本科2019大数据应用大赛 可视化部分
近些年空气污染在我国很多地区非常严重,其中PM2.5作为衡量空气质量的一个重要指标,当前数据为2018年12月份1号-10号全国大部分城市的站点检测数据。接下来我们将这些数据进行可视化来看下PM2.5的分布情况。
需首先安装Python的numpy和matplotlib库
相关数据链接:百度网盘 提取码:mx4d
题目:
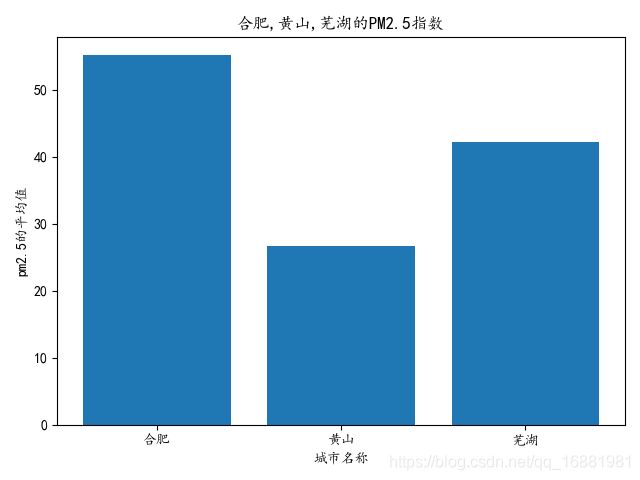
- 利用柱状图输出合肥、黄山、芜湖的PM2.5指数,Y轴表示PM2.5的平均数,X轴表示城市名称
要求:将输出的直方图保存成图像文件,程序源代码截图
代码文件:
import numpy as np
from matplotlib import pyplot as plt
txt=open("airpm25.txt", encoding='utf8')
a = np.loadtxt(txt, dtype=np.str, delimiter=',') # load 时也要指定为逗号分隔
didian = ['合肥','黄山','芜湖']
suju=[[],[]]
for dd in didian:
yao1 = np.where(a[...,2]==dd)#选择地点是合肥的数据
b = np.array(a[yao1][..., 1], dtype=np.int32)#将合肥的数据汇总成一个numpy数组,指定数据类型是数字
zhi = np.mean(b)#求平均值
suju[0].append(dd)
suju[1].append(zhi)
print(suju)
plt.bar(suju[0], suju[1]) # 传入x和y 通过plot绘制出折线图
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.title('{}的PM2.5指数'.format(",".join(didian)))
plt.xlabel('城市名称')
plt.ylabel('pm2.5的平均值')
plt.show() #展示图像
结果截图:
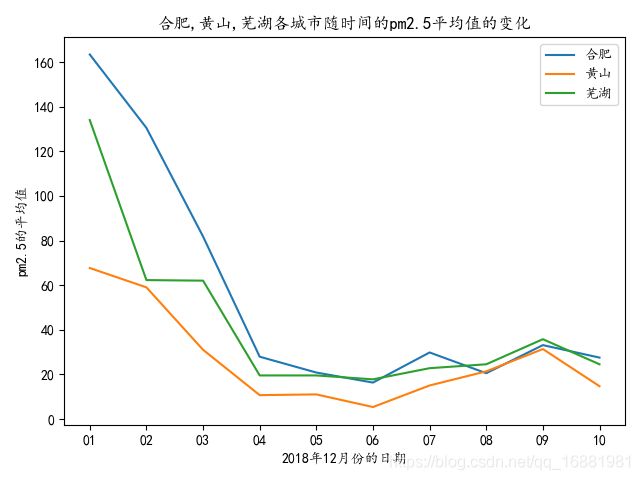
- 用折线图,画出合肥、黄山、芜湖各城市随时间的pm2.5平均值的变化要求将输出的折线图保存成图像文件,Y轴表示pm2.5的平均值,X轴表示日期
要求:折线图中含图例;不同的城市用不同的颜色表达;
代码文件:
import numpy as np
from matplotlib import pyplot as plt
txt=open("airpm25.txt", encoding='utf8')
a = np.loadtxt(txt, dtype=np.str, delimiter=',') # load 时也要指定为逗号分隔
didian = ["合肥","黄山","芜湖"]
suju=[]
for dd in didian:
yao1 = np.where(a[...,2]==dd)#选择地点是合肥的数据
shijian = np.unique(a[yao1][...,0])#将上述数据中的时间提取出来,并且去重,存入时间的列表
shijian_zhi =[]#用于记录这一个地点的数据
for x in np.nditer(shijian):
yao = np.where(a[yao1][...,0] == x)#从时间的列表中选择对应时间的数据,
b = np.array(a[yao1][yao][..., 1], dtype=np.int32)#将这一天所有的数据汇总成一个numpy数组,指定数据类型是数字
zhi = np.mean(b)#求平均值
shijian_zhi.append(zhi)
