句配合这个文件操作使用,这样可以省掉一个close操作,因为with在使用完文件操作后,自动调用close方法。
with open("mapfile.map",mode="r" ) as mf:
# ...
说到这,也许你会想,要是能一行一行处理多好,试试:
with open("./mapfile.map", "r") as mf:
for l in mf.readlines():
print(l)
一行一行的,就是字符串了,下面讲字符串的解析。
>>Map字符串解析
Python的字符串操作方法是非常丰富的。但是,我们要搞清楚我们这次实战的目的,有目的性地是使用字符串操作方法:
-
首先,一行字符串中有哪些信息?
-
你想从字符串中得到什么内容?
-
用什么方法提取你想要的内容?
通过以下字符串内容举例:“.text 00036f30 0008eb9c 584604 0037330“我想获取“.text”这个名称,还想获得它占用的空间大小“0008eb9c”丢弃其他内容。

好像很复杂的样子,别怕,有姐在,姐教你,嘻嘻……O(∩_∩)O。
此时此刻,“正则表达式”就呼之欲出了。
什么?正则表达式是什么东东?
如果你没接触过,我劝你不要对着这个名称苦思冥想,会走火入魔的,我以前就老是想为什么这些东西叫正则表达式,好像是很高深的学问,想多了。
不知道正则表达式,字符的通配符总听说过吧,例如型号*代表一个字符,不管是什么字符,AB*,可以表示ABC,也可以表示ABD等等。而这个正则表达式,有其一套完整的规则来“通配”某一类型的字符,举个例子,\d表示一个数字,\d+表示一串数字。
我们不在这里讲正则表达式的原理内容了,有兴趣可以网上搜“正则表达式”。我们这个例子会用到以下内容,会简单讲解其用法:
| 字符 | 描述 |
|---|---|
^ |
匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 |
$ |
匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
() |
标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \(和 \)。 |
* |
匹配前面的子表达式零次或多次。要匹配 * 字符,请使用\*。 |
+ |
匹配前面的子表达式一次或多次。要匹配 + 字符,请使用\+。 |
. |
匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用\. 。 |
? |
匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
[ |
标记一个中括号表达式的开始。要匹配 [,请使用\[。 |
那么,直接实战,来个例子:
“.text 00036f30 0008eb9c 584604 0037330“可以用以下正则表达式匹配
"^\s(.[.\w]+)\s+\w+\s+(\w+).$"
试下
import re
s = " .text 00036f30 0008eb9c 584604 0037330“
c = re.compile("^\s*(\.[\.\w]+)\s+\w+\s+(\w+).*$")
m = c.match(s)
if m: print(m.groups())
得到
('.text', '0008eb9c')
说明成功了。
那么,我们改进下,把段的大小字符串转成整型备用,并将段名和大小信息存在数组中:
import re
with open("./mapfile.map", "r") as mf:
section_info = []
for l in mf.readlines():
c = re.compile("^\s*(\.[\.\w]+)\s+\w+\s+(\w+).*$")
m = c.match(l)
if m:
section_info.append([m.group(1), int(m.group(2), 16)])
# print(m.groups())
print(section_info)
同理,Map文件中的“Module Summary”也可以通过这样的方法解析。
import re
with open("./mapfile.map", "r") as mf:
section_info = []
module_info = []
image_start = False
module_start = False
for l in mf.readlines():
if "Image Summary" in l:
image_start = True
elif "Module Summary" in l:
image_start = False
module_start = True
else:
if image_start:
# .text 00036f30 0008eb9c 584604 0037330
c = re.compile("^\s*(\.[\.\w]+)\s+\w+\s+(\w+).*$")
m = c.match(l)
if m:
section_info.append([m.group(1), int(m.group(2), 16)])
elif module_start:
# 000370ba+000032 .text main.o
c = re.compile("^\w+.*(\w+)\s+([\.\w]+)\s+([\w\.]+).*$")
m = c.match(l)
if m:
if not ".debug" in m.group(2):
module_info.append([m.group(3), m.group(2), int(m.group(1), 16)])
print(section_info)
print(module_info)
注意,在解析“Module Summary”时,我们把“.debug”相关信息丢弃了,这个信息对统计MCU内存资源没影响。讲到这里,基本需要的信息都提取完了,当然总不能甩给你老板两个数组,下面还有数据处理操作。
以下顺便简单解释下这个re的使用(学过或者不感兴趣的同学可以跳过)。
re即RegEx,Regular Expression的缩写,库的名称。
re有很多很好用的方法,我这里只用了其中几个。
"^\w+.*(\w+)\s+([\.\w]+)\s+([\w\.]+).*$"
这一串就是所谓的Pattern,里面的每个符合表达可以查看对照上表的解释说明。compile()函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 等函数使用。
match()函数,尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
而这个group的意思是:group(num=0),匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。groups(),返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
输出解析结果
基于上一小节, 我们已经提取出段(即RAM或ROM的段总体)的信息了,也获得了每个文件所含的段的相关数据。接下来要做的:
-
RAM和ROM各含有什么段名称;
-
每个.o文件应该归于哪一个Module;
对于第一点,这个需要查看具体项目的链接文件配置,如GHS工程的ld文件,另外可以看IC手册RAM和ROM的地址范围来区分。至于第二点,跟实际项目应用有关。例如,key_io.c、key_ad.c等可以归类为keyboard模块等。
这些归类的操作跟实际项目关系非常紧密,也不难,这里也不多说了。我们直接来看要输出什么样的结果吧。
-
输出表格,如Excel表格等。
我看到过,有好多人直接用Excel表格来统计资源的,大多是将原始Map文件内容复制或导入到Excel中,然后格式化其里面的内容,即将数据段里面的地址、大小等信息分别填到单独的单元格,然后通过公式统计出结果。也有部分人通过Excel的脚本vb来解析Map文件内容。
当然,你也可以将我们上一小节提取的结果(两个数组信息)复制到Excel中,然后再统计。
其实,都做到这一步的,没必要手动复制来复制去了,直接导出Excel表格内容不就行了。
有两种办法,一是用pandas库,二是输出csv文件。这里讲第二种。
输出csv非常简单,其实际上也是文件操作。以下仅举例说明:
import csv
section_info = [["ROM", ".text", 584604], ["ROM", ".rodata", 157580], ["RAM", ".data", 10384], ["RAM", ".bss", 82048]]
with open('mapinfo.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(['Memory', 'Section',, 'Size'])
for i in section_info:
row = [i[0], i[1], "%d"%(i[2]/1024)]
writer.writerow(row)
可以获得如下结果(用Excel打开csv文件):
![]()
-
输出饼图或者柱图。
为了结果好看点,我们做个图形化的结果。
import matplotlib.pyplot as plt
labels = ['Keyboard', 'System', 'Motor', 'Light', 'Others','Free']
sizes = [8, 20, 15, 12, 10, 35]
colors = ['olive', 'r', 'tomato', 'y','darkorange','g']
explode = (0,0, 0, 0, 0, 0.1)
plt.pie(sizes, explode=explode, autopct='%1.1f%%', labels = labels, colors = colors)
plt.title("ROM Usage")
plt.axis('equal')
plt.show()
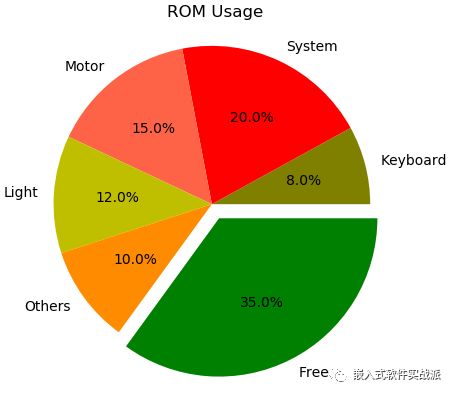
此处仅做示例,如果想要表达每个模块的具体数据,以及整体使用情况,也可以使用柱状图。
更多图形效果可参考Matplotlib官网(https://matplotlib.org/gallery/index.html),里面的例子也比较直观,很容易学习。
关注“嵌入式软件实战派”,获得更多脚本技巧。