suju.append([shijian.tolist(),shijian_zhi])
print(suju)
def fx(x):
return x[-2:]
# x轴 y轴的数据一起组成了要绘制出的图形
for i in range(len(suju)):
plt.plot(list(map(fx, suju[i][0])), suju[i][1], label=didian[i]) # 传入x和y 通过plot绘制出折线图
plt.legend() # 显示上面的label
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.title('{}各城市随时间的pm2.5平均值的变化'.format(",".join(didian)))
plt.xlabel('2018年12月份的日期')
plt.ylabel('pm2.5的平均值')
plt.show() #展示图像
结果截图:
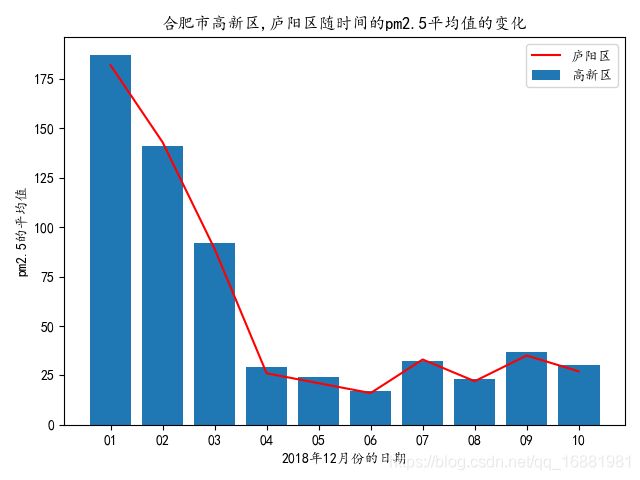
- 用柱线混合图形画出合肥市的高新区和庐阳区的pm2.5的值。要求将输出的折线图保存成图像文件,X轴表示时间,柱状表示高新区 的pm2.5的值,线形表示庐阳区的pm2.5的值。
要求: 图形中含有图例
代码文件:
import numpy as np
from matplotlib import pyplot as plt
txt=open("airpm25.txt", encoding='utf8')
a = np.loadtxt(txt, dtype=np.str, delimiter=',') # load 时也要指定为逗号分隔
juti = ["高新区","庐阳区"]
suju=[]
for dd in juti:
yao1 = np.where(a[...,2]=="合肥")#选择地点是合肥的数据
yao2 = np.where(a[yao1][...,3] == dd)
shijian = np.unique(a[yao1][yao2][...,0])#将上述数据中的时间提取出来,并且去重,存入时间的列表
shijian_zhi =[]#用于记录这一个地点的数据
for x in np.nditer(shijian):
yao = np.where(a[yao1][yao2][...,0] == x)#从时间的列表中选择对应时间的数据,
b = np.array(a[yao1][yao2][yao][..., 1], dtype=np.int32)#将这一天所有的数据汇总成一个numpy数组,指定数据类型是数字
zhi = np.mean(b)#求平均值
shijian_zhi.append(zhi)
suju.append([shijian.tolist(),shijian_zhi])
print(suju)
def fx(x):
return x[-2:]
# x轴 y轴的数据一起组成了要绘制出的图形
plt.plot(list(map(fx, suju[1][0])), suju[1][1],color = 'red', label=juti[1]) # 传入x和y 通过plot绘制出折线图
plt.bar(list(map(fx, suju[0][0])), suju[0][1], label=juti[0]) # 传入x和y 通过plot绘制出折线图
plt.legend() # 显示上面的label
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.title('合肥市{}随时间的pm2.5平均值的变化'.format(",".join(juti)))
plt.xlabel('2018年12月份的日期')
plt.ylabel('pm2.5的平均值')
plt.show() #展示图像
结果截图: